最近找了十几篇神经网络注意力机制的论文大概读了一下。这篇博客记录一下其中一篇,这篇论文大概只看了摘要,方法,实验只是大概看了一下。文中提出一种残差级联卷积神经网络,这个网络可以分为俩部分,一种是CF-Conv(coarse-fine convolution)此结构利用了多种卷积在网络中是用来提取图像特征,并且将图像融合来获得更多的特征,一种是SCNAU(spatial-channel noise attention unit),此结构由空间通道注意力机制组成,能从固定模式噪声中分离背景细节,来补充上面提取特征所缺少的一些细节。因为FPN(fixed pattern noise reduction)由gain noise和offset noisee组成,因而单个CNN模型可能会造成细节缺失。论文使用将上面俩种结构CF-Conv和SCNAU组合形成feature extraction blocks(FEBs),分别使用五个FEBs和一个1X1的卷积层来组成gain noise reduction subnetwork和offset noise reduction network,这俩种子网络分别用来消去不同的噪声。
CF-Conv
CF-Conv,Coarse-fine convolution unit,我们需要大尺寸的上下文信息,上下文信息越多表明要使用的感受野越大越好,但是不能直接增大卷积核,那样只会增加计算时间和内存消耗。这个结构使用了三种卷积方式,一种是空洞卷积(dilation convolution),一种是子像素卷积(sub-pixel convolution),这俩种卷积分别用来提取粗粒度特征和细粒度特征,还有一种就是标准卷积,空洞卷积留下的盲点由标准卷积来补全的。所有卷积输出都使用ReLU激活函数。之后使用concatenation将上述三个通道全部图链接在一起,比如第一个是32通道,第二个是64通道,第三个是32通道,那么concatenation就是128通道,之后再用标准卷积将之64通道。
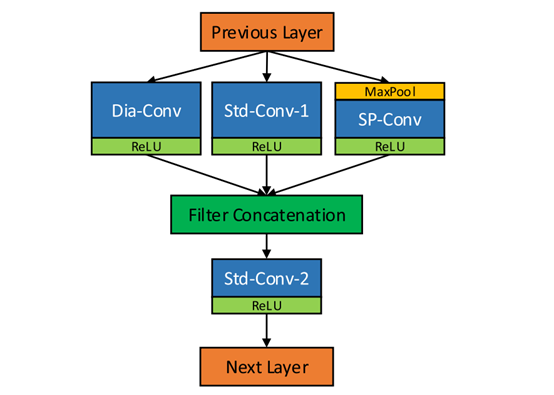
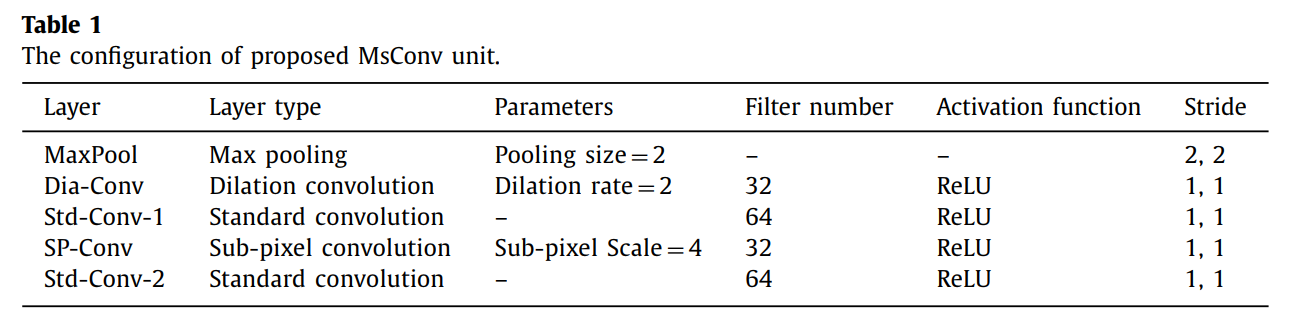
CF-Conv具体结构如下表格表示出来,其中的卷积大小都是3X3的。
SCNAU
SCNAU,上述CNN可以提取图片的特征,但是背景细节上会有所缺失,文中采用的是空间通道注意力组成了SCNAU,这是有三部分组成的,spatial branch、trunk branch和channel branch。spatial branch完全堆积卷积操作来提取空间上的特征,channel branch使用全局池化将之变成通道向量,之后使用全连接操作得出所有的关系。
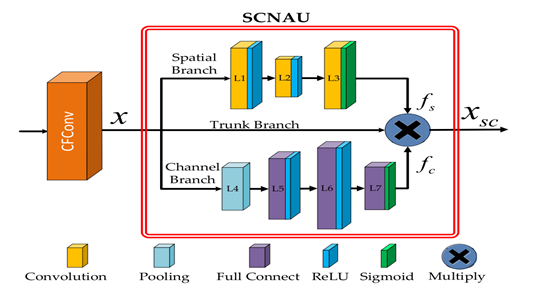
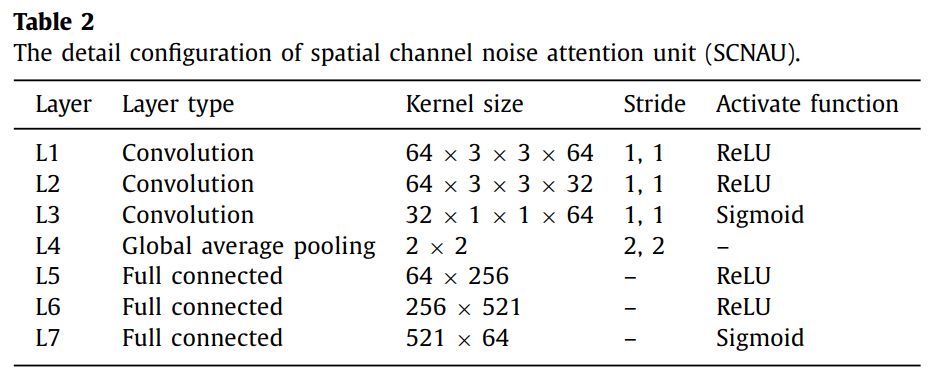
SCNAU具体结构如下表格表示出来,
总体结构
其中网络整体结构如下所示,采用了俩个子网络的结构来组成整体网络。
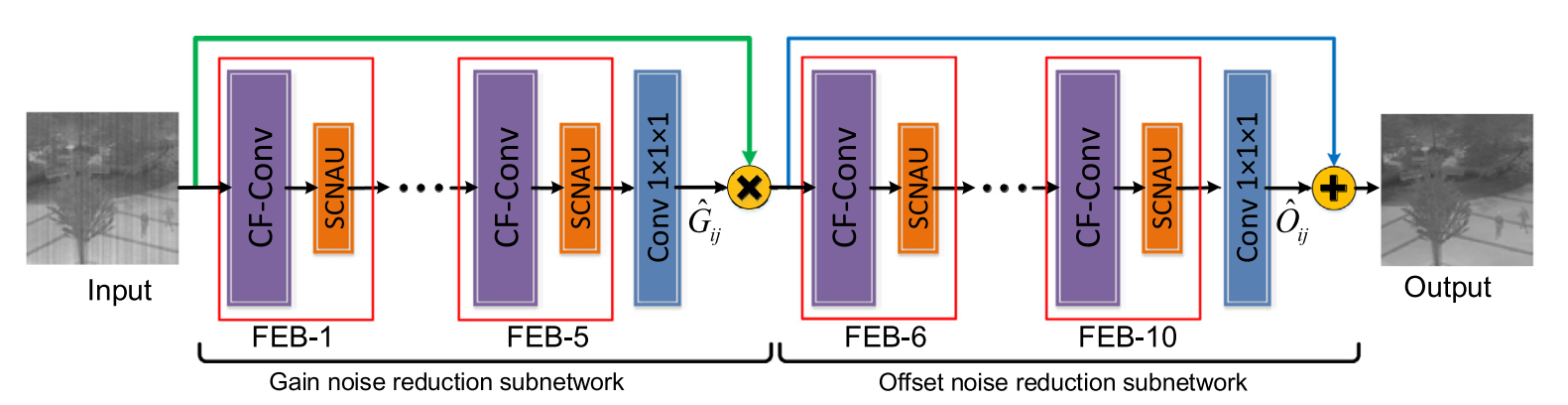
具体网络框架表示如下所示
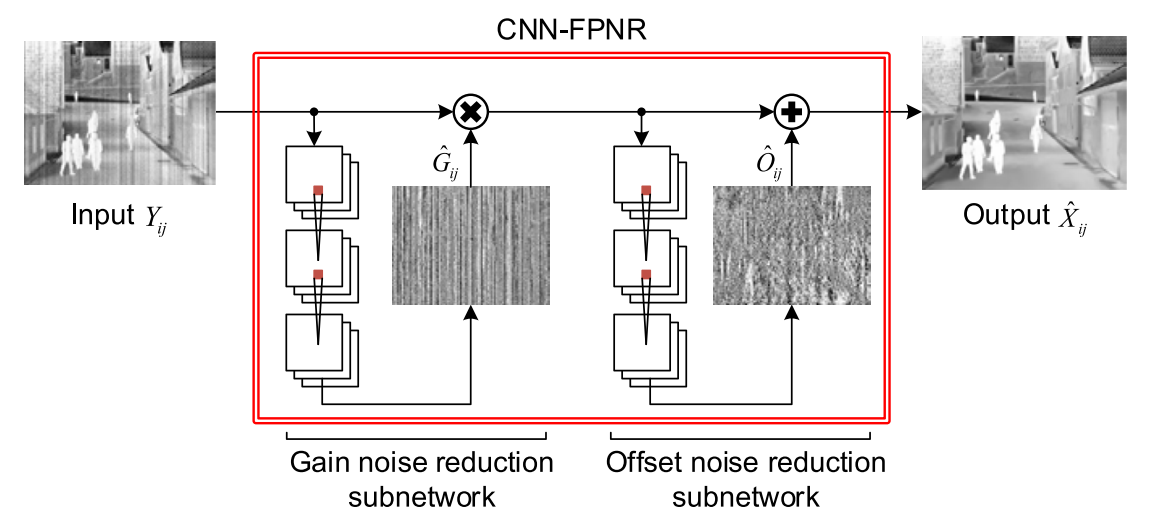
这篇文章是想通过大的感受野来提取出更好的上下文信息,文中对此的策略就是多卷积来提取出不同的尺度的上下文信息,之后将之整合获取更多的特征信息,有了这些之后,再补上关键的背景信息就能完善全部结构。