Algorithm:

怎么分配 training set, CV, test set?

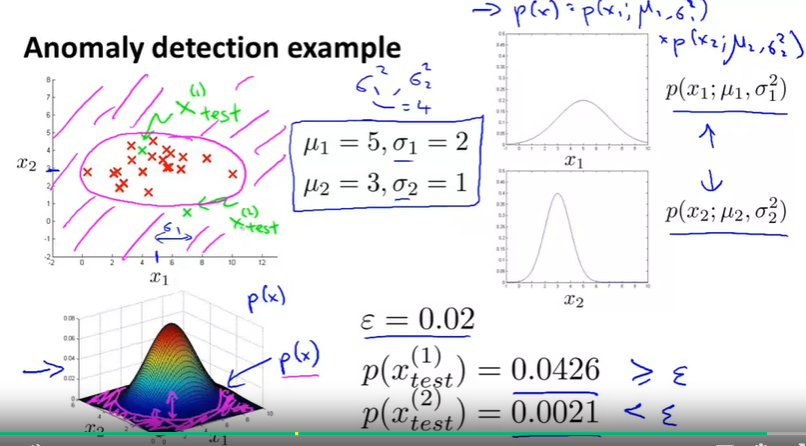
When to select Anomaly detection(一种无监督学习) or Supervised learning? 总的来说guideline是如果positive example (anomaly examples)特别少就用Anamaly detection. 如果数据positive example 越来越多,可以选择从Anomanly detection 切换到 Supervised learning.
怎么选择feature ?
可以先画出feature的分布图,如果不符合高斯分布,就对feature做一些转化,使得更像高斯分布
如果一维feature实在不像高斯分布或者一维不足以分别开,可以考虑给feature再多加一个维度
Multivariate Gaussian(Normal) examples
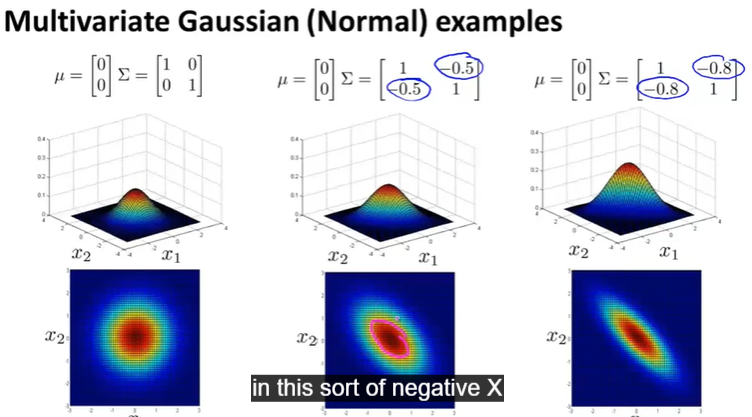

The original Gaussian model is a specific multivariate Gaussian model, please see following picture
Original vs Multivariate Gaussian
虽然Multivariate 更全面,但是一般来说Original用的更多一些,因为计算cheeper, 一般在m很大n不大的时候考虑Mutivariate版本
Recommender system
- content based recommender system (content based 意思是比如我们已经知道每个电影的类型,像爱情片,动作片,。。。)
人工分析每个电影的内容,得出feature 值,就是下面的romance, action 对应的值. 然后用linear regression 求出 theta.
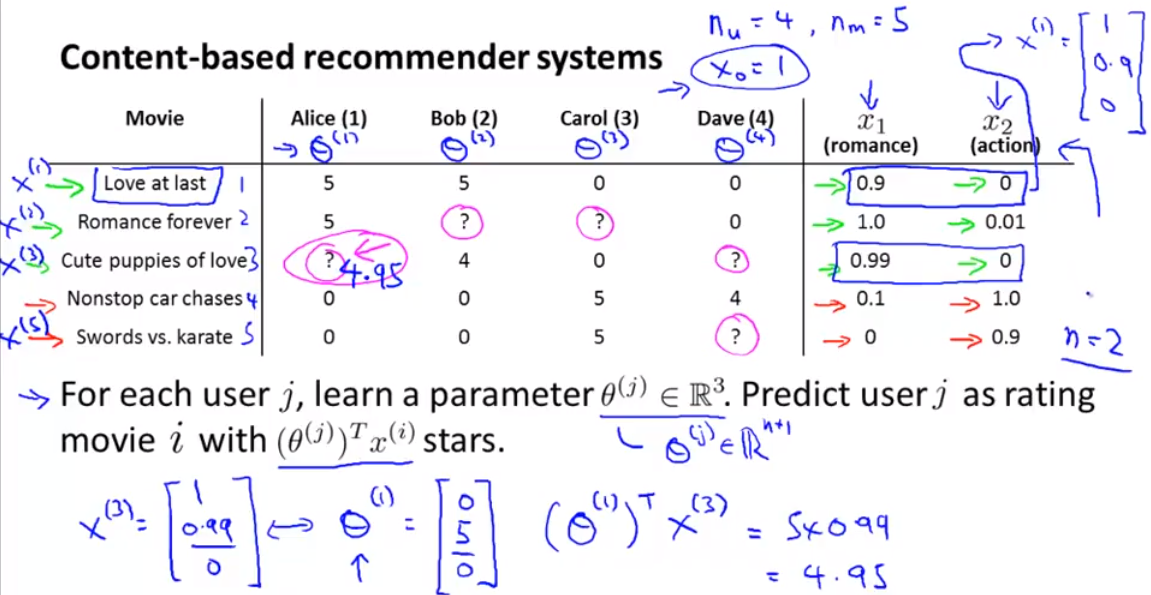

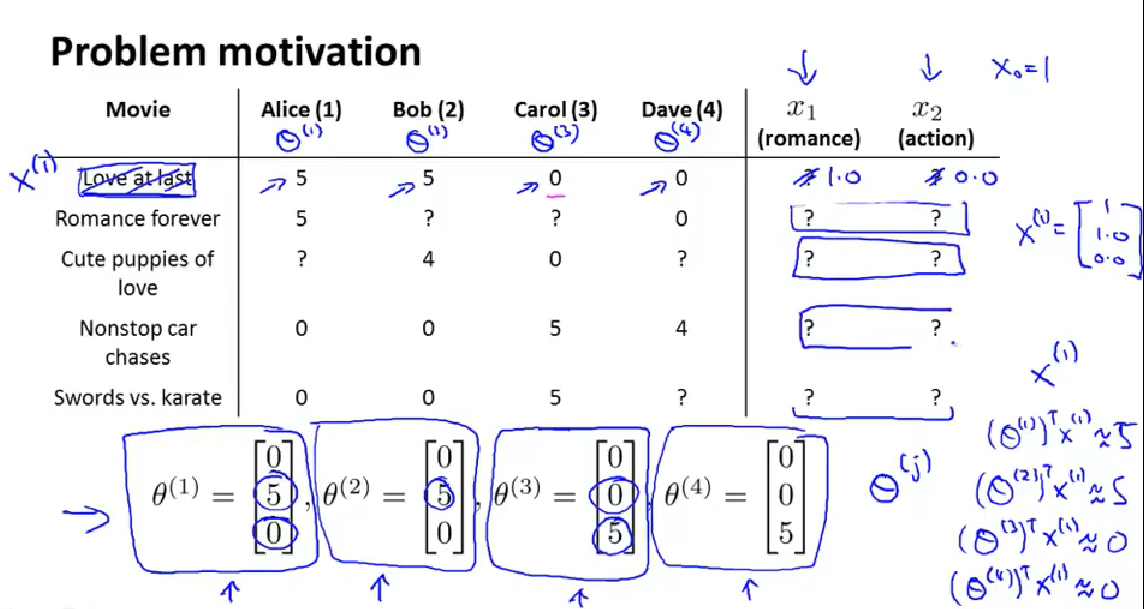
上面讲的是针对一个user的theta 参数,下面这个图是learn 所以的参数
- colabarative filtering algorithm (for feature learning, for specifically, theta->x->theta->x...)
algorithm:
concept of the algorithm of colabarative filtering
cost function:
calculate theta and x simutanously in one cost function
derivative:

- low rack matrix factorization ( 不是一种新算法,是collaborating filter algo 的矩阵实现)
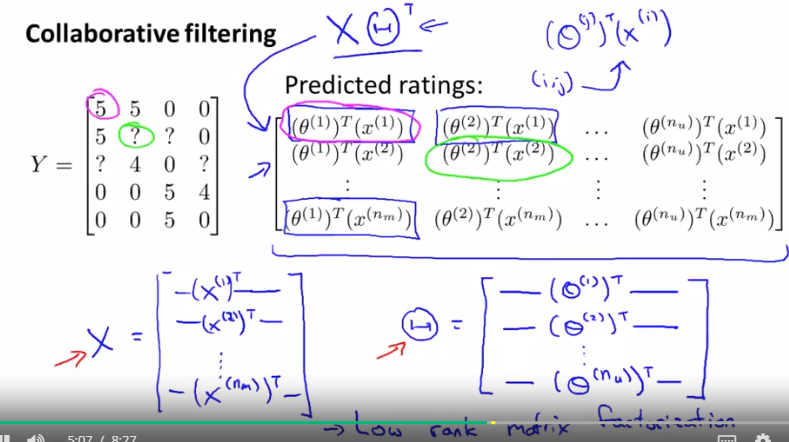
Ref: