定义
Celery is a simple, flexible, and reliable distributed system to process vast amounts of messages, while providing operations with the tools required to maintain such a system.
It’s a task queue with focus on real-time processing, while also supporting task scheduling.
解读:官网上它把自己定义为Distributed Task Queue,但我觉得把它称为Distributed Task Process Framework更为方便理解。
简单地说,Celery是分布式(异步)任务队列。
架构如下:
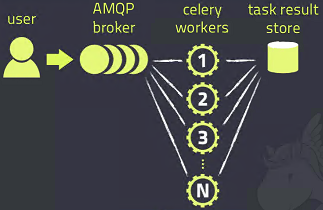
Celery的架构由三部分组成
- 消息中间件(
message broker),可集成第三方如RabbitMQ - 任务执行单元(
worker) - 任务执行结果存储(
task result store),可集成第三方如Redis
使用场景
- 异步任务
- 将耗时耗资源的任务提交给Celery去异步执行,比如发送短信/邮件、消息推送、音视频处理等等
- 将需要分布式执行的任务交给Celery去执行,比如batch post process处理
- 定时任务
- 定时执行某件事情,比如每天数据统计
演变
1阶段
传统的消息中间件(broker)只负责消息的转发,系统受到了消息之后,一般会立刻处理。如下:
public void onMessage(Message message) {
doTaskA(message);
}
2阶段
如果task A非常耗时(IO很慢),可能会造成消息积压。
为了改善这个问题,有一个方法:创建一个线程单独处理task A,同时,继续接收新的message。
于是,我们创建了一个大小为10的线程池,同一时间,这台机器上会跑10个task A。
thread 1: task A
thread 2: task A
thread 3: task A
...
thread 10: task A
示例代码如下:
ForkJoinPool forkJoinPool = new ForkJoinPool(10);
public void onMessage(Message message) {
List<Future<Boolean>> futures = new ArrayList<>();
futures.add(forkJoinPool.submit(()-> {
doTaskA(message);
}
}
3阶段
慢慢地,业务越来越多,我们发现,10个线程不够用了,于是我们尝试设置30个线程。
但是,我们发现,单机CPU的处理速度跟不上了。
要想解决这个问题,要么换一个更好的机器,要么采取分布式架构。长远看,后者是更加经济实惠的。
于是,我们创建了一个处理task A的集群,将所有task分发给这个集群处理。
tasks -> cluster -> node 1: task A
-> node 2: task A
-> node 3: task A
...
需要注意的是,这里的task分发,还是需要通过消息中间件。绕了一圈,发现又转了回来。
其实,之前我们造的一个个轮子,和Celery干的,是一件事情。
分布式
Celery的分布式实际包含两个层次:
- Distribute work on a given machine across all CPUs
- 默认情况下,一台机器上worker的数量和机器的CPU个数一致
- 命令:
celery -A tasks worker --loglevel=INFO --concurrency=5
- Distribute work to many machines
- 可以手动指定所有worker的broker;也可以不指定,由系统默认配置一个
- 查看当前处于活跃状态的worker和task:
celery -A tasks inspect active
-> Celery分布式的理解 https://blog.csdn.net/xsj_blog/article/details/70181159?utm_source=blogxgwz8
安装
- 首先,肯定要有Python
- 其次,需要消息中间件模块 (这里用的是redis提供的服务)
- 最后,安装Celery
// install docker (as a container for redis)
pip install redis
pip install celery
实战
首先,要起broker。(这里用的是redis)
docker run -d -p 6379:6379 redis
然后,创建一个worker,我们命名为task.py。这个task做了一件事,就是把输入的两个数累加,返回和。
from celery import Celery
app = Celery('tasks', broker='redis://localhost')
@app.task
def add(x, y):
return x + y
然后,就可以把这个worker启动起来:
celery -A tasks worker --loglevel=info
现在,环境已经准备好了。下面,就可以创建一些work,丢给worker去执行。从Python cmd line,输入以下代码:
>>> from tasks import add
>>> add.delay(4, 4)
返回值是一个代码编号 -> <AsyncResult: 4186b15e-7fc8-49d4-a864-e5ae2ae9c3de>
通过这个代码编号,我们可以查询到最终的结果。
Celery server log如下:

集群
Celery起cluster非常方便,就用之前的命令就可以。进阶一点,可以用-n为这个worker起一个名字,方便识别,如下:
celery -A tasks worker --loglevel=info -n work1@%n
当一个node启动时,它会自动搜索附近的node,并sync。

为了便于测试,我们给task设置3s的sleep时间,然后连续在client端发出6个指令。client端迅速返回了6个AsyncResult。
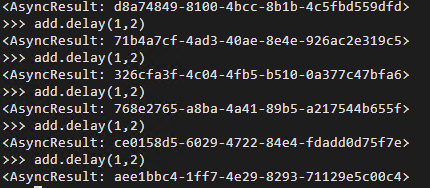
然后,我们去看两个worker端的log,发现,一个接收了2个任务,一个接收了4个任务。
work 1

worke 2

参考
- 【DOC】Celerys中文手册 https://www.celerycn.io/ru-men/celery-jian-jie
- 【DOC】First Steps with Celery https://docs.celeryproject.org/en/stable/getting-started/first-steps-with-celery.html
- Celery简介与实践 https://www.jianshu.com/p/620052aadbff
- Celery最佳实践 https://www.cnblogs.com/xiaowangba/p/6313741.html