本书PDF版链接:https://pan.baidu.com/s/1_Fblc4AfKgOMc-jd9flI8A 提取码:obwe
第一章:问题建模

ps:注意精准率与准确率是有区别的,PR曲线越靠右上角越好,ROC曲线越靠坐标的左上角越好,AUC的值越大(接近1)越好。
第二章:特征工程

特征工程与模型二者有时候是此消彼长的,复杂模型在一定程度上减少特征工程需要做的工作。例如:对于线性模型,需要将类别变量进行独热编码等处理。但是对于复杂一些的模型,比如树模型,可以直接处理类别变量。对更复杂的深度学习,模型可以自动进行特征表示;再例如:数值特征,对于线性回归、逻辑回归等,其对输入特征的大小很敏感,对于这种光滑函数建模,需要数值特征归一化处理。而对于随机森林、梯度提升树就没必要归一化了。因此,以上讲的特征工程处理有时候要依据模型而言。
特征选择中的过滤方法不需要结合机器学习算法(模型),封装方法直接使用机器学习算法评估特征子集的效果。过滤方法不需要机器学习算法验证,效率高简单;封装方法使用预先定义的机器学习算法评估特征选取的质量,效率低;嵌入方法说白了感觉就是在模型中进行特征选择,也就是将特征选择、机器学习算法、模型效果全融合一起。使用工具包,书中有介绍。
第三章:常用模型

第二部分,好像不是SVM,场感知因子分解机(没怎么看)。第三部分,梯度提升树(GBDT),详细一点看这。书中有GBDT与XGBOOST的简单公式推导。

第四章:模型融合

其实我感觉集成学习算法就是模型的融合。集成学习中主要分为:Bagging(并行)和 Boosting (串行)。模型融合肯定要求模型不同,相同则没有意义,这里的不同要么是用不同的算法,要么是相同算法,但是输入不同。粗浅的感觉,stacking与Bagging类似,Bagging是并行,将不同分类(回归)器的结果进行融合后输出。stacking比它多一步,不是将不同分类器的结果融合,而是再经过一个分类器后输出。
以上是此书的第一部分,算是基础,下面5-7章是第二部分,数据挖掘。
第五章:用户画像

用户画像就是根据有关你的数据,对你贴这种标签。标签得来大致有两种:一,经过对大数据统计分析得;二,通过机器学习训练模型(此书介绍的是这种)。书中5.2.1数据挖掘整体架构可以看看,介绍了美团的实际的大致操作过程。
第六章:POI实体链接

第七章:评论挖掘

题外话,好像网页版美团里的酒店看不到用户评价标签,手机版可以。
第三部分是搜索与推荐,从第8章到第10章。
第八章:O2O场景下的查询理解与用户引导

第九章:O2O场景下排序的特点

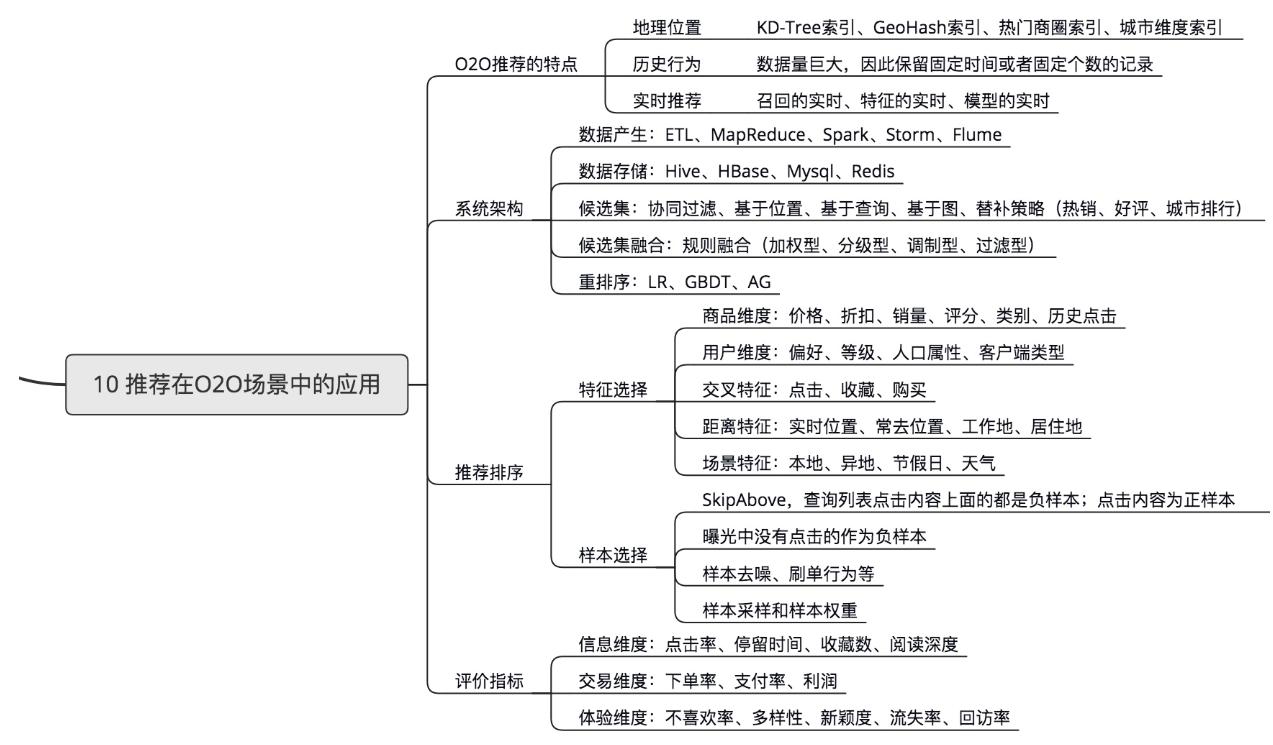
第十章:推荐在O2O场景中的应用
第四部分:计算广告,从第十一章到第十二章。
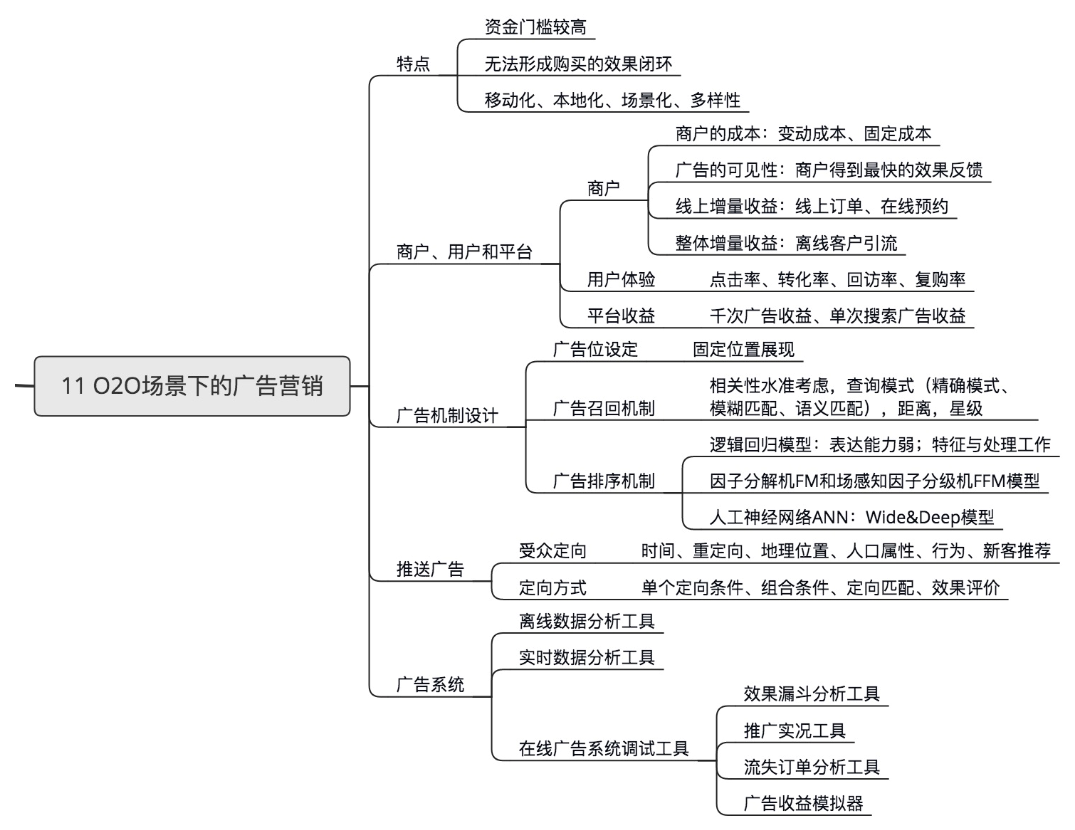
第十一章:O2O场景下的广告营销
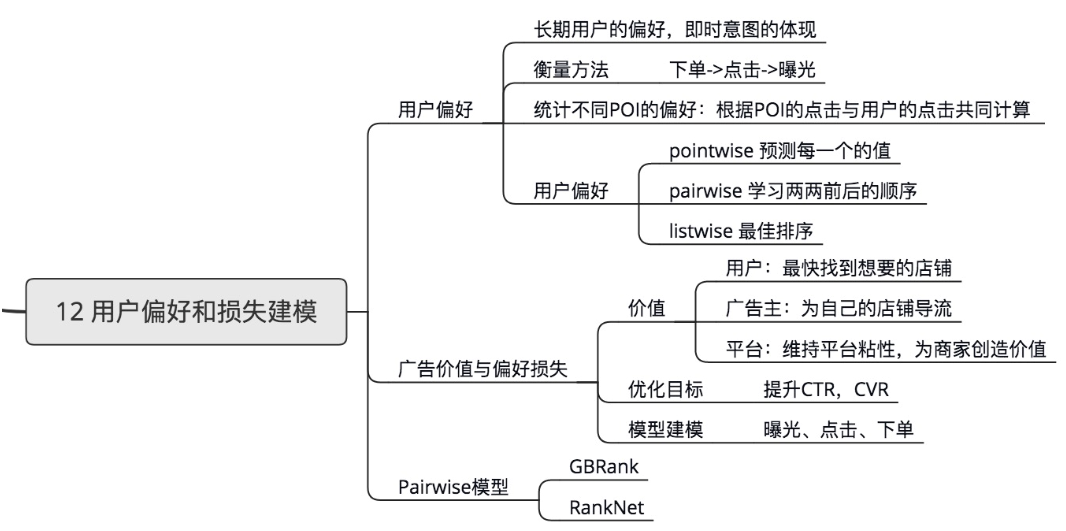
第十二章:用户偏好和损失建模
第五部分:深度学习,从第13章到第14章
第十三章:深度学习概述

第十四章:深度学习在文本领域的应用
