参考文章:
- https://www.bmc.com/blogs/spark-elasticsearch-hadoop/
- https://blog.pythian.com/updating-elasticsearch-indexes-spark/
- https://qbox.io/blog/elasticsearch-in-apache-spark-python 这里有 RDD level 的写法,有些操作比如count, aggregation 在 DataFrame/DataSet level 不支持pushdown, 所有需要用到RDD level 的写法
Pre-requisite:
先装上 elasticsearch-hadoop 包
Step-by-Step guide
1. 先在ES创建3个document
[mshuai@node1 ~]$ curl -XPUT --header 'Content-Type: application/json' http://your_ip:your_port/school/doc/1 -d '{ "school" : "Clemson" }' [mshuai@node1 ~]$ curl -XPUT --header 'Content-Type: application/json' http://your_ip:your_port/school/doc/2 -d '{ "school" : "Harvard"
}'
2. Spark 里面去读,这里是pyspark 代码
reader = spark.read.format("org.elasticsearch.spark.sql").option("es.read.metadata", "true").option("es.nodes.wan.only","true").option("es.port","your_port").option("es.net.ssl","false").option("es.nodes", "your_ip") df = reader.load("school") df.show()
输出这个格式的信息
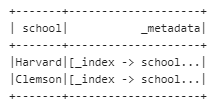
3. 接下来尝试update 一个记录,先得到一个要改的id
hot = df.filter(df["school"] == 'Harvard') .select(expr("_metadata._id as id")).withColumn('hot', lit(True)) hot.show()

4. 先来加一列
esconf={} esconf["es.mapping.id"] = "id" esconf["es.mapping.exclude"]='id' esconf["es.nodes"] = "your_ip" esconf["es.port"] = "your_port" esconf["es.write.operation"] = "update" esconf["es.nodes.discovery"] = "false" esconf["es.nodes.wan.only"] = "true" hot.write.format("org.elasticsearch.spark.sql").options(**esconf).mode("append").save("school/doc")
看,成功加了 hot 列,满足条件的记录赋了对应的值
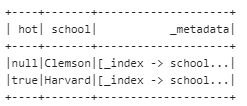
5. 又来update已经存在的信息
esconf={} esconf["es.mapping.id"] = "id" esconf["es.nodes"] = "your_ip" esconf["es.port"] = "your_port" esconf["es.update.script.inline"] = "ctx._source.school = params.school" esconf["es.update.script.params"] = "school:<SCU>" esconf["es.write.operation"] = "update" esconf["es.nodes.discovery"] = "false" esconf["es.nodes.wan.only"] = "true" hot.write.format("org.elasticsearch.spark.sql").options(**esconf).mode("append").save("school/doc") reader.load("school").show()
嗯。。。成功把Harvard改成了川大
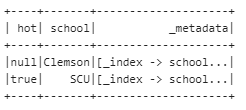
另外,怎么upload attachment 到ES呢?可以用这个plugin Ingest Attachment Processor Plugin