2015-3-27
参考:
http://www.cnblogs.com/baixl/p/4154429.html
http://blog.csdn.net/u010911997/article/details/44099165
============================================
hadoop在虚拟机上(远程连接也是一样只需要知道master的ip和core-site.xml配置即可。
Vmware上搭建了hadoop分布式平台:
192.168.47.133 master
192.168.47.134 slave1
192.168.47.135 slave2
core-site.xml 配置文件:
<property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> <description>The name of the default file system.</description> </property>
1 下载插件
hadoop-eclipse-plugin-2.6.0.jar
github上下载源码后需要自己编译。这里使用已经编译好的插件即可
2 配置插件
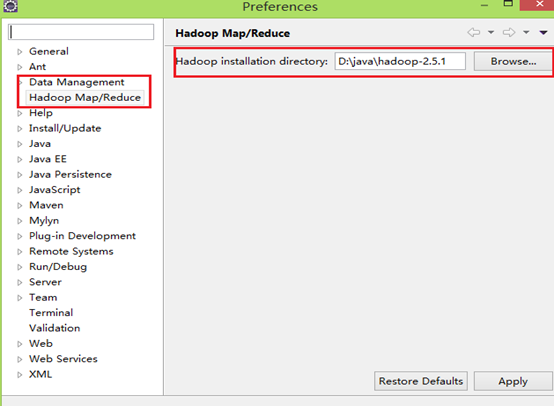
把插件放到..eclipseplugins目录下,重启eclipse,配置Hadoop installation directory ,
如果插件安装成功,打开Windows—Preferences后,在窗口左侧会有Hadoop Map/Reduce选项,点击此选项,在窗口右侧设置Hadoop安装路径。(windows下只需把hadoop-2.5.1.tar.gz解压到指定目录)
3 配置Map/Reduce Locations
打开Windows—Open Perspective—Other,选择Map/Reduce,点击OK,控制台会出现:

右键 new Hadoop location 配置hadoop:输入
Location Name,任意名称即可.
配置Map/Reduce Master和DFS Mastrer,Host和Port配置成与core-site.xml的设置一致即可。

点击"Finish"按钮,关闭窗口。
点击左侧的DFSLocations—>master (上一步配置的location name),如能看到user,表示安装成功
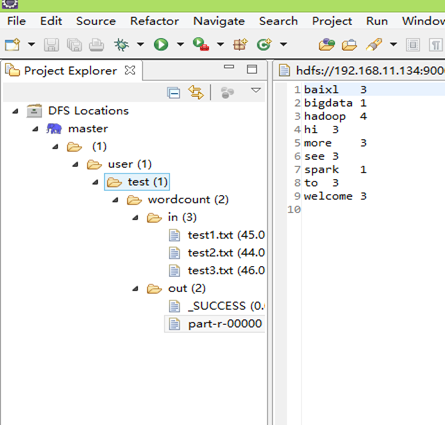
4 wordcount实例
File—>Project,选择Map/Reduce Project,输入项目名称WordCount等。在WordCount项目里新建class,名称为WordCount,代码如下:
|
import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { public static class TokenizerMapper extendsMapper<Object,Text,Text,IntWritable>{ private final static IntWritable one=new IntWritable(1); private Text word =new Text(); public void map(Object key,Text value,Context context) throwsIOException,InterruptedException{ StringTokenizer itr=new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } } public static class IntSumReducer extendsReducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values,Contextcontext) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = new Job(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, newPath("hdfs://192.168.11.134:9000/in/test*.txt"));//路径1 FileOutputFormat.setOutputPath(job, newPath("hdfs://192.168.11.134:9000/output"));//输出路径 System.exit(job.waitForCompletion(true) ? 0 : 1); } } |
上面的路径1 和路径2 由于在代码中已经定义,这不需要在配置文件中定义,若上面路径1和路径2 代码为:
|
FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); |
这需要配置运行路径:类 右键 Run As—>Run Configurations
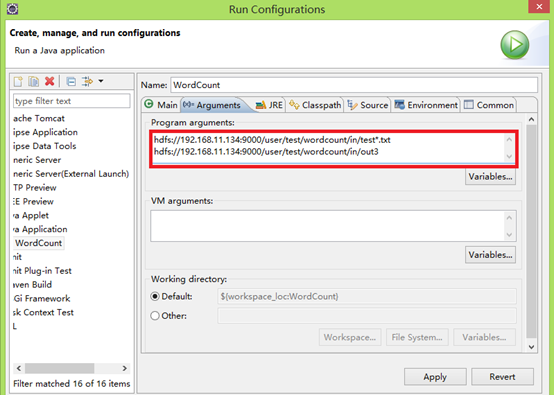
红色部分为配置的hdfs上文件路径,
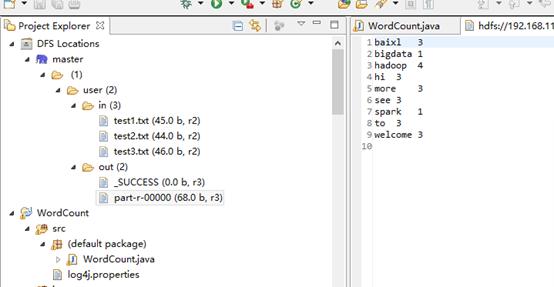
点击run 或或者:Run on Hadoop,运行结果会显示在DFS Locations。若运行中有更新,右键DFS Locations,点disconnect更新
运行结果:
5 问题及解决办法
5.1 出现 空指针异常:
1 在Hadoop的bin目录下放winutils.exe,
2 在环境变量中配置 HADOOP_HOME,
3 hadoop.dll拷贝到C:WindowsSystem32下面即可
下载地址:
http://mail-archives.apache.org/mod_mbox/incubator-slider-commits/201411.mbox/%3Ce263738846864bfda0dd6c17a7457988@git.apache.org%3E
http://git-wip-us.apache.org/repos/asf/incubator-slider/blob/29483696/bin/windows/hadoop-2.6.0-SNAPSHOT/bin/winutils.exe
http://git-wip-us.apache.org/repos/asf/incubator-slider/blob/29483696/bin/windows/hadoop-2.6.0-SNAPSHOT/bin/hadoop.dll
问题1:在DFS Lcation 上不能多文件进行操作:
在hadoop上的每个节点上修改该文件 conf/mapred-site.xml
增加:
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
关闭权限验证
问题2
log4j:WARN No appenders could be foundfor logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4jsystem properly.
log4j:WARN Seehttp://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
在src文件夹下创建以log4j.properties命名的文件
文件内容如下
log4j.rootLogger=WARN, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d%p [%c] - %m%n
问题3
java.io.IOException: Could not locateexecutable null/bin/winutils.exe in the Hadoop binaries.
缺少winutils.exe 下载一个添加进去就行
下载地址 http://download.csdn.net/detail/u010911997/8478049
问题4
Exceptionin thread "main" java.lang.UnsatisfiedLinkError:org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray(II[BI[BIILjava/lang/String;JZ)V
这是由于hadoop.dll 版本问题,2.4之前的和自后的需要的不一样
需要选择正确的版本并且在 Hadoop/bin和 C:windowssystem32 上将其替换
问题5
Exception in thread "main"java.lang.UnsatisfiedLinkError:org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
atorg.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Native Method)
at org.apache.hadoop.io.nativeio.NativeIO$Windows.access(NativeIO.java:557)
目前未找到解决方法,只能修改源代码
源代码下载 http://pan.baidu.com/s/1jGJzVSy
将源代码放入 工程的src目录下并创建同样的包名,然后修改源代码
源代码 未修改前
publicstaticbooleanaccess(String path, AccessRight desiredAccess)
throws IOException {
return access0(path,desiredAccess.accessRight());
}
源代码 修改后
public staticbooleanaccess(String path, AccessRight desiredAccess)
throws IOException {
return ture;
// return access0(path,desiredAccess.accessRight());
}
修改后编译成功,但是看不到软件运行时候的信息反馈