特征工程是将原始数据转化为更好的代表预测模型的潜在问题的特征的过程,从未提高对未知数据的预测准确性。
scikit-learn库 安装需要numpy,pandas等库
特征抽取对文本数据进行特征值化,方便计算机去理解数据。
字典特征抽取:对字典数据进行特征值化


# Author:song from sklearn.feature_extraction import DictVectorizer def dictvec(): """字典数据抽取""" dict_vec = DictVectorizer(sparse=False) data = dict_vec.fit_transform([{'city':'A市','num':100},{'city':'D市','num':100},{'city':'B市','num':80},{'city':'C市','num':56}]) print(data)#sparse矩阵 print(dict_vec.get_feature_names()) print(dict_vec.inverse_transform(data)) return None if __name__ =="__main__": dictvec() 结果: [[ 1. 0. 0. 0. 100.] [ 0. 0. 0. 1. 100.] [ 0. 1. 0. 0. 80.] [ 0. 0. 1. 0. 56.]] ['city=A市', 'city=B市', 'city=C市', 'city=D市', 'num'] [{'num': 100.0, 'city=A市': 1.0}, {'city=D市': 1.0, 'num': 100.0}, {'city=B市': 1.0, 'num': 80.0}, {'city=C市': 1.0, 'num': 56.0}]
文本特征抽取:对文本数据进行特征值化。
统计所有文章当中所有的次,重复的只看做一次(词的列表)
对每篇文章,在词的列表里面进行统计每个词次数,单个字母不统计(因为单字母不能体现主题)。
对于中文的特征值化,需要先分词处理(下载jieba, jieba.cut(‘文本内容’))
- 下载jieba pip install jieba
- import jieba
- jieba.cut(‘文本内容’)
- 返回值:词语生成器
from sklearn.feature_extraction.text import CountVectorizer def contentvec(): """字典数据抽取""" con_vec = CountVectorizer() data = con_vec.fit_transform({'If the day is done ,','If birds sing no more .','If the wind has fiagged tired '}) print(data.toarray()) print(con_vec.get_feature_names()) return None if __name__ =="__main__": contentvec() 结果 [[0 1 1 0 0 1 1 0 0 0 1 0 0] [1 0 0 0 0 1 0 1 1 1 0 0 0] [0 0 0 1 1 1 0 0 0 0 1 1 1]] ['birds', 'day', 'done', 'fiagged', 'has', 'if', 'is', 'more', 'no', 'sing', 'the', 'tired', 'wind']
tf - idf主要思想:如果某个词或短语在一篇文章出现频率高,并且其他文章很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。 作用是用以评估一字词对于一个文件集或者一个语料库中的其中一份文件的重要程度。
from sklearn.feature_extraction.text import TfidfVectorizer def tfvec(): """字典数据抽取""" tf_vec = TfidfVectorizer(stop_words=None) data = tf_vec.fit_transform({'If the day is done ,','If birds sing no more .','If the wind has fiagged tired '}) print(data.toarray()) print(tf_vec.get_feature_names()) return None if __name__ =="__main__": tfvec() 结果: [[ 0. 0. 0. 0.45050407 0.45050407 0.26607496 0. 0. 0. 0. 0.34261996 0.45050407 0.45050407] [ 0. 0.50461134 0.50461134 0. 0. 0.29803159 0.50461134 0. 0. 0. 0.38376993 0. 0. ] [ 0.47952794 0. 0. 0. 0. 0.28321692 0. 0.47952794 0.47952794 0.47952794 0. 0. 0. ]] ['birds', 'day', 'done', 'fiagged', 'has', 'if', 'is', 'more', 'no', 'sing', 'the', 'tired', 'wind']
特征的预处理:对数据进行处理,通过特定的统计方法(数学方法)将数据转换为算法要求的数据。
数值型数据:标准缩放,1、归一化;2、标准化;3、缺失值
归一化特点:通过对原始数据进行转化把数据映射到(0,1)之间。目的是为了让某个特征对最终结果不会造成影响(如果求结果的数据有好几个特征对结果影响程度相同)
公式: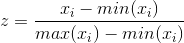 在特定的场景下最大值和最小值是变化的,另外最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性较差。
在特定的场景下最大值和最小值是变化的,另外最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性较差。
from sklearn.preprocessing import MinMaxScaler def mm(): mm = MinMaxScaler(feature_range=(0,1)) #参数限定区间 data = mm.fit_transform([[90,2,10,40],[60,5,15,20],[80,3,12,30]]) print(data) return None if __name__=="__main__": mm() 结果 [[ 1. 0. 0. 1. ] [ 0. 1. 1. 0. ] [ 0.66666667 0.33333333 0.4 0.5 ]]
标准化,使用最广泛,特点处理之后每列的所有数据都聚集在均值为0附近标准差为1,在已有样本比较多的情况下比较稳定,适合大数据场景。
公式: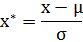 µ为平均值,σ为标准差。
µ为平均值,σ为标准差。
方差公式:平均数:
方差公式:
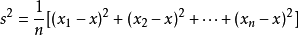 View Code
View Code
View Code
View Code
View Code
View Code
from sklearn.preprocessing import StandardScaler def stand(): std = StandardScaler() data = std.fit_transform([[1,-1,3],[2,3,2],[4,5,6]]) print(data) return None if __name__=="__main__": stand() 结果: [[-1.06904497 -1.33630621 -0.39223227] [-0.26726124 0.26726124 -0.98058068] [ 1.33630621 1.06904497 1.37281295]]
缺失值一般使用pandas处理,按照行值来填补。
数据降维(此处的维度代表的是特征的数量)
特征选择
方法一:filter(过滤式)
from sklearn.feature_selection import VarianceThreshold def var(): var = VarianceThreshold(threshold=0)#删除方差为0的 data = var.fit_transform([[0,2,0,3],[0,1,4,3],[0,1,1,3]]) print(data) return None if __name__=="__main__": var() 结果: [[2 0] [1 4] [1 1]]
方式二:嵌入式,正则决策
PCA(主成分分析)是一种分析简化数据集的技术,维数压缩,特征达到上百时候。
from sklearn.decomposition import PCA def pca(): pca = PCA(n_components=0.9)#小数代表保留数据百分比,整数表示保留几个特征 data = pca.fit_transform([[5,2,0,3],[9,1,4,3],[5,1,1,3]]) print(data) return None if __name__=='__main__': pca() 结果: [[-2.16802239] [ 3.55798483] [-1.38996267]]