Mysql的索引详讲
一、定义
数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库的表结构。
Mysql的数据是以文件的形式存储到磁盘上面的,每一行数据都有它的磁盘地址,没有索引的话,查找数据,就要去检索表中的每一条数据进行匹配,直到找到要查询的数据。
如果使用数据库的索引就可以了,它是专门用来检索的一种数据结构,通过索引可以很快的找到相应的数据地址,然后通过地址得到这条数据。
二、创建索引
1、三种索引类型
普通(Normal):也叫非唯一索引,是最普通的索引,没有任何的限制。
唯一(Unique):唯一索引要求键值不能重复。另外需要注意的是,主键索引是一
种特殊的唯一索引,它还多了一个限制条件,要求键值不能为空。主键索引用primay key
创建。
全文(Fulltext):针对比较大的数据,比如我们存放的是消息内容,有几KB的数
据的这种情况,如果要解决like查询效率低的问题,可以创建全文索引。只有文本类型
的字段才可以创建全文索引,比如char、varchar、text。
MyISAM和InnoDB都支持全文索引。
2、操作语句如下:
创建;
(1)、PRIMARY KEY(主键索引)
mysql>ALTER TABLE `table_name` ADD PRIMARY KEY ( column )
(2)、UNIQUE(唯一索引)
mysql>ALTER TABLE `table_name` ADD UNIQUE (column )
(3)、INDEX(普通索引)
mysql>ALTER TABLE `table_name` ADD INDEX index_name ( column )
(4)、FULLTEXT(全文索引)
mysql>ALTER TABLE `table_name` ADD FULLTEXT ( column )
(5)、多列索引
mysql>ALTER TABLE `table_name` ADD INDEX index_name ( column1, column2, column3)
或者:
create index index_name on table_name (column_list) ;
create unique index index_name on table_name (column_list) ;
删除:
drop index index_name on table_name ;
alter table table_name drop index index_name ;
alter table table_name drop primary key ;
修改索引:
alter table table_name rename index before_name to after_name;
在mysql5.7之前没有修改,只能先删除,在添加。
查询表的索引:
show index from user_innodb;
三、索引的存储结构推演
1、二叉查找树(Binary Search Tree)
所有左子树节点小于父节点,右子树节点大于父节点,如图所示。
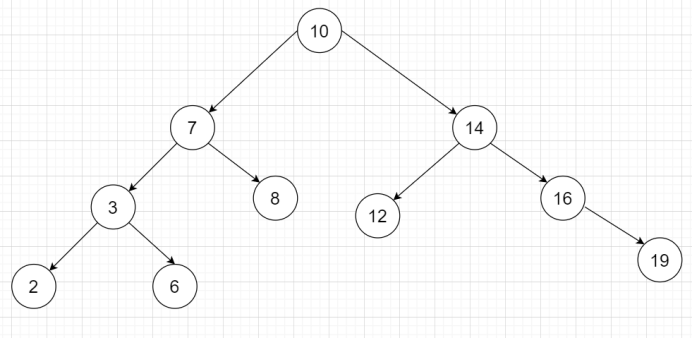
既能快速查找,又可以快速删除,但是如果插入的数据是一直增大或者一直减小的话,他就会编程链表(“斜树”),这种情况和顺序查找检索是相同的,比如为10,7,3,2,1那么他就变成了一个链表,复杂度又变成了O(n)。

什么原因导致的呢?
究其原因就是不平衡。
2、平衡二叉树(AVL Tree)(Balanced Binary Search Tree)
除了有了二叉查找树的特性外,又多了平衡的特性,左右子树深度差绝对值不能超过1。
平衡二叉树是一棵高度平衡的二叉查找树,当插入3的时候,通过右旋来保持平衡,左旋类似,nice,问题解决。

3、节点结构以及存在的问题
(1)、首先说节点结构
包含三部分:索引的键值、磁盘地址、左右子节点的引用大概的结构如下:
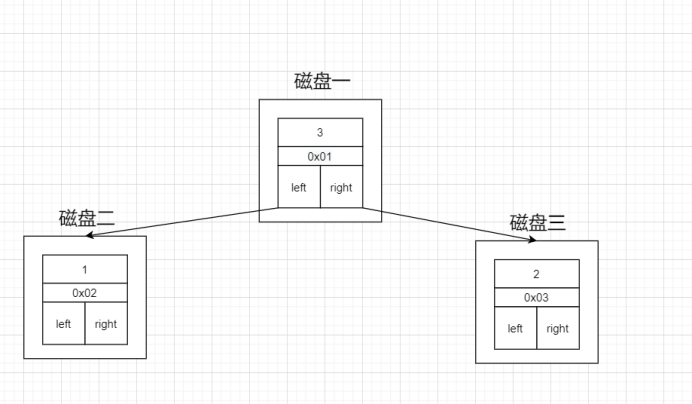
如果是这样存储数据的话,我们来看一下会有什么问题。首先,索引的数据,是放在硬盘上的。查看数据和索引的大小:当我们用树的结构来存储索引的时候,因为拿到一块数据就要在Server层比较是不是需要的数据,如果不是的话就要再读一次磁盘。访问一个节点就要跟磁盘之间发生一次IO。InnoDB操作磁盘的最小的单位是一页(或者叫一个磁盘块),大小是16K(16384字节)。那么,一个树的节点就是16K的大小。如果我们一个节点只存一键值+数据+引用,例如整形的字段,可能只用了十几个或者几十个字节,它远远达不到16k的容量,所以访问一个树节点,进行一次IO的时候,浪费了大量的空间。所以如果每个节点存储的数据太少,从索引中找到我们需要的数据,就要访问更多的节点,意味着限磁盘交互次数就会讨多。导致效率真的很低。
所以我们的解决方案是什么呢?
就是让每个节点存储更多的数据,节点上的关键字的数量越多,我们的指针数也越多,也就是意味着可以更多的分叉(我们把它叫做“路数”)。因为分叉数越多,树的深度就会减少(根节点是O)。这样就诞生了我们新的数据结构。
4、多路平衡查找树(B Tree)
这个就是我们的多路平衡查找树,叫做B Tree (B代表平衡)。跟AVL树一样,B树在枝节点和叶子节点存储键值、数据地址、节点引用。它有一个特点:分叉数(路数)永远比关键字数多1。如下图:
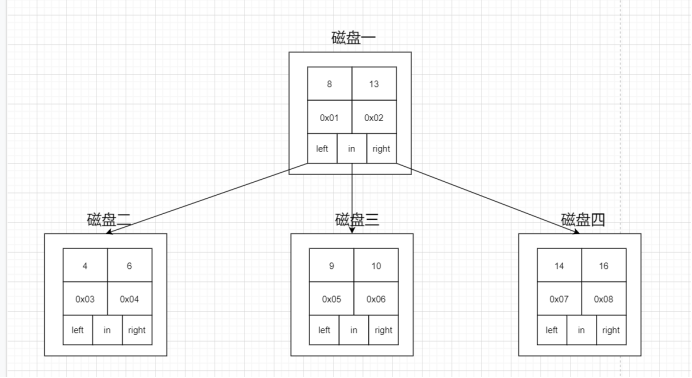
但是B Tree是怎样保持平衡的呢,显然左旋右旋肯定不行了
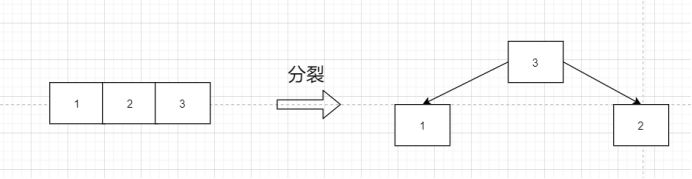
通过分列,如果在进来5,那么5和3合并即可。
5、B+ 树
如下图:

MySQL中的+Tree有几个特点:
1、它的关键在于关键字数和路数是相同的。
2、B+Tree的根节点和枝节点中都不会存储数据,只有叶子节点才存储数据,直接存储的数据。
3、B+Tree的每个叶子节点增加了一个指向相邻叶子节点的指针,它的最后一个数
据会指向下一个叶子节点的第一个数据,形成了一个有序链表的结构。
InnoDB中的B+Tree这种特点带来的优势:
1)它是B Tree的变种,BTree能解决的问题,它都能解决。B Tree解决的两大问题是什么?(每个节点存储更多关键字;路数更多)
2)扫库、扫表能力更强(对表进行全表扫描,只需要遍历叶子节点就可以了,不需要
遍历整棵B+Tree拿到所有的数据)
3)B+Tree的磁盘读写能力相对于BTree来说更强(根节点和枝节点不保存数据区,
所以一个节点可以保存更多的关键字,一次磁盘加载的关键字更多)
4)排序能力更强(因为叶子节点上有下一个数据区的指针,数据形成了链表)
5)效率更加稳定(B+Tree永远是在叶子节点拿到数据,所以IO次数是稳定的)
四、在存储引擎中的应用
1、MyISAM
在MylSAM里面,另外有两个文件:
一个是.MYD文件,D代表Data,是MylSAM的数据文件,存放数据记录。
一个是.MYI文件,l代表Index,是 MylSAM的索引文件,存放索引。
MylSAM的B+Tree里面,叶子节点存储的是数据文件对应的磁盘地址。所以从引文件.MYI中找到键值后,会到数据文件.MYD中获取相应的数据记录。在MylSAM里面,辅助索引也在这个.MYI文件里面。辅助索引跟主键索引存储和检索数据的方式是没有任何区别的,一样是在索引文件里面找到磁盘地址,然后到数据文件里面获取数据。
2、InonoDB
在InnoDB里面,它是以主键为索引来组织数据的存储的,所以索引文件和数据文件是同一个文件,都在.ibd文件里面。在InnoDB的主键索引的叶子节点上,它直接存储了我们的数据。
聚集索引(聚簇索引)︰就是索引键值的逻辑顺序跟表数据行的物理存储顺序是令致的。(比如字典的目录是按拼音排序的,内容也是按拼音排序的,按拼音排序的这种目录就叫聚集索引)。在InnoDB里面,它组织数据的方式叫做叫做(聚集)索引组织表(clustered indexorganize table),所以主键索引是聚集索引,非主键都是非聚集索引。主键之外的索引,比如在name字段上面建的普通索引,又是怎么存储和检索数据的呢?
InnoDB中,主键索引和辅助索引是有一个主次之分的。辅助索引存储的是辅助索引和主键值。如果使用辅助索引查询,会根据主键值在主键索引中查询,最终取得数据。
如果一张表没有主键索使用什么机制呢?
1、如果我们定义了主键(PRIMARY KEY),那么InnoDB会选择主键作为聚集索引。
2、如果没有显式定义主键,则 InnoDB会选择第一个不包含有NULL值的唯一索引
作为主键索引。
3、如果也没有这样的唯一索引,则InnoDB会选择内置6字节长的ROWID作为隐
藏的聚集索引,它会随着行记录的写入而主键递增。
五、使用索引的注意点
1、散列度
select (select count(distinct(id)) from user_innodb) / (select count(*) from user_innodb)
散列度越高,使用索引越合适。
2、联合索引最左匹配原则
比如user表给name和phone建立了一个联合索引。
ALTER TABLE uscr_innodb DROP INDEX comidx_namc_phonc;
ALTER TABLE user_innodb add INDEX comidx_name_phone (name.phone);
联合索引在B+Tree中是复合的数据结构,它是按照从左到右的顺序来建立搜索树的
(name在左边,phone在右边)。name相同,phone才是有序的。
所以如果name是空一定是用不到索引的。
3、覆盖索引
回表:
非主键索引,我们先通过索引找到主键索引的键值,再通过主键值查出索引里面没有的数据,它比基于主键索引的查询多扫描了一棵索引树,这个过程就叫回表。
在辅助索引里面,不管是单列索引还是联合索引,如果select的数据列只用从索引中就能够取得,不必从数据区中读取,这时候使用的索引就叫做覆盖索引,这样就避免回表。