1 grep 用法:
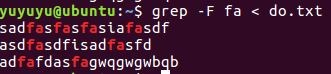
grep -F fa 找含有fa字符的字符串
yuyuyu@ubuntu:~$ grep -F fa < do.txt
grep -i fa 忽略大小写找含有fa字符的字符串
yuyuyu@ubuntu:~$ grep -i fa < do.txt 
grep -q fa 安安静静的找含有fa字符的字符串,没显示结果
yuyuyu@ubuntu:~$ grep -q fa < do.txt

2 unix 使用正则表达式的例子
匹配文本行 grep
改变输入流用sed
字符串处理的程序语言 awk Icon Perl Python Ruby Tcl
文件查看程序 more page pg
文本编辑器 vi vim jove jed emacs
3 正则表达式中的元字符(meta)用法,即特殊字符。
. 匹配任何的单个字符
grep “.” < do.txt


* 匹配任意字符的任意长度, 放第一位则无意义


^ 匹配字符串开头,或者行开头
yuyuyu@ubuntu:~$ grep "^sad" <do.txt

$ 匹配字符串结尾, 或者行结尾
yuyuyu@ubuntu:~$ grep "qb$" <do.txt

[ ] 方括号表达式,匹配方括号中的任意字符
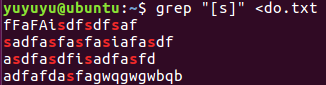
[a-z] 匹配a-z的所有字符

[^z] 不匹配z字符

{ } 前侧正则表达式结果重现n次
{n,} 前侧正则表达式结果至少重现n次
{n,m} 区间表达式, 匹配它之前的字符重现的次数区间, n至少是0 ,m至少是255

4 [: :]字符集
grep "[[:print:]]" <do.txt 可显示字符
grep "[[:space:]]" <do.txt 空白字符
grep "[[:xdigit:]]" <do.txt 16进制数
grep "[[:upper:]]" <do.txt 大小字母
grep "[[:lower:]]" <do.txt 小写字母
grep "[[:digit:]]" <do.txt 数字字符
grep "[[:blank:]]" <do.txt 空格与定位字符
grep "[[:alpha:]]" <do.txt 字母字符
grep "[[:alnum:]]" <do.txt 数字字符
grep "[[:punct:]]" <do.txt 标点符号
5 排序符 [. .]
6 等价字符集[= =]
7 后向引用,就 是先写个表达式 , 接着能用1~9 来引用它
() 模式存储, 会存在特殊空间
一开始看了觉得很难,怎么测试都没找到显示结果。
这里通过3张图片来了解:
grep "(adf)" <do.txt 能找出adf开头的字符串
以第一行的 “adfasfas” 来引入引用
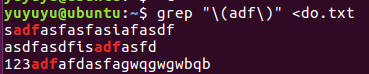
“adfasfas” 中后面的6个字母是重复的, fas fas

引用第二个空间 用2

这样就得到一个正则表达式, 要匹配 adfasfasf 字符串了
8使用 ^ $描点,匹配起止位置
9 BRE优先级 高到低
[..] [==] [::] 字符排序的方括号
metacharacter 转义的mea字符
[] 方括号表达式
( ) digit 子表达式和后向引用
* { } 前置当个字符重现的正则表达式
无符号
^ $ 描点
^$ 只能用来表示字符串的开头结尾, 无法匹配内嵌的换行字符。
| 交替
10 匹配单个字符的特殊写法
grep "[-]" <do.txt

grep, awk 只支持 BRE, 不支持 ERE 怪不得\ + ? 都没法用
11 搜索两个字符串使用-e参数
logcat |grep -e "(onEvent: 0x520)" -e"(enableAFCount)"
