ZooKeeper 官网 搭建ZooKeeper Cluster
使用ZooKeeper 目的:ZooKeeper 是一个面向分布式系统的构件块。当设计一个分布式系统时,一般需要设计和开发一些协调服务:
- NS 名称服务-- 名称服务是将一个名称映射到与该名称有关联的一些信息的服务。
DNS服务也是一个名称服务,将一个域名映射到IP地址。 分布式系统中跟踪哪些服务器或服务在运行,并通过名称查看其状态。
ZooKeeper 暴露了一个简单的接口来完成此工作,可将名称服务扩展到组成员服务,可以获得与正在查找其名称的实体有关联的组的信息。
- 锁定--为了允许在分布式系统中对共享资源进行有序的访问,可能需要实现分布式互斥(distributed mutexes)。ZooKeeper 提供一种简单的方式来实现它们。
- 同步--与互斥同时出现的是同步访问共享资源的需求。 无论是实现一个生产者-消费者队列,还是实现一个障碍,ZooKeeper 都提供一个简单的接口来实现该操作。
- 配置管理--可以使用ZooKeeper集中存储和管理分布式系统的配置。意味着,新加入的节点都将在加入系统后就可以立即使用来自ZooKeeper的最新集中式配置。允许通过其中一个ZooKeeper客户端更改集中式配置。集中地更改分布式系统的状态。
- 领导者选举--分布式系统必须处理节点停机的问题,ZooKeeper 通过领导者选举对此提供对自动故障转移策略。
ZooKeeper 是一个针对分布式系统的协调服务,但它本身也是一个分布式应用程序。
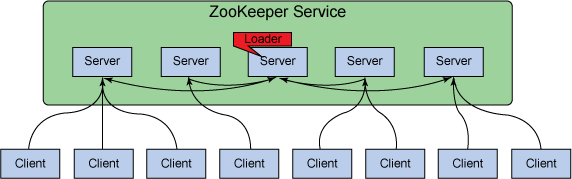
ZooKeeper C-S 模型。
C: 客户端是使用服务的节点(机器)
S: 服务器是提供服务的节点。 ZooKeeper 服务器的集合形成了一个 ZooKeeper 集合体(ensemble )。
C 定期 ping 向 S,被询问到的 S 通过 ping 确认进行响应。彼此确认活动状态。如果客户端在指定时间内未收到服务器确认,则会透明地转移到新的服务器。
znode 层次结构被存储在每个 ZooKeeper 服务器的内存中。实现了对来自客户端的读取操作的可扩展的快速响应。
每个ZooKeeper S端 在磁盘上维护一个事务日志 Transaction log, 记录所有的写入请求。
因为 ZooKeeper S端在返回一个成功的响应之前必须将事务同步到磁盘,所以事务日志也是 ZooKeeper中对性能最重要的组成部分。
可以存储在 znode 中的数据默认最大大小为 1MB.
因此,即使ZooKeeper 的层次结构看起来与文件系统相似,也不应该将其作为一个通用的文件系统。
应该只将它用作少量数据的存储机制,以便为分布式应用程序提供可靠性、可用性和协调。
客户端的请求读取待定 znode 的内容时,读取操作是在客户端所连接的服务器上进行的。
因此,只涉及集合体中的一个服务器,所以读取是快速和可扩展的。
****************************************************************************************************
然而!
为了成功完成写入操作,要求 ZooKeeper 集合体的严格意义上的多数节点都是可用的。
在启动 ZooKeeper 服务时,集合中的某个节点被选举为leader.
当客户端发出一个写入请求时,所连接的服务器会将请求传递给 leader。
此leader 会对 ensamble 的所有节点发出相同的写入请求。如果法定数量 (quorum)成功响应该请求,
那么写入请求被视为成功完成。然后一个成功的返回代码会返回给发起写入请求得客户端。
法定节点数量,应该是奇数。如果有三个节点,失效一个,正常运行。(三个中的两个是严格意义上的多数)
但如果是四个节点,失效两个,则整体失效。(只要有两个节点停机,ZooKeeper服务停止)。
ZooKeeper 集合体中需要多少个节点。读写操作始终从连接到客户端的 ZooKeeper 服务器读取数据。
所以它们的性能不会随着集合体中的服务器数量变化而变化。
但是,尽在写入法定数量的节点时,写入操作才是成功的。
意味着:随着在集合体中的节点数量的增加,写入性能会下降,因为必须将写入内容写入到更多的服务器中,并在更多的服务器之间协调。
三个节点的 ZooKeeper ensamble 支持在一个节点故障的情况下不丢失服务。是最常见的部署。
为了安全起见,可以在集合体中使用5个节点。可以拿出一台服务器进行维护或滚动升级,能够在不中断服务的情况下
承受第二台服务器的意外故障。
注意:
ZooKeeper ensemble 的大小与分布式系统中的节点大小没有关系。
分布式系统中的节点是 ZooKeeper ensemble 的客户端,每个 ZooKeeper 服务器都能够以
可扩展的方式处理大量客户端。
HBase (Hadoop 上的分布式数据库) 依赖于 ZooKeeper 实现区域服务器的领导者选举
和租赁管理。可用 5个节点的 ZooKeeper ensemble 运行有50个节点的大型 HBase 集群。
1. Java Heap Size 概念:堆栈大小。 指 Java 虚拟机的内存大小。在 JVM 中,分配多少内存用于调用对象、函数、和数组。
在底层中, 函数和数组的调用在计算机中。
2. Java 虚拟机在启动的时候会自动设置 Heap size 的值,其初始空间(即:-Xms)是物理内存的 1/64, 最大空间(-Xmx)是物理内存的1/4.
但在实际运行环境中,需要进行内存扩大。可以利用 Jvm 提供的 -Xms,-Xmx等选项进行设置。
- 命令行运行 JAR 包时,-Xms 用于程序初始化时内存栈大小。-Xmx用于设置程序可用的最大内存大小。最大不能超过 1024m.
java -jar jarfile.jar -Xms512m -Xmx1024m
- java 工程中运行时
右击运行的文件 =》“Run as --> Run configuration"-> "Arguments" -> "VM arguments" 内设置初始和最大的Heap Size 大小
3. Java Heap Size 设置不合理的后果
JVM 中如果 98%的时间是用于 GC 且可用的 Heap Size 不足 2% 的将抛出异常信息:
java.lang.OutOfMemoryError: Java heap space
如果Heap Size 设置偏小,除了这些异常信息外,还会法相程序响应速度变慢。GC占用了更多的时间,
而应用程序分配到的执行时间较少。
Heap size 的 -Xms -Xmn 设置不能超过物理内存大小。否则提示
”Error occurred during initialization of VM Could not reserve enough space for object heap"
------------------------------------------------------------------------------------
1.参考 IBM ZooKeeper 相关资料。
2.参考博客园内博客。