sqlserver中文件和文件组的概念
参考文献:博客:http://www.cnblogs.com/CareySon/archive/2011/12/26/2301597.html
sql server 中,数据库在硬盘上的存储方式和普通文件在windows中的存储方式没有什么不同,仅仅是几个文件而已,sql server通过管理
逻辑上的文件组的方式来管理文件。
在sql server中,通过文件组这个逻辑对象来存放数据文件进行管理。
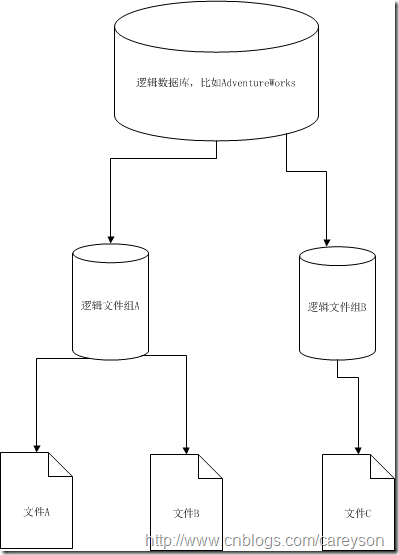
我们看到逻辑数据库由一个或多个文件组构成。文件组管理着磁盘上的文件,文件中存放着实际数据。对于用户角度来说
需要对创建的对象指定存储的文件组只有三种数据:表,索引,大对象使用文件组可以隔离用户和文件,使得用户针对文件组来建立表和索引,而不是实际磁中的文件,
当文件移动或修改时,由于用户建立的表和索引是建立在文件组上的,并不依赖于具体文件,这大大加强了可管理性(类似于:sqlserver 中架构的概念)
使用文件组来管理文件可以使得同一文件组内的不同文件分布在不同的硬盘中,提高了IO性能,
sqlserver会根据每个文件设置的初始大小和增长量自动分配新加入的空间,假设在同一文件组中的文件A设置的大小为文件B的两倍,
新增一个数据占用三页(Page),则按比例将2页分配到文件A中,1页分配到文件B中.
换一种说法,帮助你理解
1、文件和文件组的含义与关系
每个数据库有一个主数据文件.和若干个从文件。文件是数据库的物理体现。 文件组可以包括分布在多个逻辑分区的文件,实现负载平衡。文件组允许对文件进行分组,以便于管理和数据的分配/放置。例如,可以分别在三个硬盘驱动器上创建三个文件(Data1.ndf、Data2.ndf 和 Data3.ndf),并将这三个文件指派到文件组 fgroup1 中。然后,可以明确地在文件组 fgroup1 上创建一个表。对表中数据的查询将分散到三个磁盘上,因而性能得以提高。在 RAID(磁盘冗余阵列)条带集上创建单个文件也可以获得相同的性能改善。然而,文件和文件组使您得以在新磁盘上轻易地添加新文件。另外,如果数据库超过单个 Microsoft Windows 文件的最大大小,则可以使用次要数据文件允许数据库继续增长。
2、文件、文件组在实践应用中常见的问题
通常情况下我们构造的数据库都只有两个文件,mdf文件和ldf文件.但是这样有两个缺点:
(一)容易导致文件过大
我们知道,mdf文件是数据库文件,这样的话也就意味着随着数据库的增大mdf就会相应的增大,显然在现在的应用中数据膨胀是太常见的事情了,当你的应用变大后,mdf文件也会变大,然而windows对文件的大小是有要求的,这样的话很容易导致mdf文件达到windows所允许的文件大小的界限(于是数据库就崩溃了)。
(二)没有利用到磁盘阵列
大型的服务器好多都有磁盘阵列,你可以把磁盘阵列简单的假象成n个一块转动的磁盘,磁盘阵列的设计是希望通过多个磁盘的串联来得到更大的读写效率.但是如果你的数据库只有一个mdf文件(ldf文件暂时不考虑),那么你总是只能够利用这个磁盘阵列里面的一个磁盘而已.那样的话昂贵的磁盘阵列的效率就由并联变成串联了.试想如果我们能够让mdf分散成多个文件,比如说磁盘阵列上的每个磁盘中都分配一个文件,然后把mdf中的数据分散到各个文件中,我在读取的时候就是串联的读取了,这样就充分的利用了磁盘阵的存取效能.
这两个问题平常我们没有遇到过(条件不具备),但是做大型的服务开发的时候这几乎是致命的.
3.文件分类:
首要文件:这个文件是必须有的,而且只能有一个。这个文件额外存放了其他文件的位置等信息.扩展名为.mdf
次要文件:可以建任意多个,用于不同目的存放.扩展名为.ndf
日志文件:存放日志,扩展名为.ldf
| 文件 | 说明 |
|---|---|
|
主要 |
主要数据文件包含数据库的启动信息,并指向数据库中的其他文件。用户数据和对象可存储在此文件中,也可以存储在次要数据文件中。每个数据库有一个主要数据文件。主要数据文件的建议文件扩展名是 .mdf。 |
|
次要 |
次要数据文件是可选的,由用户定义并存储用户数据。通过将每个文件放在不同的磁盘驱动器上,次要文件可用于将数据分散到多个磁盘上。另外,如果数据库超过了单个 Windows 文件的最大大小,可以使用次要数据文件,这样数据库就能继续增长。 次要数据文件的建议文件扩展名是 .ndf。 |
|
事务日志 |
事务日志文件保存用于恢复数据库的日志信息。每个数据库必须至少有一个日志文件。事务日志的建议文件扩展名是 .ldf。 |
4.默认文件组
如果在数据库中创建对象时没有指定对象所属的文件组,对象将被分配给默认文件组。不管何时,只能将一个文件组指定为默认文件组。默认文件组中的文件必须足够大,能够容纳未分配给其他文件组的所有新对象。
PRIMARY 文件组是默认文件组,除非使用 ALTER DATABASE 语句进行了更改。但系统对象和表仍然分配给 PRIMARY 文件组,而不是新的默认文件组。
我们可以通过下面的语句来查看数据库中的文件情况。
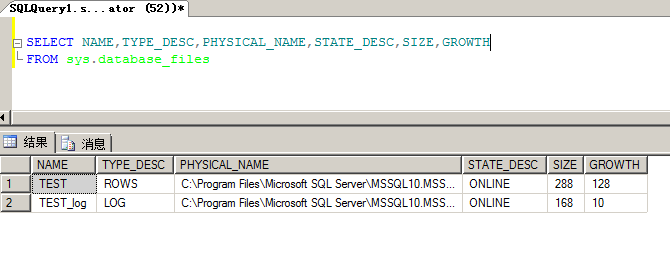
还有一点要注意的是,如果一个表是存在物理上的多个文件中时,则表的数据页的组织为N(N为具体的几个文件)个B树.而不是一个对象为一个B树.
对一个数据库来说,既可以在创建时增加文件和文件组 也可以向现有的数据添加文件和文件组(默认就属于primary文件组)
那么数据库中建立多少文件组才合理呢?
看这里:http://www.sqlskills.com/blogs/paul/files-and-filegroups-survey-results/
5.具体操作
我们使用sql 语句来操作文件组(好像高手,一般都用SQL语句滴哦~~~)
CREATE DATABASE TEST ON PRIMARY --指定主要文件 ( NAME=TEST, FILENAME='F:dbTEST.MDF', SIZE=50MB, MAXSIZE=100MB, --也可以指定为UNLIMITED FILEGROWTH=5% --中定义的文件的增长增量。文件的 FILEGROWTH 设置不能超过 MAXSIZE 设置 ), ( NAME=TESTLDF01, FILENAME='F:dbTESTLDF01.NDF', SIZE=100MB, MAXSIZE=200MB, FILEGROWTH=5% ), ( NAME=TESTLDF02, FILENAME='F:dbTESTLDF02.NDF', SIZE=100MB, MAXSIZE=200MB, FILEGROWTH=5% ) LOG ON ( NAME=TESTLOG, FILENAME='F:dbTEST.LDF', SIZE=10, MAXSIZE=50, FILEGROWTH=5% ) --Test 自动归于默认文件组 GO /* 一些参数解析: --FILEGROWTH-- 每次需要新的空间时为文件添加的空间大小。指定一个整数,不要包含小数位。 0 值表示不增长。该值可以 MB、KB、GB、TB 或百分比 (%) 为单位指定。 如果未在数量后面指定 MB、KB 或 %,则默认值为 MB。如果指定 %, 则增量大小为发生增长时文件大小的指定百分比。如果没有指定 FILEGROWTH, 则默认值为 10%,最小值为 64 KB。指定的大小舍入为最接近的 64 KB 的倍数。 FILEGROWTH 的设置要合理: 默认SQL Server 在数据库文件满了后,是自动增加原数据库文件的10%大小,用来继续使用。 如果使用按照百分比增加,而此时数据库又在繁忙的使用当中。一旦你的数据库文件大了后, 上述超时就可能出现。这时候不要简单地以为服务器压力太大了。也许就是你的一个设置导致了超时。 是数据库文件在增加的时候超时了。而不是平常常以为的具体的SQL语句超时。 某一条数据更新语句在数据库或日志文件即将满的时候执行,数据库增长的IO操作会导致延时, 此延时会阻塞其他数据库操作,连锁反应,形成blocking,这个时候数据库会成假死现象。 过几分钟,当这条语句执行完后,数据文件就会增长完成,所有的blocking也就解开了。 SIZE、MAXSIZE 和 FILEGROWTH 参数中不能指定分数。若要在 SIZE 参数中指定以兆字节为单位的分数, 请将该数字乘以 1,024 转换成千字节 */ --添加文件组 ALTER DATABASE TEST ADD FILEGROUP[GROUP_NAME] --添加文件并指定到某个文件组中; ALTER DATABASE TEST ADD FILE( NAME=N'TEST01', FILENAME='F:TESTTEST01.DNF', SIZE=50MB, MAXSIZE=100MB, FILEGROWTH=5MB ) TO FILEGROUP[GROUP_NAME] --修改文件 ALTER DATABASE TEST MODIFY FILE ( NAME=TEST01, SIZE=60MB )
--删除文件组(一切关于删除的操作,都小心点好....)
ALTER DATABASE TEST
REMOVE FILEGROUP[NAME]
--一旦删除文件组,那么文件组中的所有表就拜拜了
一旦文件加入到文件组,不能切换文件组了。 (网上,查阅之后,好像是可以切换的滴..待定)
下面演示将表添加到指定的文件组中的滴样子;
--创建数据库 --添加加文件组(A) --三个NDF(DATA1.NDF DATA2.NDF DATA3.NDF)添加到A中 --将三个NDF 放在不同磁盘中 --然后,我们再针对文件组(A) 创建一个表(table_A) --那么 我们对表(table_A)的查询分配到三个磁盘中,实现了,均衡负载 --SELECT * FROM sys.filegroups 查看当前数据库中的 文件组 CREATE TABLE table_A( ID INT NOT NULL PRIMARY KEY IDENTITY(1,1), CITYNAME VARCHAR(100)
) ON GROUP_NAME
至于 界面操作,我就不将啦~~(我要去吃饭了...)
总结-优缺点:
通常情况下,小型的数据库并不需要创建多个文件来分布数据。但是随着数据的增长,使用单个文件的弊端就开始显现。
首先:使用多个文件分布数据到多个硬盘中可以极大的提高IO性能.
其次:多个文件对于数据略多的数据库来说,备份和恢复都会轻松很多.
但是,在数据库的世界中,每一项好处往往伴随着一个坏处:
显而易见,使用多文件需要占用更多的磁盘空间。这是因为每个文件中都有自己的一套B树组织方式,和自己的增长空间。当然了,还有一套自己的碎片,但是在大多数情况下,
多占点磁盘空间带来的弊端要远远小于多文件带来的好处.
还有针对文件组的备份:
看大牛博客:
http://www.cnblogs.com/gaizai/p/3582024.html