下载 spark
1、进入官网下载spark
可能并没有显示想要的版本 ➡ spark-2.1.0-bin-without-hadoop.tgz 直链

⚠️ 此时环境是安装了Hadoop的,这个
without就是表示「Hadoop free」,这样下载spark可以应用到任意版本的hadoop
2、spark模式简介
Spark部署模式主要有四种:Local模式(单机模式)、Standalone模式(使用Spark自带的简单集群管理器)、YARN模式(使用YARN作为集群管理器)和Mesos模式(使用Mesos作为集群管理器)。
配置 spark
1、进行基本的配置设置
# 将下载好的spark解压到 /usr/local/下 [解压]
sudo tar -zxf ./spark-2.1.0-bin-without-hadoop.tgz -C /usr/local
# 切换到/usr/local目录
cd /usr/local
# 将spark-2.1.0xxx 改名为 spark [改名]
sudo mv ./spark-2.1.0-bin-without-hadoop/ ./spark
# 增加spark目录 hadoop用户权限 [赋权限]
sudo chown -R hadoop:hadoop ./spark
2、安装后,还需要修改Spark的配置文件spark-env.sh
# /usr/local/spark
cd /usr/local/spark/ # 切换至 spark
# 复制一份spark-env.sh (/usr/local/spark)
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
3、编辑spark-env.sh文件(vim ./conf/spark-env.sh),在第一行添加以下配置信息:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
Q: 上述导入命名作用是什么?
有了上面的配置信息以后,Spark就可以把数据存储到Hadoop分布式文件系统HDFS中,也可以从HDFS中读取数据。如果没有配置上面信息,Spark就只能读写本地数据,无法读写HDFS数据。
配置完成后就可以直接使用,不需要像Hadoop运行启动命令。
4、通过运行Spark自带的示例,验证Spark是否安装成功。
(配置完成后就可以直接使用,不需要像Hadoop运行启动命令。)
cd /usr/local/spark
bin/run-example SparkPi

执行时会输出非常多的运行信息,输出结果不容易找到,可以通过 grep 命令进行过滤(命令中的 2>&1 可以将所有的信息都输出到 stdout 中,否则由于输出日志的性质,还是会输出到屏幕中):
bin/run-example SparkPi 2>&1 | grep "Pi is"
这里涉及到Linux Shell中管道的知识,详情可以参考Linux Shell中的管道命令
过滤后的运行结果如下图示,可以得到π 的 5 位小数近似值:
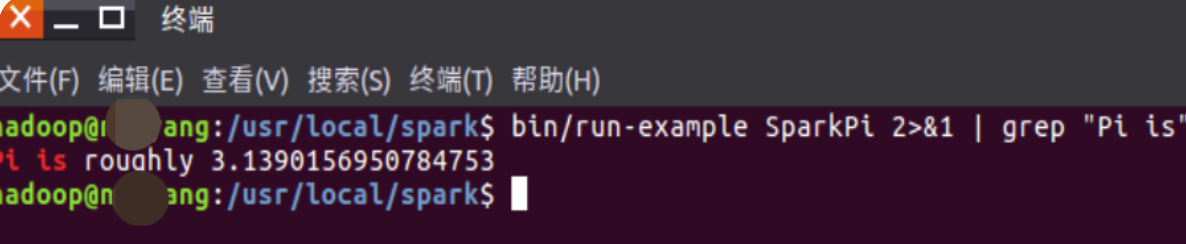
到此 spark2.1.0安装成功 !
相关文章