前言
本篇演示如何使用 AWS EC2 云服务搭建集群。当然在只有一台计算机的情况下搭建完全分布式集群,还有另外几种方法:一种是本地搭建多台虚拟机,好处是免费易操控,坏处是虚拟机对宿主机配置要求较高,我就一台普通的笔记本,开两三个虚拟机实在承受不起; 另一种方案是使用 AWS EMR ,是亚马逊专门设计的集群平台,能快速启动集群,且具有较高的灵活性和扩展性,能方便地增加机器。然而其缺点是只能使用预设的软件,如下图:

如果要另外装软件,则需要使用 Bootstrap 脚本,详见 https://docs.aws.amazon.com/zh_cn/emr/latest/ManagementGuide/emr-plan-software.html?shortFooter=true ,可这并不是一件容易的事情,记得之前想在上面装腾讯的 Angel 就是死活都装不上去。 另外,如果在 EMR 上关闭了集群,则里面的文件和配置都不会保存,下次使用时全部要重新设置,可见其比较适用于一次性使用的场景。
综上所述,如果使用纯 EC2 进行手工搭建,则既不会受本地资源限制,也具有较高的灵活性,可以随意配置安装软件。而其缺点就是要手工搭建要耗费较多时间,而且在云上操作和在本地操作有些地方是不一样的,只要有一步出错可能就要卡壳很久,鉴于网上用 EC2 搭建这方面资料很少,因此这里写一篇文章把主要流程记录下来。
如果之前没有使用过 EC2,可能需要花一段时间熟悉,比如注册以及创建密钥对等步骤,官方提供了相关教程 。另外我的本地机和云端机使用的都是 Ubuntu 16.04 LTS 64位,如果你的本地机是 Windows,则需要用 Git 或 PuTTY 连接云端机,详情参阅 https://docs.aws.amazon.com/zh_cn/AWSEC2/latest/UserGuide/putty.html 。
创建 EC2 实例
下面正式开始,这里设立三台机器 (实例),一台作主节点 (master node),两台作从节点 (slaves node)。首先创建实例,选择 Ubuntu Server 16.04 LTS (HVM) ,实例类型选择价格低廉的 t2.medium 。如果是第一次用,就不要选价格太高的类型了,不然万一操作失误了每月账单可承受不起。



在第 3 步中,因为要同时开三台机器,Number of Instances 可以直接选择3。但如果是每台分别开的话,下面的 Subnet 都要选择同一个区域,不然机器间无法通信,详情参阅 https://docs.aws.amazon.com/zh_cn/AWSEC2/latest/UserGuide/using-regions-availability-zones.html 。

第 4 步设置硬盘大小,如果就搭个集群可能不用动,如果还要装其他软件,可能就需要在这里增加容量了,我是增加到了 15 GB:

第 5 和第 6 步直接Next 即可,到第 7 步 Launch 后选择或新建密钥对,就能得到创建好的 3 个实例,这里可以设置名称备注,如 master、slave01、slave02 等:

开启 3 个终端窗口,ssh 连接3个实例,如 ssh -i xxxx.pem ubuntu@ec2-xx-xxx-xxx-xx.us-west-2.compute.amazonaws.com ,其中 xxxx.pem 是你的本地密钥对名称,ec2-xx-xxx-xxx-xx.us-west-2.compute.amazonaws.com 是该实例的外部 DNS 主机名,每台实例都不一样。这里需要说明一下,因为这是和本地开虚拟机的不同之处: EC2 的实例都有**公有 IP 和私有 IP **之分,私有 IP 用于云上实例之间的通信,而公有 IP 则用于你的本地机与实例之间的通信,因此这里 ssh 连接使用的是公有 IP (DNS) 。在下面搭建集群的步骤中也有需要填写公有和私有 IP ,注意不要填反了。关于二者的区别参阅 https://docs.aws.amazon.com/zh_cn/AWSEC2/latest/UserGuide/using-instance-addressing.html?shortFooter=true#using-instance-addressing-common 。
新增 hadoop 用户、安装 Java 环境
以下以 master 节点为例。登陆实例后,默认用户为 ubuntu,首先需要创建一个 hadoop 用户:
$ sudo useradd -m hadoop -s /bin/bash # 增加 hadoop用户
$ sudo passwd hadoop # 设置密码,需要输入两次
$ sudo adduser hadoop sudo # 为 hadoop 用户增加管理员权限
$ su hadoop # 切换到 hadoop 用户,需要输入密码
$ sudo apt-get update # 更新 apt 源
这一步完成之后,终端用户名会变为 hadoop,且 /home 目录下会另外生成一个 hadoop 文件夹。

Hadoop 依赖于 Java 环境,所以接下来需要先安装 JDK,直接从官网下载,这里下的是 Linux x64 版本 jdk-8u231-linux-x64.tar.gz ,用 scp 远程传输到 master 机。注意这里只能传输到 ubuntu 用户下,传到 hadoop 用户下可能会提示权限不足。
$ scp -i xxx.pem jdk-8u231-linux-x64.tar.gz ubuntu@ec2-xx-xxx-xxx-xx.us-west-2.compute.amazonaws.com:/home/ubuntu/ # 本地执行该命令
本篇假设所有软件都安装在 /usr/lib 目录下:
$ sudo mv /home/ubuntu/jdk-8u231-linux-x64.tar.gz /home/hadoop # 将文件移动到 hadoop 用户下
$ sudo tar -zxf /home/hadoop/jdk-8u231-linux-x64.tar.gz -C /usr/lib/ # 把JDK文件解压到/usr/lib目录下
$ sudo mv /usr/lib/jdk1.8.0_231 /usr/lib/java # 重命名java文件夹
$ vim ~/.bashrc # 配置环境变量,貌似EC2只能使用 vim
添加如下内容:
export JAVA_HOME=/usr/lib/java
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
$ source ~/.bashrc # 让配置文件生效
$ java -version # 查看 Java 是否安装成功
如果出现以下提示则表示安装成功:

在 master 节点完成上述步骤后,在两个 slave 节点完成同样的步骤 (新增 hadoop 用户、安装 Java 环境)
网络配置
这一步是为了便于 Master 和 Slave 节点进行网络通信,在配置前请先确定是以 hadoop 用户登录的。首先修改各个节点的主机名,执行 sudo vim /etc/hostname ,在 master 节点上将 ip-xxx-xx-xx-xx 变更为 Master 。其他节点类似,在 slave01 节点上变更为 Slave01,slave02 节点上为 Slave02。
然后执行 sudo vim /etc/hosts 修改自己所用节点的IP映射,以 master 节点为例,添加红色区域内信息,注意这里的 IP 地址是上文所述的私有 IP:

接着在两个 slave 节点的hosts中添加同样的信息。完成后重启一下,在进入 hadoop 用户,能看到机器名的变化 (变成 Master 了):
对于 ec2 实例来说,还需要配置安全组 (Security groups),使实例能够互相访问 :

选择划线区域,我因为是同时建立了三台实例,所以安全组都一样,如果不是同时建立的,这可能三台都要配置。
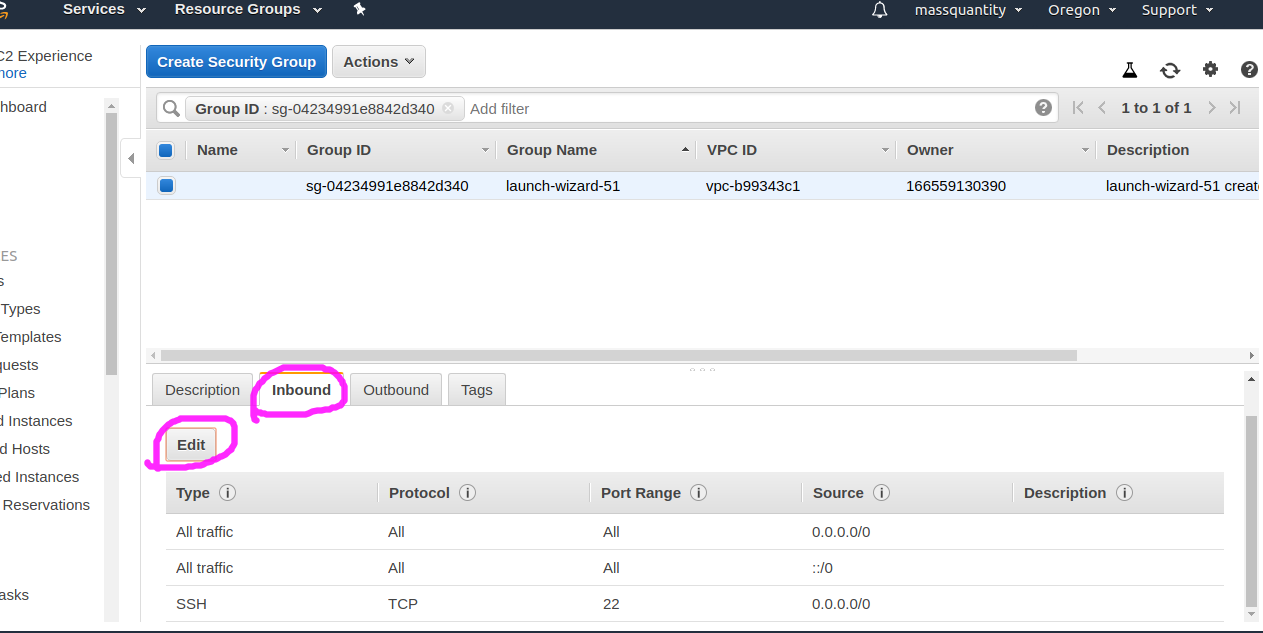
进入后点击 Inbound 再点 Edit ,再点击 Add Rule,选择里面的 All Traffic ,接着保存退出:

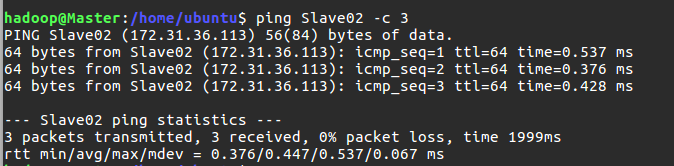
三台实例都设置完成后,需要互相 ping 一下测试。如果 ping 不通,后面是不会成功的:
$ ping Master -c 3 # 分别在3台机器上执行这三个命令
$ ping Slave01 -c 3
$ ping Slave02 -c 3
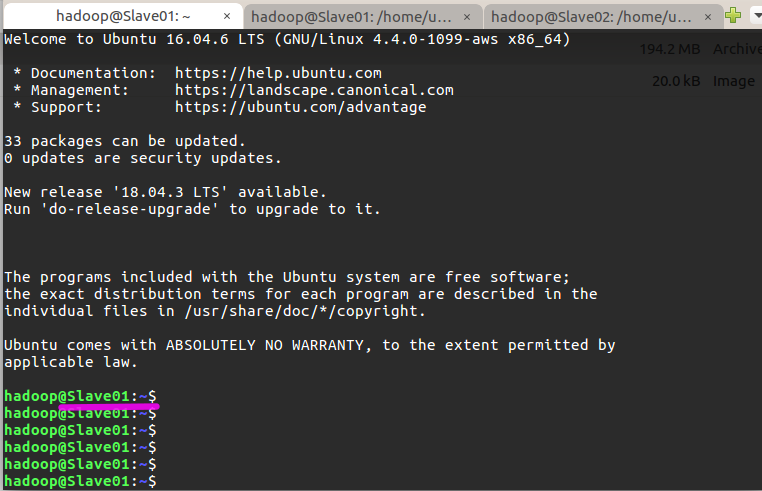
接下来安装 SSH server, SSH 是一种网络协议,用于计算机之间的加密登录。安装完 SSH 后,要让 Master 节点可以无密码 SSH 登陆到各个 Slave 节点上,在Master节点执行:
$ sudo apt-get install openssh-server
$ ssh localhost # 使用 ssh 登陆本机,需要输入 yes 和 密码
$ exit # 退出刚才的 ssh localhost, 注意不要退出hadoop用户
$ cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
$ ssh-keygen -t rsa # 利用 ssh-keygen 生成密钥,会有提示,疯狂按回车就行
$ cat ./id_rsa.pub >> ./authorized_keys # 将密钥加入授权
$ scp ~/.ssh/id_rsa.pub Slave01:/home/hadoop/ # 将密钥传到 Slave01 节点
$ scp ~/.ssh/id_rsa.pub Slave02:/home/hadoop/ # 将密钥传到 Slave02 节点
接着在 Slave01和 Slave02 节点上,将 ssh 公匙加入授权:
$ mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在则忽略
$ cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
这样,在 Master 节点上就可以无密码 SSH 到各个 Slave 节点了,可在 Master 节点上执行如下命令进行检验,如下图所示变为 Slave01了,再按 exit 可退回到 Master:
至此网络配置完成。
安装 Hadoop
去到镜像站 https://archive.apache.org/dist/hadoop/core/ 下载,我下载的是 hadoop-2.8.4.tar.gz 。在 Master 节点上执行:
$ sudo tar -zxf /home/ubuntu/hadoop-2.8.4.tar.gz -C /usr/lib # 解压到/usr/lib中
$ cd /usr/lib/
$ sudo mv ./hadoop-2.8.4/ ./hadoop # 将文件夹名改为hadoop
$ sudo chown -R hadoop ./hadoop # 修改文件权限
将 hadoop 目录加到环境变量,这样就可以在任意目录中直接使用 hadoop、hdfs 等命令。执行 vim ~/.bashrc ,加入一行:
export PATH=$PATH:/usr/lib/hadoop/bin:/usr/lib/hadoop/sbin
保存后执行 source ~/.bashrc 使配置生效。
完成后开始修改 Hadoop 配置文件(这里也顺便配置了 Yarn),先执行 cd /usr/lib/hadoop/etc/hadoop ,共有 6 个需要修改 —— hadoop-env.sh、slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 。
1、文件 hadoop-env.sh 中把 export JAVA_HOME=${JAVA_HOME} 修改为 export JAVA_HOME=/usr/lib/java ,即 Java 安装路径。
2、 文件 slaves 把里面的 localhost 改为 Slave01和 Slave02 。

3、core-site.xml 改为如下配置:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/lib/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
4、hdfs-site.xml 改为如下配置:
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/lib/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/lib/hadoop/tmp/dfs/data</value>
</property>
</configuration>
5、文件 mapred-site.xml (可能需要先重命名,默认文件名为 mapred-site.xml.template):
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
</configuration>
6、文件 yarn-site.xml :
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
配置好后,将 Master 上的 /usr/lib/hadoop 文件夹复制到各个 slave 节点上。在 Master 节点上执行:
$ cd /usr/lib
$ tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先压缩再复制
$ scp ~/hadoop.master.tar.gz Slave01:/home/hadoop
$ scp ~/hadoop.master.tar.gz Slave02:/home/hadoop
分别在两个 slave 节点上执行:
$ sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/lib
$ sudo chown -R hadoop /usr/lib/hadoop
安装完成后,首次启动需要先在 Master 节点执行 NameNode 的格式化:
$ hdfs namenode -format # 首次运行需要执行初始化,之后不需要
成功的话,会看到 “successfully formatted” 和 “Exitting with status 0” 的提示,若为 “Exitting with status 1” 则是出错。

接着可以启动 Hadoop 和 Yarn 了,启动需要在 Master 节点上进行:
$ start-dfs.sh
$ start-yarn.sh
$ mr-jobhistory-daemon.sh start historyserver
通过命令 jps 可以查看各个节点所启动的进程。正确的话,在 Master 节点上可以看到 NameNode、ResourceManager、SecondrryNameNode、JobHistoryServer 进程,如下图所示:

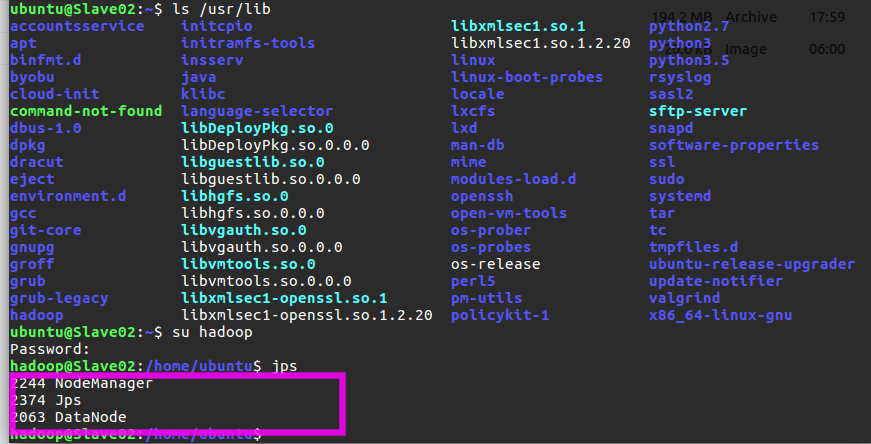
在 Slave 节点可以看到 DataNode 和 NodeManager 进程,如下图所示:
通过命令 hdfs dfsadmin -report 可查看集群状态,其中 Live datanodes (2) 表明两个从节点都已正常启动,如果是 0 则表示不成功:

可以通过下列三个地址查看 hadoop 的 web UI,其中 ec2-xx-xxx-xxx-xx.us-west-2.compute.amazonaws.com 是该实例的外部 DNS 主机名,50070、8088、19888 分别是 hadoop、yarn、JobHistoryServer 的默认端口:
ec2-xx-xxx-xxx-xx.us-west-2.compute.amazonaws.com:50070
ec2-xx-xxx-xxx-xx.us-west-2.compute.amazonaws.com:8088
ec2-xx-xxx-xxx-xx.us-west-2.compute.amazonaws.com:19888

执行 Hadoop 分布式实例
$ hadoop fs -mkdir -p /user/hadoop # 在hdfs上创建hadoop账户
$ hadoop fs -mkdir input
$ hadoop fs -put /usr/lib/hadoop/etc/hadoop/*.xml input # 将hadoop配置文件复制到hdfs中
$ hadoop jar /usr/lib/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+' # 运行实例
如果成功可以看到以下输出:


最后关闭 Hadoop 集群需要执行以下命令:
$ stop-yarn.sh
$ stop-dfs.sh
$ mr-jobhistory-daemon.sh stop historyserver
安装 Spark
去到镜像站 https://archive.apache.org/dist/spark/ 下载,由于之前已经安装了Hadoop,所以我下载的是无 Hadoop 版本的,即 spark-2.3.3-bin-without-hadoop.tgz 。在 Master 节点上执行:
$ sudo tar -zxf /home/ubuntu/spark-2.3.3-bin-without-hadoop.tgz -C /usr/lib # 解压到/usr/lib中
$ cd /usr/lib/
$ sudo mv ./spark-2.3.3-bin-without-hadoop/ ./spark # 将文件夹名改为spark
$ sudo chown -R hadoop ./spark # 修改文件权限
将 spark 目录加到环境变量,执行 vim ~/.bashrc 添加如下配置:
export SPARK_HOME=/usr/lib/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
保存后执行 source ~/.bashrc 使配置生效。
接着需要配置了两个文件,先执行 cd /usr/lib/spark/conf 。
1、 配置 slaves 文件
mv slaves.template slaves # 将slaves.template重命名为slaves
slaves文件设置从节点。编辑 slaves 内容,把默认内容localhost替换成两个从节点的名字:
Slave01
Slave02
2、配置 spark-env.sh 文件
mv spark-env.sh.template spark-env.sh
编辑 spark-env.sh 添加如下内容:
export SPARK_DIST_CLASSPATH=$(/usr/lib/hadoop/bin/hadoop classpath)
export HADOOP_CONF_DIR=/usr/lib/hadoop/etc/hadoop
export SPARK_MASTER_IP=172.31.40.68 # 注意这里填的是Master节点的私有IP
export JAVA_HOME=/usr/lib/java
配置好后,将 Master 上的 /usr/lib/spark 文件夹复制到各个 slave 节点上。在 Master 节点上执行:
$ cd /usr/lib
$ tar -zcf ~/spark.master.tar.gz ./spark
$ scp ~/spark.master.tar.gz Slave01:/home/hadoop
$ scp ~/spark.master.tar.gz Slave02:/home/hadoop
然后分别在两个 slave 节点上执行:
$ sudo tar -zxf ~/spark.master.tar.gz -C /usr/lib
$ sudo chown -R hadoop /usr/lib/spark
在启动 Spark 集群之前,先确保启动了 Hadoop 集群:
$ start-dfs.sh
$ start-yarn.sh
$ mr-jobhistory-daemon.sh start historyserver
$ start-master.sh # 启动 spark 主节点
$ start-slaves.sh # 启动 spark 从节点
可通过 ec2-xx-xxx-xxx-xx.us-west-2.compute.amazonaws.com:8080 访问 spark web UI 。

执行 Spark 分布式实例
1、通过命令行提交 JAR 包:
$ spark-submit --class org.apache.spark.examples.SparkPi --master spark://Master:7077 /usr/lib/spark/examples/jars/spark-examples_2.11-2.3.3.jar 100 2>&1 | grep "Pi is roughly"
结果如下说明成功:

2、通过 IDEA 远程连接运行程序:
可以在 本地 IDEA 中编写代码,远程提交到云端机上执行,这样比较方便调试。需要注意的是 Master 地址填云端机的公有 IP 地址。下面以一个 WordVec 程序示例,将句子转换为向量形式:
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.log4j.{Level, Logger}
import org.apache.spark.ml.feature.Word2Vec
import org.apache.spark.ml.linalg.Vector
import org.apache.spark.sql.Row
import org.apache.spark.sql.SparkSession
object Word2Vec {
def main(args: Array[String]) {
Logger.getLogger("org").setLevel(Level.ERROR) // 控制输出信息
Logger.getLogger("com").setLevel(Level.ERROR)
val conf = new SparkConf()
.setMaster("spark://ec2-54-190-51-132.us-west-2.compute.amazonaws.com:7077") // 填公有DNS或公有IP地址都可以
.setAppName("Word2Vec")
.set("spark.cores.max", "4")
.set("spark.executor.memory", "2g")
val sc = new SparkContext(conf)
val spark = SparkSession
.builder
.appName("Word2Vec")
.getOrCreate()
val documentDF = spark.createDataFrame(Seq(
"Hi I heard about Spark".split(" "),
"I wish Java could use case classes".split(" "),
"Logistic regression models are neat".split(" ")
).map(Tuple1.apply)).toDF("text")
val word2Vec = new Word2Vec()
.setInputCol("text")
.setOutputCol("result")
.setVectorSize(3)
.setMinCount(0)
val model = word2Vec.fit(documentDF)
val result = model.transform(documentDF)
result.collect().foreach { case Row(text: Seq[_], features: Vector) =>
println(s"Text: [${text.mkString(", ")}] =>
Vector: $features
") }
}
}
IDEA 控制台输出:

关闭 Spark 和 Hadoop 集群有以下命令:
$ stop-master.sh
$ stop-slaves.sh
$ stop-yarn.sh
$ stop-dfs.sh
$ mr-jobhistory-daemon.sh stop historyserver
/