IO是操作系统中最重要的功能之一。说起IO,其实要从最开始的同步阻塞IO模型说起。
首先理解下同步和非同步,阻塞和非阻塞。
在Linux操作系统中,数据分为内核态和用户态。用户线程在用户态中运行,键盘,鼠标动作是由内核系统调用触发。
同步,异步
同步和非同步是从消息通信的角度来区分的。如果用户态中进程主动去到内核态中查询获取数据,这种就是同步机制。同步永远是进程主动去获取数据。如果数据可以通过通知的方法返回到用户进程,那么这种方式就是异步的。
阻塞,非阻塞
一个线程在运行期间,调用了其他方法,在该方法返回结果之前,如果此线程处于等待状态,那么这种就是阻塞的,如果方法立即返回一个结果(即使这个结果没有任何业务意义),调用该方法的线程转而去做了其他事情。那么这种方式就是非阻塞的。这个时候如果我们需要去获取该方法的真实返回结果,就需要采用同步的方式去获取(这里又是从消息的通知方式来说的)。
三种常见的IO模型
1. 阻塞式IO
阻塞式IO最开始接触多线程编程时候入门的线程模型。一个线程在未得到另一个方法的返回值之前,需要一直挂起,知道方法返回数据后,才可以重新拿到时间片,继续运行。
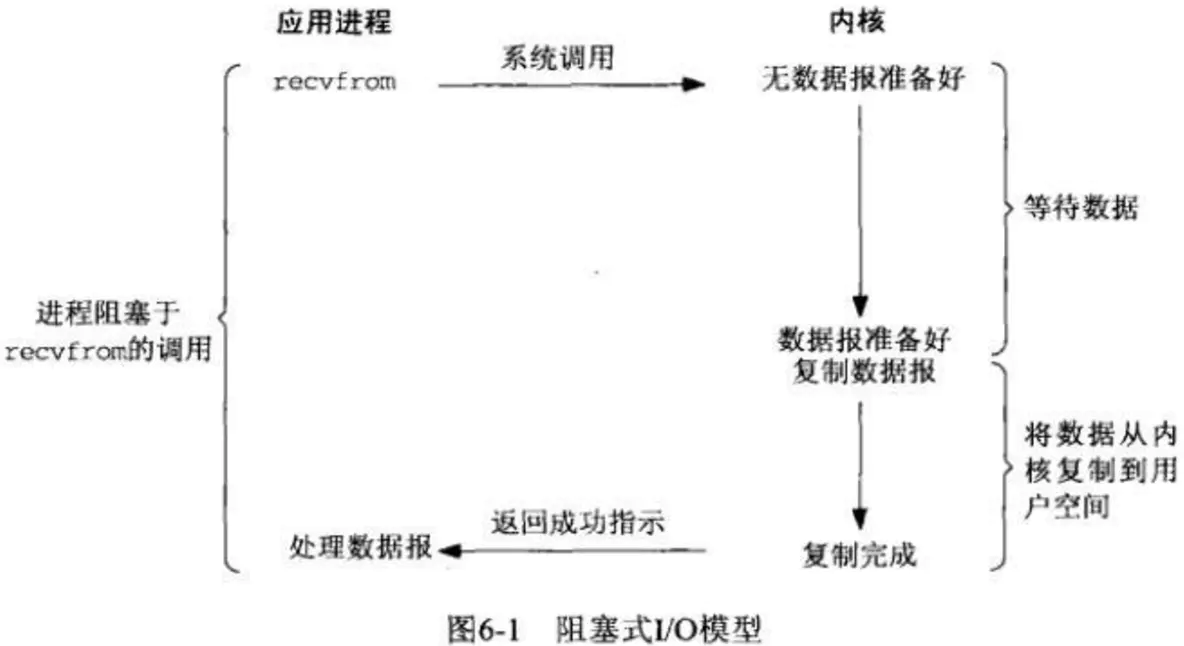
用户态进程进行系统调用后,内核态需要进行等待,知道数据准备好(比如键盘数据,远程调用等)后把数据从内核态复制到用户态后,调用进程才可以拿到数据继续运行。在这段时间内,调用进程不能做任何其他的事情,一直阻塞在那里。
在具体的代码编写中,http服务器编式不能采用阻塞式IO编写的,因为当访问量增大后,会增加服务器的消耗,因为很多线程都是在等待客户端的连入,浪费资源。
2.非阻塞式IO
当进程进行系统调用后,内核系统会立即返回一个返回值。用户进程获取返回值后,并不能获取真实的处理结果。此时就需要以同步的模式主动去内核轮询处理结果,如果轮询有了结果,那么就会结束调用,如果没有则继续轮询。

3. 多路复用IO
多路复用IO模型是依赖内核具体实现的。如果系统没有select,poll,epoll等功能,那么设计层面是不能设计出来多路复用的。
“select调用是内核级别的,可以等待多个socket,能实现同时对多个IO端口进行监听,当其中任何一个socket的数据准好了,就能返回进行可读,然后进程再进行recvform系统调用,将数据由内核拷贝到用户进程,这个过程是阻塞的。”
select有一些明显的不足:
(1)调用select,需要把fd集合从用户态拷贝到内核态,开销在fd很多时,开销会很大;
(2)调用select需要在内核遍历传递进来的所有fd,在fd很多时开销很大;
(3)select支持的fd数量小,默认是1024;
poll和select其实是差不多的,只是poll的fd表示方法不一样,这让poll支持的fd数量远远不止1024个
epoll是为了改进上面的一些不足之处而升级的。从上面可以看出,fd集合需要在内核态和用户态之间不停的移动,每次主动轮询数据时候,要遍历内核态中所有的fd,这两个方面就会出现很多重复的事情要做,epoll对这两个方面进行了优化。
epoll提供了三个函数,epoll_create,epoll_ctl和epoll_wait,epoll_create创建一个epoll句柄;epoll_ctl是注册要监听的事件类型;epoll_wait则是等待事件的产生。
首先epoll会调用epoll_creaet创建一个epoll的句柄(fd1),之后通过调用epoll_ctl将新的句柄添加到fd1上,并且标记上EPOLL_CTL_ADD,这一步会把生成的新的句柄fd2拷贝到内核态中,每次只要有新的句柄产生,就会产生一次用户态到内核态的拷贝。这样就避免了每次都要把整个fd集合全部拷贝到内核中。epoll会在内核中额外开辟一块空间,如果某一个fd准备就绪,那么这个fd就会被复制到新的空间中,epoll_wait方法会专门去这块空间中去获取fd的状态,这种epoll_wait就不用轮询内核中整个fd集合,提高了效率。