1、杂语
近期课程需要爬取淘宝、天猫商品评论信息,进行数据挖掘分析和情感分析。在网上查找相关资料,翻阅一些博客和csdn文章,对淘宝天猫商品评论爬虫有了一些了解,并且成功爬取到需要的数据。因此,在此对这几天的学习做个总结,也给有同样需求的朋友一点参考。
2、目的和方法
2.1 目的
本文目的很明确,爬取天猫(淘宝)中某个商品的评论信息,信息包括商品的型号、用户评论(主要分析这两个信息)。
商品链接地址:

2.2 爬虫方法
爬虫说简单也简单,说难也难。掌握了爬虫程序的逻辑,你就能实现爬虫,当然这一切还需要你有相关知识作为基石支撑。爬虫本质上是在模仿人的操作,请求网页,获取数据。爬虫天猫(淘宝)商品评论的这个过程,其实与你查看天猫(淘宝)评论的过程是一致的。下面具体介绍每一步操作,我会尽量介绍的详细一些:
step1:获取cookie信息与评论url地址
解释:cookie是用目标网站返回的验证密钥,当你申请访问某个网站时,该网站会核对你的cookie,验证成功才会将该网站的数据传输给你。因此,如果我们想要使用代码访问天猫商品评论,就需要天猫网站发送给我们的cookie,模拟登陆。
1、登陆天猫(账户、密码登陆)

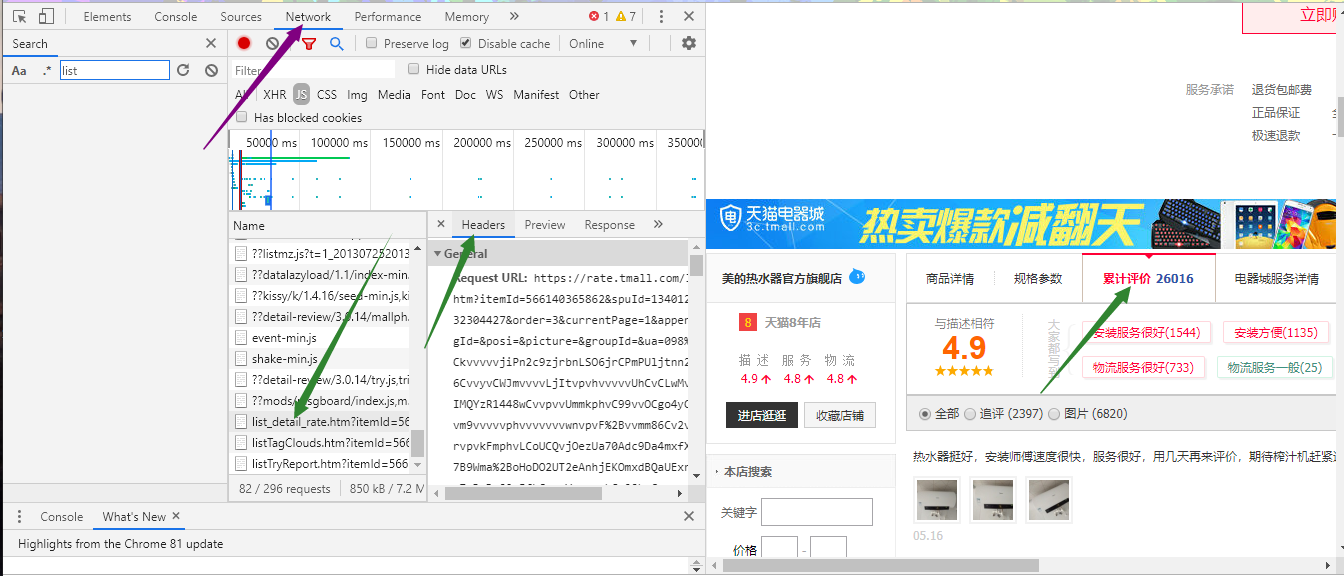
2、选中某款商品,如本文中选择了美的的一款热水器。然后点击右键(Google浏览器右键)检查,查看网页源码。

3、在network中找到list_detail_rate.htm文件,并在该文件中抓取header包。具体操作为:检查后,得到出现下面页面,点击network,选择显示js文件,然后在name中寻找list_detail_rate.htm文件,查询一遍,如果发现没有,则点击刷新,在点击累计评论,name中就会自动加载出list_detail_rate.htm文件。PS:如果还没有找到,在评论里面翻页,这样name中一定2会出现该文件。
4、抓取cookie信息
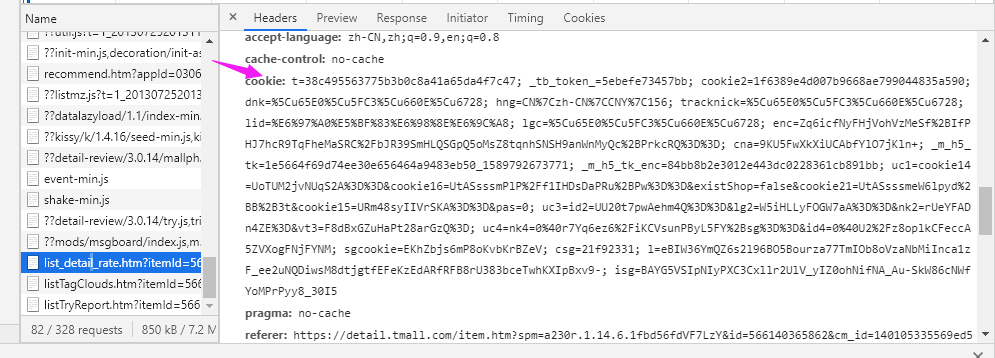
在上一步中已经抓取到list_detail_rate.htm文件的header,在header中包含了许多信息,包括cookie,每一页评论url地址,以及你的浏览器信息。但是我们暂时只需要cookie信息和评论的url地址。
如下图:该url地址即为该页评论的url地址,分析其组成我们很容易就可以发现,该url地址中的Page控制页数。因此,每一页评论的url地址我们就能确定了。下拉即可发现,cookie居然也在这里面。粘贴它,备用。

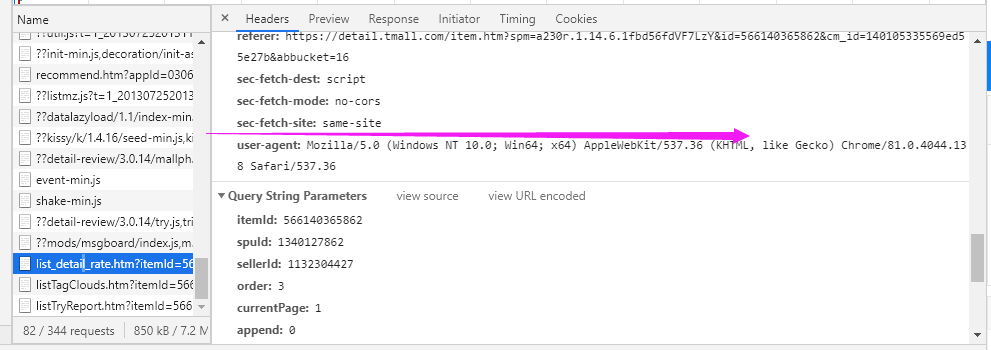
step2:获取请求头信息user-agent
方法一:网上直接搜索请求头user-agent,随意粘贴一个就能够使用。
方法二:在上一步的header里面下拉,找到user-agent,粘贴即可。
step3:查看评论数据
继续查看list_detail_rata.htm文件,点击preview,再将数据展开,可以发现jsonp文件中包含了我们需要的评论数据信息,包括商品评论、评论时间,有无追加,商品型号、用户名等信息。如下图
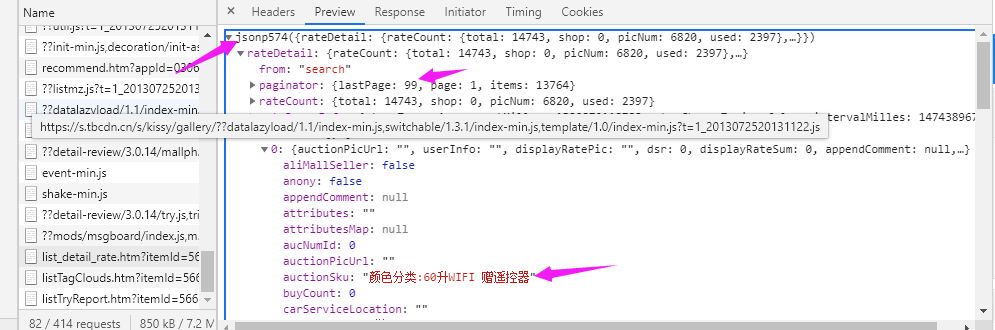

从这两张图我们能确定,我们只需要请求到这个文件,在对这个文件解析即可获得我们需要的商品评论。从中我们能得到商品评论的页数,99页、商品评论数据,以及所评论的商品型号。下面只需要编写程序提取其中的信息即可。
step4:编写程序
1、导入库文件,requests,re,pd,time
#导入库文件 import requests from bs4 import BeautifulSoup as bs4 import time import re import pandas as pd
2、建立请求头(headers),包含cookie、user-agent,referer(商品链接)
def get_content(url_lists):
headers = { #cookie网络验证,需要先登陆,获取登陆以后的网络验证cookie, 'cookie': 't=38c495563775b3b0c8a41a65da4f7c47; _tb_token_=5ebefe73457bb; cookie2=1f6389e4d007b9668ae799044835a590; dnk=%5Cu65E0%5Cu5FC3%5Cu660E%5Cu6728; hng=CN%7Czh-CN%7CCNY%7C156; tracknick=%5Cu65E0%5Cu5FC3%5Cu660E%5Cu6728; lid=%E6%97%A0%E5%BF%83%E6%98%8E%E6%9C%A8; lgc=%5Cu65E0%5Cu5FC3%5Cu660E%5Cu6728; enc=Zq6icfNyFHjVohVzMeSf%2BIfPHJ7hcR9TqFheMaSRC%2FbJR39SmHLQSGpQ5oMsZ8tqnhSNSH9anWnMyQc%2BPrkcRQ%3D%3D; cna=9KU5FwXkXiUCAbfYlO7jKln+; _m_h5_tk=1e5664f69d74ee30e656464a9483eb50_1589792673771; _m_h5_tk_enc=84bb8b2e3012e443dc0228361cb891bb; uc1=cookie14=UoTUM2jvNUqS2A%3D%3D&cookie16=UtASsssmPlP%2Ff1IHDsDaPRu%2BPw%3D%3D&existShop=false&cookie21=UtASsssmeW6lpyd%2BB%2B3t&cookie15=URm48syIIVrSKA%3D%3D&pas=0; uc3=id2=UU20t7pwAehm4Q%3D%3D&lg2=W5iHLLyFOGW7aA%3D%3D&nk2=rUeYFADn4ZE%3D&vt3=F8dBxGZuHaPt28arGzQ%3D; uc4=nk4=0%40r7Yq6ez6%2FiKCVsunPByL5FY%2Bsg%3D%3D&id4=0%40U2%2Fz8oplkCFeccA5ZVXogFNjFYNM; _l_g_=Ug%3D%3D; unb=2562036378; cookie1=Vv1zqw8QCKeLxmtxWLfD1h937JwOrbk70nwWm1OBXEY%3D; login=true; cookie17=UU20t7pwAehm4Q%3D%3D; _nk_=%5Cu65E0%5Cu5FC3%5Cu660E%5Cu6728; sgcookie=EKhZbjs6mP8oKvbKrBZeV; sg=%E6%9C%A88b; csg=21f92331; l=eBIW36YmQZ6s21ejBO5Nlurza77OBQRfGsPzaNbMiIHca6CVsFi_tNQDiUeH-dtjgtCEietzEdARfRH98Ezd0ZqhuJ1REpZZnxvO.; isg=BMHBO7ure9P4wJfmuEBqzsb80A3b7jXgde5qciMUQEhlCuXcaz-isPtM7H5MAs0Y', #商品的链接地址,每个商品链接不同 'referer': 'https://detail.tmall.com/item.htm?spm=a230r.1.14.6.1fbd56fdVF7LzY&id=566140365862&cm_id=140105335569ed55e27b&abbucket=16', #电脑浏览器信息浏览器,这个信息是固定的, 'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11', }
3、获取评论url地址,根据之前发现的商品评论url地址特点,构建函数。忘记了可以看看step1的第四步。
#获取评论url地址 def get_url(num): page_url = [] #list_detail_rate.htm文件中保存了商品评论信息,因此需求请求该url地址, # 这个地址的寻找方法是:首先,确定你要爬虫的页面,点击右键的检查, # 然后再点击network,在里面寻找list_detail_rate.htm包文件,在该文件的headers信息中可以找到url信息 urlfirst = 'https://rate.tmall.com/list_detail_rate.htm?itemId=566140365862&spuId=1340127862&sellerId=1132304427&order=3¤tPage=' urllast = '&append=1&content=1&tagId=&posi=&picture=0&groupId=&ua=098%23E1hve9vovZ9vUvCkvvvvvjiPn2c96jEbPFdW0jrCPmP90jl8Ps5yAjinR2FpAjEb9phv8cMGclG7zYswzpj87kdoE93ukbj2J1%2BhTKuUAbt39JW2g08Ly0eEpIEmdphvmpvh9IbzYAmwR86CvvyvCv4m%2Bfh9FWVrvpvEvvCZvli4UU2pRphvCvvvvvmCvpvWzC1EOUFNznswjo143QhvCvvhvvm5vpvhvvmv9FyCvvpvvvvv2QhvCvvvMM%2FtvpvIvvvvvhCvvvvvvUUFphvUqvvv9krvpvQvvvmm86CvmVWvvUUdphvUIgyCvvOUvvVvJheivpvUvvmvR7I4ueWEvpCWmUDfvvwdiNLh1CeXaHFXS47BhC3qVUcnDOmOjLEc6acEKBmAVAdvaNoxdX3l8bmxfwoOd56OfwLvaB4AVAdvaNoxdX31bbmxfJmK59hCvvOvCvvvphmCvpvWzC1EOUFSznswSpl4RphvCvvvvvvtvpvhvvvvvv%3D%3D&itemPropertyId=&itemPropertyIndex=&userPropertyId=&userPropertyIndex=&rateQuery=&location=&needFold=0&_ksTS=1589850461438_1131&callback=jsonp1132' for i in range(1,num,1): url = urlfirst+str(i)+urllast page_url.append(url) return page_url
4、请求数据,使用requests库,requests参数,url地址为目标地址,headers为传输的验证信息,传输回来为html源码,需要以text格式查看。
comment = [] # 定义评论字段 auctionSku = [] # 定义热水器型号信息 for i in range(0,len(url_lists)): print('正在爬取第{}页评论'.format(str(i+1))) #请求数据 data = requests.get(url_lists[i],headers = headers).text time.sleep(10) #数据提取 comment.extend(re.findall('rateContent":"(.*?)"fromMall"', data)) auctionSku.extend((re.findall('"auctionSku":"(.*?)"',data)))
5、数据保存,保存为数表形式,存储格式为xls。
#定义数表 com = pd.DataFrame() com['型号'] = auctionSku com['评论'] = comment print(com) com.to_excel('商品评论数据.xls')
6、主函数
if __name__ == '__main__': num = 99 #页数,商品总页数为99页 url_list = get_url(num) get_content(url_list)
3、完整程序
# -*- coding:utf-8 -*-
#大明王
#天猫美的热水器商品评论爬虫 #美的电热水器电家用卫生间洗澡淋浴60/50升小型储水式即热一级TK1,型号:F6021-TK1(HEY) #导入库文件 import requests from bs4 import BeautifulSoup as bs4 import time import re import pandas as pd #获取评论url地址 def get_url(num): page_url = [] #list_detail_rate.htm文件中保存了商品评论信息,因此需求请求该url地址, # 这个地址的寻找方法是:首先,确定你要爬虫的页面,点击右键的检查, # 然后再点击network,在里面寻找list_detail_rate.htm包文件,在该文件的headers信息中可以找到url信息 urlfirst = 'https://rate.tmall.com/list_detail_rate.htm?itemId=566140365862&spuId=1340127862&sellerId=1132304427&order=3¤tPage=' urllast = '&append=1&content=1&tagId=&posi=&picture=0&groupId=&ua=098%23E1hve9vovZ9vUvCkvvvvvjiPn2c96jEbPFdW0jrCPmP90jl8Ps5yAjinR2FpAjEb9phv8cMGclG7zYswzpj87kdoE93ukbj2J1%2BhTKuUAbt39JW2g08Ly0eEpIEmdphvmpvh9IbzYAmwR86CvvyvCv4m%2Bfh9FWVrvpvEvvCZvli4UU2pRphvCvvvvvmCvpvWzC1EOUFNznswjo143QhvCvvhvvm5vpvhvvmv9FyCvvpvvvvv2QhvCvvvMM%2FtvpvIvvvvvhCvvvvvvUUFphvUqvvv9krvpvQvvvmm86CvmVWvvUUdphvUIgyCvvOUvvVvJheivpvUvvmvR7I4ueWEvpCWmUDfvvwdiNLh1CeXaHFXS47BhC3qVUcnDOmOjLEc6acEKBmAVAdvaNoxdX3l8bmxfwoOd56OfwLvaB4AVAdvaNoxdX31bbmxfJmK59hCvvOvCvvvphmCvpvWzC1EOUFSznswSpl4RphvCvvvvvvtvpvhvvvvvv%3D%3D&itemPropertyId=&itemPropertyIndex=&userPropertyId=&userPropertyIndex=&rateQuery=&location=&needFold=0&_ksTS=1589850461438_1131&callback=jsonp1132' for i in range(1,num,1): url = urlfirst+str(i)+urllast page_url.append(url) return page_url def get_content(url_lists): headers = { #cookie网络验证,需要先登陆,获取登陆以后的网络验证cookie,需要更改 'cookie': 't=38c495563775b3b0c8a41a65da4f7c47; _tb_token_=5ebefe73457bb; cookie2=1f6389e4d007b9668ae799044835a590; dnk=%5Cu65E0%5Cu5FC3%5Cu660E%5Cu6728; hng=CN%7Czh-CN%7CCNY%7C156; tracknick=%5Cu65E0%5Cu5FC3%5Cu660E%5Cu6728; lid=%E6%97%A0%E5%BF%83%E6%98%8E%E6%9C%A8; lgc=%5Cu65E0%5Cu5FC3%5Cu660E%5Cu6728; enc=Zq6icfNyFHjVohVzMeSf%2BIfPHJ7hcR9TqFheMaSRC%2FbJR39SmHLQSGpQ5oMsZ8tqnhSNSH9anWnMyQc%2BPrkcRQ%3D%3D; cna=9KU5FwXkXiUCAbfYlO7jKln+; _m_h5_tk=1e5664f69d74ee30e656464a9483eb50_1589792673771; _m_h5_tk_enc=84bb8b2e3012e443dc0228361cb891bb; uc1=cookie14=UoTUM2jvNUqS2A%3D%3D&cookie16=UtASsssmPlP%2Ff1IHDsDaPRu%2BPw%3D%3D&existShop=false&cookie21=UtASsssmeW6lpyd%2BB%2B3t&cookie15=URm48syIIVrSKA%3D%3D&pas=0; uc3=id2=UU20t7pwAehm4Q%3D%3D&lg2=W5iHLLyFOGW7aA%3D%3D&nk2=rUeYFADn4ZE%3D&vt3=F8dBxGZuHaPt28arGzQ%3D; uc4=nk4=0%40r7Yq6ez6%2FiKCVsunPByL5FY%2Bsg%3D%3D&id4=0%40U2%2Fz8oplkCFeccA5ZVXogFNjFYNM; _l_g_=Ug%3D%3D; unb=2562036378; cookie1=Vv1zqw8QCKeLxmtxWLfD1h937JwOrbk70nwWm1OBXEY%3D; login=true; cookie17=UU20t7pwAehm4Q%3D%3D; _nk_=%5Cu65E0%5Cu5FC3%5Cu660E%5Cu6728; sgcookie=EKhZbjs6mP8oKvbKrBZeV; sg=%E6%9C%A88b; csg=21f92331; l=eBIW36YmQZ6s21ejBO5Nlurza77OBQRfGsPzaNbMiIHca6CVsFi_tNQDiUeH-dtjgtCEietzEdARfRH98Ezd0ZqhuJ1REpZZnxvO.; isg=BMHBO7ure9P4wJfmuEBqzsb80A3b7jXgde5qciMUQEhlCuXcaz-isPtM7H5MAs0Y', #商品的链接地址,每个商品链接不同需要更改 'referer': 'https://detail.tmall.com/item.htm?spm=a230r.1.14.6.1fbd56fdVF7LzY&id=566140365862&cm_id=140105335569ed55e27b&abbucket=16', #电脑浏览器信息浏览器,这个信息是固定的,可以不变 'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11', } comment = [] # 定义评论字段 auctionSku = [] # 定义热水器型号信息 for i in range(0,len(url_lists)): print('正在爬取第{}页评论'.format(str(i+1))) #请求数据 data = requests.get(url_lists[i],headers = headers).text time.sleep(10) #数据提取 comment.extend(re.findall('rateContent":"(.*?)"fromMall"', data)) auctionSku.extend((re.findall('"auctionSku":"(.*?)"',data))) #定义数表 com = pd.DataFrame() com['型号'] = auctionSku com['评论'] = comment print(com) com.to_excel('商品评论数据.xls') if __name__ == '__main__': num = 99 #页数 url_list = get_url(num) get_content(url_list)
4、总结
万事开头难,加油,致爱学习,努力坚强的你。see you
好书推荐:《你当像鸟飞往你的山》