分词器作用
在创建索引的时候需要用法哦分词器,在使用字符串搜索的时候也会用到分词器,并且这两个地方要使用同一个分词器,否则可能会搜索不出来结果;
分词器的作用是把一段文本中的词按规则取出所包含的所有词,对应的是Analyzer类,这是一个抽象类,切分词的具体规则是由子类实现的,所有对于不同语言的规则,要有不同的分词器;
分词器原理
分词器为中文分词器和英文分词器:
英文分词器是按照词汇切分,同时作词干提取,也就是将单词末尾的变化还原,使其能搜索出来,另外各种分词器对英文都支持的比较好;
中文分词器很多实现方式,实现原理基本差不多,都是Analyzer的子类:
标椎分词器:也叫单字分词,将中文一个字一个字的分词; new StandardAnalyzer();
简单分词器:根据标点符号进行分词; new SimpleAnalyzer();
二分法分词器:按照两个字进行分词; new CJKAnalyzer();
停用词分词器:和简单分词器很像,根据被忽略停用的词进行分词; new StopAnalyzer();
空格分词器:根据空格进行分词; new WhitespaceAnalyzer();
IK中文分词器:分为两种实现,一种采用智能切分,另一种是最细粒度切分算法; new IKAnalyzer();
案例
Lucene默认的分词器效果(标椎分词器)

package com.wn.Analyzer;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.tokenattributes.OffsetAttribute;
import java.io.IOException;
/*标椎分词器*/
public class testTokenStream {
public static void main(String[] args)throws IOException {
//创建一个标椎分析器对象
Analyzer analyzer=new StandardAnalyzer();
//获得tokenStream对象
//参数一:域名 参数二:要分析的文本内容
TokenStream tokenStream=analyzer.tokenStream("test","The Spring Framework procides a comprehensive programming and configuration model.");
//添加一个引用,可以获得每个关键词
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class);
//将指针调整到列表的头部
tokenStream.reset();
//遍历关键词列表,通过incrementToken方法判断列表是否结束
while(tokenStream.incrementToken()){
//取关键词
System.out.println(charTermAttribute);
}
//关闭资源
tokenStream.close();
}
}
效果实现
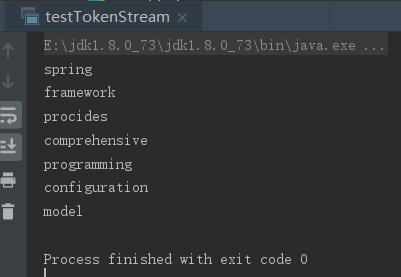
中文分析器
Lucene自带中文分词器
package com.wn.Analyzer;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import java.io.IOException;
public class CAnalyzer {
public static void main(String[] args)throws IOException {
//创建一个标椎分析器对象
Analyzer analyzer=new StandardAnalyzer();
//获得tokenStream对象
//参数一:域名 参数二:要分析的文本内容
TokenStream tokenStream=analyzer.tokenStream("test","哈哈哈,我爱中国,祖国~!!");
//添加一个引用,可以获得每个关键词
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class);
//将指针调整到列表的头部
tokenStream.reset();
//遍历关键词列表,通过incrementToken方法判断列表是否结束
while(tokenStream.incrementToken()){
//取关键词
System.out.println(charTermAttribute);
}
//关闭资源
tokenStream.close();
}
}
效果实现:
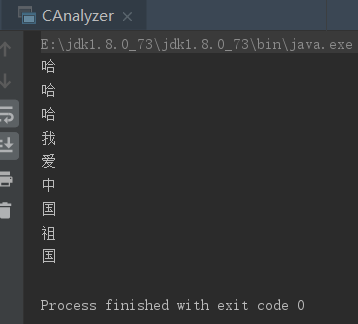
IK中文分词器(IKAnalyzer)
1.导入依赖
<!-- https://mvnrepository.com/artifact/com.jianggujin/IKAnalyzer-lucene -->
<dependency>
<groupId>com.jianggujin</groupId>
<artifactId>IKAnalyzer-lucene</artifactId>
<version>8.0.0</version>
</dependency>
2.配置IKAnalyzer,导入配置文件
hotword.dic 扩展词典,可以将时尚的网络名词放入到该词典当中,这样就能根据扩展词典进行分词
stopword.dic 停用词词典,可以将无意义的词和敏感词汇放入到该词典当中,这样在分析的时候就会忽略这些内容
IKAnalyzer.cfg.xml文件:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">hotword.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<!--词典可以有多个,需要使用分号进行分割“;”-->
<entry key="ext_stopwords">stopword.dic;</entry>
</properties>
3.使用IKAnalyzer进行分词
/*自定义分词器*/
public class IKAnalyzerTest {
public static void main(String[] args)throws IOException {
//创建一个自定义分词器
Analyzer analyzer=new IKAnalyzer();
//获得tokenStream对象
//参数一:域名 参数二:要分析的文本内容
TokenStream tokenStream=analyzer.tokenStream("","数据库安装,本地计算机!");
//添加一个引用,可以获得每个关键词
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class);
//将指针调整到列表的头部
tokenStream.reset();
//遍历关键词列表,通过incrementToken方法判断列表是否结束
while(tokenStream.incrementToken()){
//取关键词
System.out.println(charTermAttribute);
}
//关闭资源
tokenStream.close();
}
}
效果实现
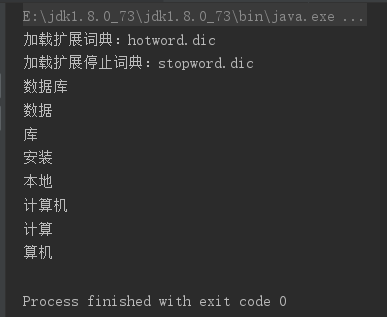
4.程序当中使用IKAnalyzer
package com.wn.Analyzer;
import org.apache.commons.io.FileUtils;
import org.apache.lucene.document.*;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.wltea.analyzer.lucene.IKAnalyzer;
import sun.reflect.misc.FieldUtil;
import java.io.File;
import java.io.IOException;
/*自定义分词器-创建索引*/
public class addDocument {
public static void main(String[] args)throws IOException {
//步骤一:创建Directory对象,用于指定索引库的位置 RAMDirectory内存
Directory directory = FSDirectory.open(new File("E:\Lucene\temp\index").toPath());
//步骤二:创建一个IndexWriter对象,用于写索引
IndexWriter indexWriter=new IndexWriter(directory,new IndexWriterConfig(new IKAnalyzer()));
//步骤三:读取磁盘中文件,对应每一个文件创建一个文档对象
File file=new File("E:\Lucene\temp\searchsource");
//步骤四:获取文件列表
File[] files = file.listFiles();
for (File item:files) {
//步骤五:获取文件数据,封装域 参数三:是否存储
Field fieldName=new TextField("fieldName",item.getName(), Field.Store.YES);
Field fieldPath=new StoredField("fieldPath",item.getPath());
Field fieldSize=new LongPoint("fieldSize", FileUtils.sizeOf(item));
Field fieldSizeStore=new StoredField("fieldSize", FileUtils.sizeOf(item));
Field fieldContent=new TextField("fieldContent", FileUtils.readFileToString(item,"UTF-8"), Field.Store.YES);
//步骤六:创建文档对象,向文档对象中添加域
Document document=new Document();
document.add(fieldName);
document.add(fieldPath);
document.add(fieldSize);
document.add(fieldContent);
document.add(fieldSizeStore);
//步骤七:创建索引,将文档对象写入到索引库
indexWriter.addDocument(document);
}
//步骤八:关闭资源
indexWriter.close();
}
}