这段时间一直在用kettle做数据抽取和报表,写SQL便是家常便饭了,200行+SQL经常要写。甚至写过最长的一个SQL500多行将近600行。这么长的SQL估计大部分人连看的意愿都没有,读起来也比较坑爹,我一般是把这种长SQL分成几个子SQL,测试好了再组装起来。SQL语句写的越多也就越可能出现性能问题。优化SQL可以从很多细节入手,比如加索引,但也不是万能的,当SQL达到一定规模,从结构上优化才是根本解决问题的办法,当然前提是改加的索引已经加了,大部分可以从局部优化的细节已经注意到了。
和往常一样,一个新的需求需要从大概10个表中抽取数据,大部分表数据量都在四十万左右,最多的表有100万左右。说真的数据并不算多,但是这么多遍连接后,如果SQL有的有问题查询效率也是非常低的。一开始我按照自己的思路写了一个SQL,只考虑需求和最短时间内实现。
部分SQL如下图,SQL已经超过200行了:
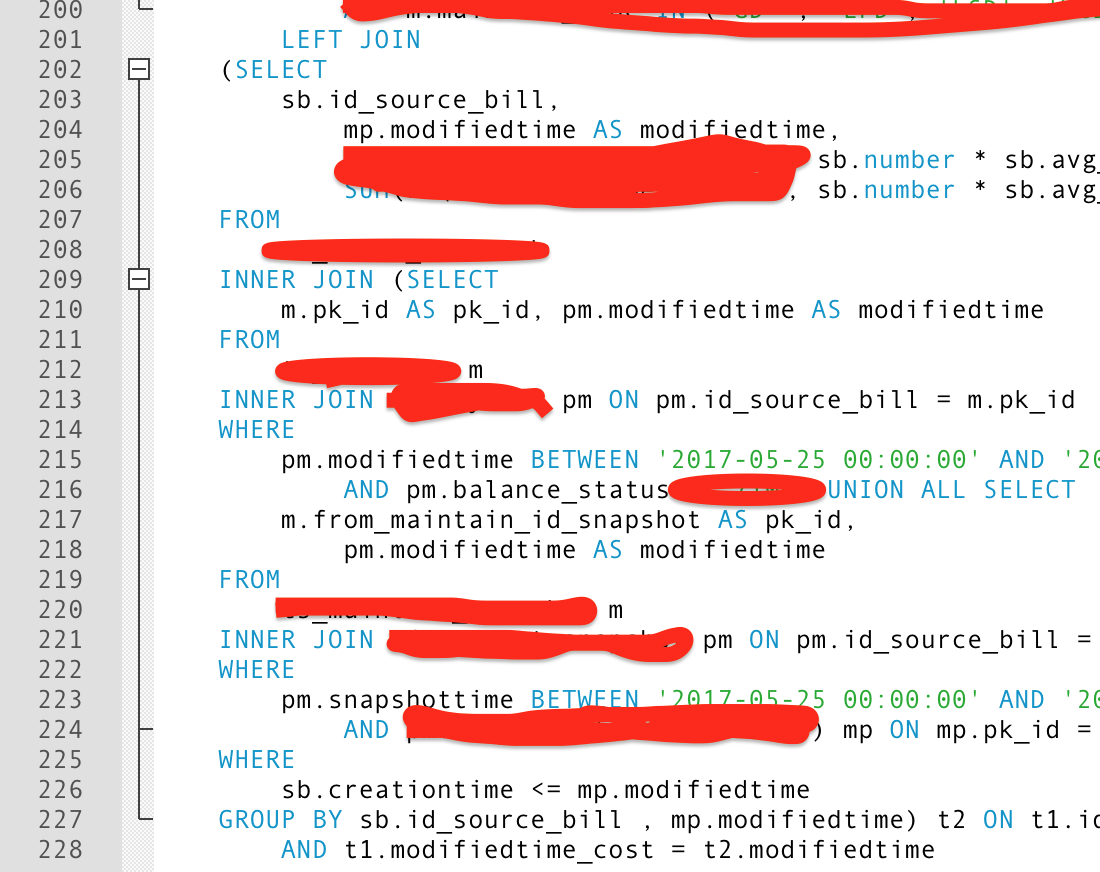
执行结果如下图:
![]()
只查询了38行记录,尽然花了将近10s,感觉已经很慢了。
此时我精简SQL的大概结构如下:
SELECT * FROM (SELECT * FROM A m INNER JOIN B pm ON pm.id_sour = m.pk_id LEFT JOIN (SELECT * FROM C WHERE is_bring IS NULL OR is_bring = 0 GROUP BY id_m) pd ON m.pk_id = pd.id_m LEFT JOIN (SELECT * FROM D sd INNER JOIN E si ON sd.id_ser = si.pk_id GROUP BY sd.id_m) sd ON m.pk_id = sd.id_m WHERE pm.status = '' AND pm.is_del = 0 AND pm.m_time BETWEEN '2017-05-25 00:00:00' AND '2017-05-25 23:59:59' AND m.type IN ('') UNION ALL SELECT * FROM F m INNER JOIN G pm ON pm.id_sour = m.pk_id LEFT JOIN (SELECT * FROM H WHERE is_bring IS NULL OR is_bring = 0 GROUP BY id_m) pd ON m.pk_id = pd.id_m LEFT JOIN (SELECT * FROM I sd INNER JOIN E si ON sd.id_ser = si.pk_id GROUP BY sd.id_m) sd ON m.pk_id = sd.id_m WHERE pm.status = '' AND pm.is_del = 0 AND pm.time BETWEEN '2017-05-25 00:00:00' AND '2017-05-25 23:59:59' AND m.type IN ('') UNION ALL SELECT * FROM F m INNER JOIN G pm ON pm.id_sour = m.pk_id LEFT JOIN (SELECT * FROM H WHERE is_bring IS NULL OR is_bring = 0 GROUP BY id_m) pd ON m.pk_id = pd.id_m LEFT JOIN (SELECT * FROM I sd INNER JOIN E si ON sd.id_ser = si.pk_id GROUP BY sd.id_m) sd ON m.pk_id = sd.id_m WHERE pm.status = '' AND pm.is_del = 0 AND pm.time BETWEEN '2017-05-25 00:00:00' AND '2017-05-25 23:59:59' AND m.type IN ('')) t1 LEFT JOIN (SELECT * FROM J sb INNER JOIN (SELECT m.pk_id AS pk_id, pm.m_time AS m_time FROM A m INNER JOIN B pm ON pm.id_sour = m.pk_id WHERE pm.m_time BETWEEN '2017-05-25 00:00:00' AND '2017-05-25 23:59:59' AND pm.status = '' UNION ALL SELECT m.from_mid_sn AS pk_id, pm.m_time AS m_time FROM F m INNER JOIN G pm ON pm.id_sour = m.pk_id WHERE pm.time BETWEEN '2017-05-25 00:00:00' AND '2017-05-25 23:59:59' AND pm.status = '') mp ON mp.pk_id = sb.id_sour WHERE sb.c_time <= mp.m_time GROUP BY sb.id_sour , mp.m_time) t2 ON t1.id_m = CAST(t2.id_sour AS CHAR) AND t1.m_time_cost = t2.m_time
再精简一下结构如下:
SELECT * FROM (SELECT * FROM A UNION ALL SELECT * FROM B UNION ALL SELECT * FROM C) t1 LEFT JOIN ((SELECT * FROM D) INNER JOIN (SELECT * FROM E UNION ALL SELECT * FROM F) t2 ON t1.id = t2.id) t3 ON t1.tid = t3.id
其中上面的A、B、C、D、E、F都是10个表中多个表的连接查询的结果。其实以上SQL在我们实现的时候就做过简单的优化了,t3其实可以放进t1中分别和A、B、C连接。但其实A、B、C、已经连接好多表了,在分别连接t3性能会产生更多的数据,效率会更低。
由于是数据抽取,数据只是存储到指定的事实表中。因此对效率没太高的要求,一分钟之内都是可以接受的。本来想这样就算了,还有堆事要干。恰好手里有一段类似逻辑的SQL,但是不完全一样。然后我就跑了一下。发现比我写的快一个数量级,大吃一惊之余我决定探索一下原因。
精简优化过的SQL代码如下:
SELECT * FROM (SELECT * FROM A m INNER JOIN (SELECT * FROM B where is_del = 0 AND m_time BETWEEN '2017-05-25 00:00:00' AND '2017-05-25 23:59:59') pm ON pm.id_sour = m.pk_id WHERE pm.status = '' AND pm.is_del = 0 AND pm.m_time BETWEEN '2017-05-25 00:00:00' AND '2017-05-25 23:59:59' AND m.type IN ('') UNION ALL SELECT * FROM F m INNER JOIN (SELECT * FROM G where is_del = 0 AND m_time BETWEEN '2017-05-25 00:00:00' AND '2017-05-25 23:59:59') pm ON pm.id_sour = m.pk_id WHERE pm.status = '' AND pm.is_del = 0 AND pm.s_time BETWEEN '2017-05-25 00:00:00' AND '2017-05-25 23:59:59' AND m.type IN ('') UNION ALL SELECT * FROM F m INNER JOIN (SELECT * FROM G where is_del = 0 AND m_time BETWEEN '2017-05-25 00:00:00' AND '2017-05-25 23:59:59') pm ON pm.id_sour = m.pk_id WHERE pm.status = '' AND pm.is_del = 0 AND pm.s_time BETWEEN '2017-05-25 00:00:00' AND '2017-05-25 23:59:59' AND m.type IN ('')) mm LEFT JOIN (SELECT * FROM J sb INNER JOIN (SELECT m.pk_id AS pk_id, pm.m_time AS m_time FROM A m INNER JOIN B pm ON pm.id_sour = m.pk_id WHERE pm.status = '' AND pm.is_del = 0 AND m.type IN ('') AND m.is_del = 0 AND m.is_mig = 0 AND pm.m_time BETWEEN '2017-05-25 00:00:00' AND '2017-05-25 23:59:59' UNION ALL SELECT m.from_mid_sn AS pk_id, pm.m_time AS m_time FROM F m INNER JOIN (SELECT * FROM G where is_del = 0 AND m_time BETWEEN '2017-05-25 00:00:00' AND '2017-05-25 23:59:59') pm ON pm.id_sour = m.pk_id WHERE pm.status = '' AND pm.is_del = 0 AND m.type IN ('') AND m.is_del = 0 AND m.is_mig = 0 AND pm.s_time BETWEEN '2017-05-25 00:00:00' AND '2017-05-25 23:59:59') mp ON mp.pk_id = sb.id_sour WHERE sb.c_time <= mp.m_time GROUP BY sb.id_sour , mp.m_time) cost ON cost.id_sour = mm.id_m AND cost.m_time = mm.m_time_cost LEFT JOIN (SELECT * FROM D sd INNER JOIN E si ON sd.id_ser = si.pk_id INNER JOIN (SELECT DISTINCT * FROM A m INNER JOIN B pm ON pm.id_sour = m.pk_id WHERE pm.status = '' AND pm.is_del = 0 AND m.type IN ('') AND m.is_del = 0 AND m.is_mig = 0 AND pm.m_time BETWEEN '2017-05-25 00:00:00' AND '2017-05-25 23:59:59') ms ON sd.id_m = ms.pk_id GROUP BY sd.id_m UNION ALL SELECT * FROM I sd INNER JOIN E si ON sd.id_ser = si.pk_id INNER JOIN (SELECT DISTINCT m.pk_id, from_mid_sn, pm.m_time FROM F m INNER JOIN G pm ON pm.id_sour = m.pk_id WHERE pm.status = '' AND pm.is_del = 0 AND m.type IN ('') AND m.is_del = 0 AND m.is_mig = 0 AND pm.s_time BETWEEN '2017-05-25 00:00:00' AND '2017-05-25 23:59:59') ms ON sd.id_m = ms.pk_id GROUP BY sd.id_m) ser ON ser.id_m = mm.id_m AND ser.m_time = mm.m_time_cost LEFT JOIN (SELECT * FROM C pd INNER JOIN (SELECT DISTINCT m.pk_id, pm.m_time FROM A m INNER JOIN B pm ON pm.id_sour = m.pk_id WHERE pm.status = '' AND pm.is_del = 0 AND m.type IN ('') AND m.is_del = 0 AND m.is_mig = 0 AND pm.m_time BETWEEN '2017-05-25 00:00:00' AND '2017-05-25 23:59:59') ms ON ms.pk_id = pd.id_m WHERE is_bring IS NULL OR is_bring = 0 GROUP BY pd.id_m , ms.m_time UNION ALL SELECT * FROM H pd INNER JOIN (SELECT DISTINCT m.pk_id, pm.m_time, from_mid_sn FROM F m INNER JOIN G pm ON pm.id_sour = m.pk_id WHERE pm.status = '' AND pm.is_del = 0 AND m.type IN ('') AND m.is_del = 0 AND m.is_mig = 0 AND pm.s_time BETWEEN '2017-05-25 00:00:00' AND '2017-05-25 23:59:59') ms ON ms.pk_id = pd.id_m WHERE is_bring IS NULL OR is_bring = 0 GROUP BY pd.id_m) part ON part.id_m = mm.id_m AND part.m_time = mm.m_time_cost
运行此代码结果如下:

同样的结果,效率整整提升了一个数量级,哇咔咔。。。其实写出之前让我参考的效率较高的SQL的一位妹子。在我公司,大家称之为SQL女神,果然名不虚传。佩服之余我要要要学习一下。
仔细分析以上优化过的SQL,其实是巧妙的使用了某种规律,我称之为---SQL分配率和结合律。
最左侧的子SQL(或者临时表:mm)如下:
SELECT * FROM A m INNER JOIN (SELECT * FROM B where is_del = 0 AND m_time BETWEEN '2017-05-25 00:00:00' AND '2017-05-25 23:59:59') pm ON pm.id_sour = m.pk_id WHERE pm.status = '' AND pm.is_del = 0 AND pm.m_time BETWEEN '2017-05-25 00:00:00' AND '2017-05-25 23:59:59' AND m.type IN ('') UNION ALL SELECT * FROM F m INNER JOIN (SELECT * FROM G where is_del = 0 AND m_time BETWEEN '2017-05-25 00:00:00' AND '2017-05-25 23:59:59') pm ON pm.id_sour = m.pk_id WHERE pm.status = '' AND pm.is_del = 0 AND pm.s_time BETWEEN '2017-05-25 00:00:00' AND '2017-05-25 23:59:59' AND m.type IN ('') UNION ALL SELECT * FROM F m INNER JOIN (SELECT * FROM G where is_del = 0 AND m_time BETWEEN '2017-05-25 00:00:00' AND '2017-05-25 23:59:59') pm ON pm.id_sour = m.pk_id WHERE pm.status = '' AND pm.is_del = 0 AND pm.s_time BETWEEN '2017-05-25 00:00:00' AND '2017-05-25 23:59:59' AND m.type IN ('')
其实38条数据的结果,在以上子SQL就已经确定了,因此后面的LEFT JOIN或INNER JOIN,JOIN的数据都会比较少,效率自然高。相对于优化前的写法,以上子SQL各自还连接了一堆相同的表。现在把这堆相同的表提到最外面做一次连接。这里体现的是SQL结合律。
总结:当SQL规模比较庞大时,良好的SQL结构能大大提升执行的效率。并且SQL的优化也不是一蹴而就,也是一个循序渐进不断尝试的过程。以上SQL不一定就是最优,此处并没有谈SQL语法最佳使用细节。具体可参考以下链接。