Mysql架构讲解
一、从一条查询语句的执行顺序来看mysql架构的组件

二、逐个分析一下每一个组件
1、查询缓存
Mysql的缓存机制比较苛刻,每一次查询的语句必须一摸一样才可以调取到缓存的数据,多一个空格也是不可以的。而且,表里面的任何一条数据发生变化,缓存都会失效,对于频繁更新的表来说不合适。推荐使用ORM框架进行缓存,或者是直接使用独立的缓存服务,比如:redis
Mysql8.0中已经将mysql的缓存机制移除,所以可以看出它的可用性。
2、解析器
分为词法解析和语法解析
(1)、词法解析:
就是把一个简单的sql打碎成一个个单词,判断每个符号是什么类型,从哪里开始那里结束。
(2)、语法解析
对sql进行一些语法的检查,比如单引号有没有闭合,根据语法规则,根据sql语句生成一个数据结构,我们把它叫做解析树。
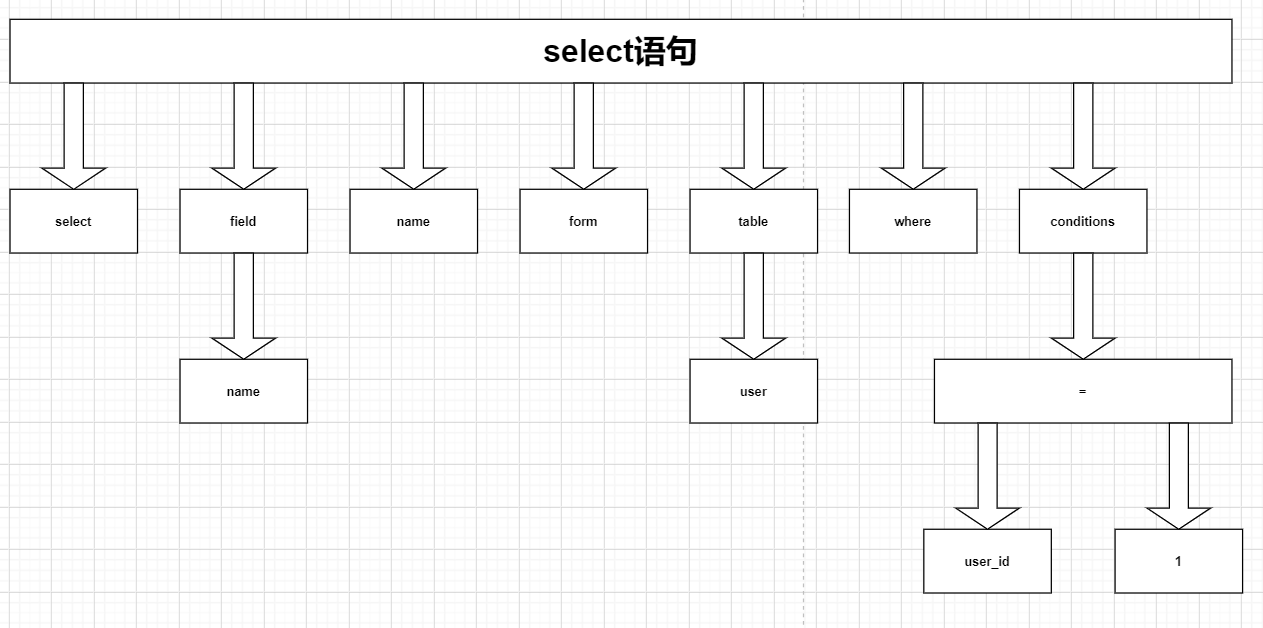
比如语句 select name from user where user_id = 1;
它的解析树如下:
3、预处理器
主要用于语义解析:
如果写了一个语法完全正确的树,但是表或者字段不存在,还是在解析的时候报错,因为解析器处理之后,还有一个预处理器,它用来判断解析树的语义是否正确,也就是表名和字段名是否存在。预处理后生成一个新的解析树。
4、查询优化和查询执行计划
查询优化器根据解析树生成不同的执行计划,然后选择出来最优的一种执行计划。
比如多表联合查询选择拿一张表作为基准,有多个索引时选择使用哪个索引,移除1=1的恒等式等等。优化器最终会把解析树变成一个执行计划,执行计划也是一个数据结构。最后选择的执行计划不一定是最优的执行计划。我们们在语句执行加上explain就可以查询到执行计划的信息。如果想要详细的信息,就用format=json。
比如语句为:explain format=json select name from user where user_id = 1
5、存储引擎
表在存储数据的过程中,还需要组织数据的存储结构,由我们的存储引擎决定,我们把存储引擎叫做表类型,存储引擎可以更换。
每张表都可以设置自己的存储引擎
show table status from '表名'
三、常用存储引擎的简要介绍
1、MyLSAM
应用范围比较小。表级锁定限制了读/写的性能,因此在Web和数据仓库配置中,它通常用于只读或以读为主的工作。
特点:
(1)、支持表级别的锁(插入和更新会锁表)。不支持事务。
(2)、拥有较高的插入(insert)和查询(select)速度。
(3)、存储了表的行数(count速度更快)。
2、InnoDB
mysql 5.7中的默认存储引擎。InnoDB是一个事务安全(与ACID兼容)的MySQL
存储引擎,它具有提交、回滚和崩溃恢复功能来保护用户数据。InnoDB行级锁(不升级
为更粗粒度的锁)和Oracle风格的一致非锁读提高了多用户并发性和性能。InnoDB将
用户数据存储在聚集索引中,以减少基于主键的常见查询的I/O。为了保持数据完整性,
lnnoDB还支持外键引用完整性约束。
特点:
(1)、支持事务,支持外键,因此数据的完整性、一致性更高。
(2)、支持行级别的锁和表级别的锁。
(3)、支持读写并发,写不阻塞读(MVCC).
(4)、特殊的索引存放方式,可以减少IO,提升查询效率。
3、Memory
将所有数据存储在RAM中,以便在需要快速查找非关键数据的环境中快速访问。这
个引擎以前被称为堆引擎。其使用案例正在减少;InnoDB及其缓冲池内存区域提供了一
种通用、持久的方法来将大部分或所有数据保存在内存中,而ndbcluster为大型分布式
数据集提供了快速的键值查找。
特点:
(1)、把数据放在内存里面,读写的速度很快,但是数据库重启或者崩溃,数据会全部消
失。只适合做临时表。
(2)、默认使用哈希索引。
4、CSV
它的表买际上是带有逗号分隔值的又本文件。CSV表允许以CSV格式导入或转储数据,
以便与读写相同格式的脚本和应用程序交换数据。因为CSV表没有索引,所以通常在正
常操作期间将数据保存在innodb表中,并且只在导入或导出阶段使用CSV表。
特点:
(1)、不允许空行,不支持索引。
(2)、格式通用,可以直接编辑,适合在不同数据库之间导入导出。
5、Archive
这些紧凑的未索引的表用于存储和检索大量很少引用的历史、存档或安全审计信息。
特点:
(1)、不支持索引,不支持update delete。
四、mysql的体系结构更详细的总结
1、模块详解
(1)、Connector:用来支持各种语言和SQL的交互,比如 PHP,Python,Java的JDBC。
(2)、Management Serveices & Utilities:系统管理和控制工具,包括备份恢复,MySQL复制、集群等。
(3)、Connection Pool:连接池,管理需要缓冲的资源,包括用户密码权限线程等。
(4)、SQL Interface:用来接收用户的SQL命令,返回用户需要的查询结果。
(5)、Parser:用来解析SQL语句。
(6)、Optimizer:查询优化器。
(7)、Cache and Buffer:查询缓存,除了行记录的缓存之外,还有表缓存,Key缓
存,权限缓存等等;
(8)、Pluggable Storage Engines:插件式存储引擎,它提供API给服务层使用,
跟具体的文件打交道。
五、架构分层
1、服务层:查询缓存、解析器、预处理器、查询优化器、执行器。
2、存储引擎层:InnoDB,Memory等存储引擎。
六、InnoDB的内存结构
内存结构主要为:
Buffer Pool、Change Buffer、Log Bufffer、AHI。
1、Buffer Pool
Buffer Pool缓存的是page的页面信息。存储引擎先把磁盘中的数据通过io操作来写入Buffer Pool,每次一个页的数据,16k,当下次读取到相同的页的时候,直接去BufferPool获取,而不是直接操作磁盘,提升效率,更新操作也是,就是先把数据写道BufferPool,有专门的线程,每隔一段时间就进行一次入库操作。这个过程叫做刷脏,BufferPool数据页和磁盘数据不同的时候,这个页我们就叫做脏页。
SHOW STATUS LIKE ‘%innodb_buffer_pool%’;
默认大小为128MB
2、Log Buffer(redo log)
如果刷脏不及时,这个时候服务器或者数据库宕机,就会导致数据的丢失,怎么解决这个问题呢?所以InnoDB就把缓存中的修改的操作都放到了redo log中,数据库再次启动的时候、就会从这个日志进行恢复操作,来避免这个问题的出现。
show variablcs like 'innodb_log%:
两个文件,每个默认为48MB
为啥先记录日志在刷盘呢?
如果我们所需要的数据是随机分散在磁盘上不同页的不同扇区中,那么找到相应的数据需要等到磁臂旋转到指定的页,然后盘片寻找到对应的扇区,才能找到我们所需要的一块数据,一次进行此过程直到找完所有数据,这个就是随机IO,读取数据速度较慢。假设我们已经找到了第一块数据,并且其他所需的数据就在这一块数据后边,那么就不需要重新寻址可以依次拿到我们所需的数据,这个就叫顺序IO.刷盘是随机I/O,而记录日志是顺序I/O(连续写的),顺序I/O效率更高。因此先把修改写入日志文件,在保证了内存数据的安全性的情况下,可以延迟刷盘时机,进而提升系统吞吐。
redo log有什么特点?
(1)、redo log是InnoDB存储引擎实现的,并不是所有存储引擎都有。支持崩溃恢复
是InnoDB的一个特性。
(2)、redo log是物理日志,记录的是“在某个数据页上做了什么修改”,记录物理页面修改的信息。
(3)、redo log 的大小是固定的,前面的内容会被覆盖,一旦写满,就会触发buffer pool,到磁盘的同步,以便腾出空间记录后面的修改。redo log的内容主要是用于崩溃恢复。磁盘的数据文件,数据来自buffer pool,只有redo log写满了,不能再记录更多内存的数据了,把buffer pool刷盘,然后覆盖redo log。
除了redo log之外,还有一个跟修改有关的日志,叫做undo log。redo log和undolog与事务密切相关,统称为事务日志。
3、Change buffer
它是一种应用在非唯一普通索引页(non-unique secondary index page)不在缓冲池中,对页进行了写操作,并不会立刻将磁盘页加载到缓冲池,而仅仅记录缓冲变更(buffer changes),等未来数据被读取时,再将数据合并(merge)恢复到缓冲池中的技术。写缓冲的目的是降低写操作的磁盘IO,提升数据库性能。
4、Undo log
undo log(撤销日志或回滚日志)记录了事务发生之前的数据状态(不包括select)。如果修改数据时出现异常,可以用undo log来实现回滚操作(保持原子性)。在执行undo的时候,仅仅是将数据从逻辑上恢复至事务之前的状态,逻辑日志,而不是从物理页面上操作实现的,属于逻辑格式的日志。undo log的数据默认在系统表空间ibdata1文件中,因为共享表空间不会自动收缩,也可以单独创建一个undo表空间。
show global variables like %undo%’;
七、更新流程
1、事务开始,执行器从buffer pool或者data file取到这条数据。
2、然后执行器修改数据。
3、把数据交到缓存中。
4、把修改记录记录到undo log。
5、把修改记录记录到redo log。
6、redo log 进入到prepare的状态,告诉执行器,执行完成了,可以随时提交。
7、执行器接收到通知后记录binlog。
8、调用存储引擎接口,进行事务的提交,设置redo log为commit状态。
八、Server层的日志
BinLog
(1)、binlog 以事件的形式记录了所有的DDL和DML语句,比如给Id=1这一行的count字段加1,因为它记录的是操作而不是数据值,属于逻辑日志。
(2)、binlog 可以用来做主从复制和数据恢复。跟redo log不一样,它的文件内容是可以追加的,没有固定大小限制。在开启了binlog 功能的情况下,我们可以把binlog 导出成SQL语句,把所有的操作重放一遍,来实现数据的(归档)恢复。
(3)、binlog 的另一个功能就是用来实现主从复制,它的原理就是从服务器读取主服务器的binlog,然后执行一遍。