本次作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3223
1.安装Linux,MySql
因为电脑之前安装过了VMware Workstation,我采用的是在VMware Workstation中安装Linux。
①打开VMware Workstation,在主页中选择“创建新的虚拟机”

②根据弹出的对话框,一般采用默认选项

③选择稍后安装操作系统(可以先选定安装的ISO路径)
④选择Linux(L)和版本,单击“下一步”。
⑤选择自己想取的“虚拟机名称”和安装的“位置”(方便记忆为原则)
⑥后面两步,根据需要可进行调节,一般默认即可,点击“完成”安装好了“Linux”。
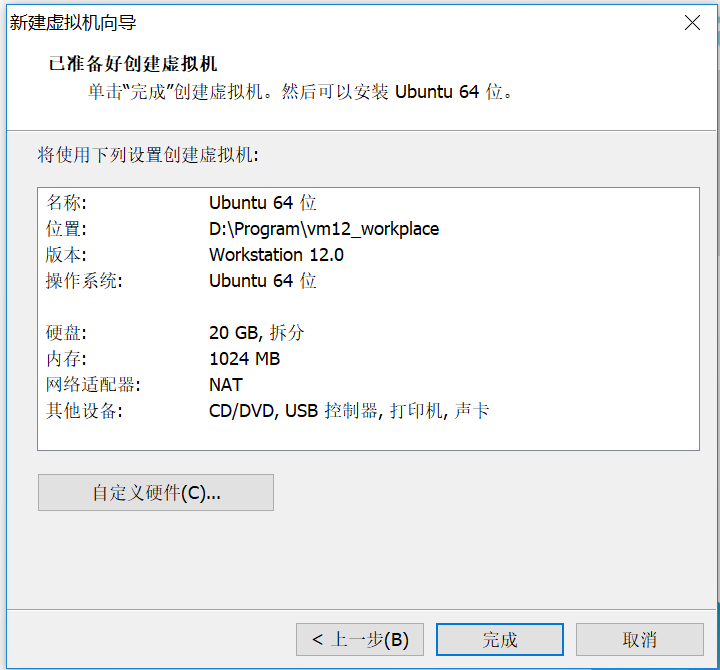
⑦开机前点击编辑虚拟机,选择“ISO镜像文件”位置安装操作系统
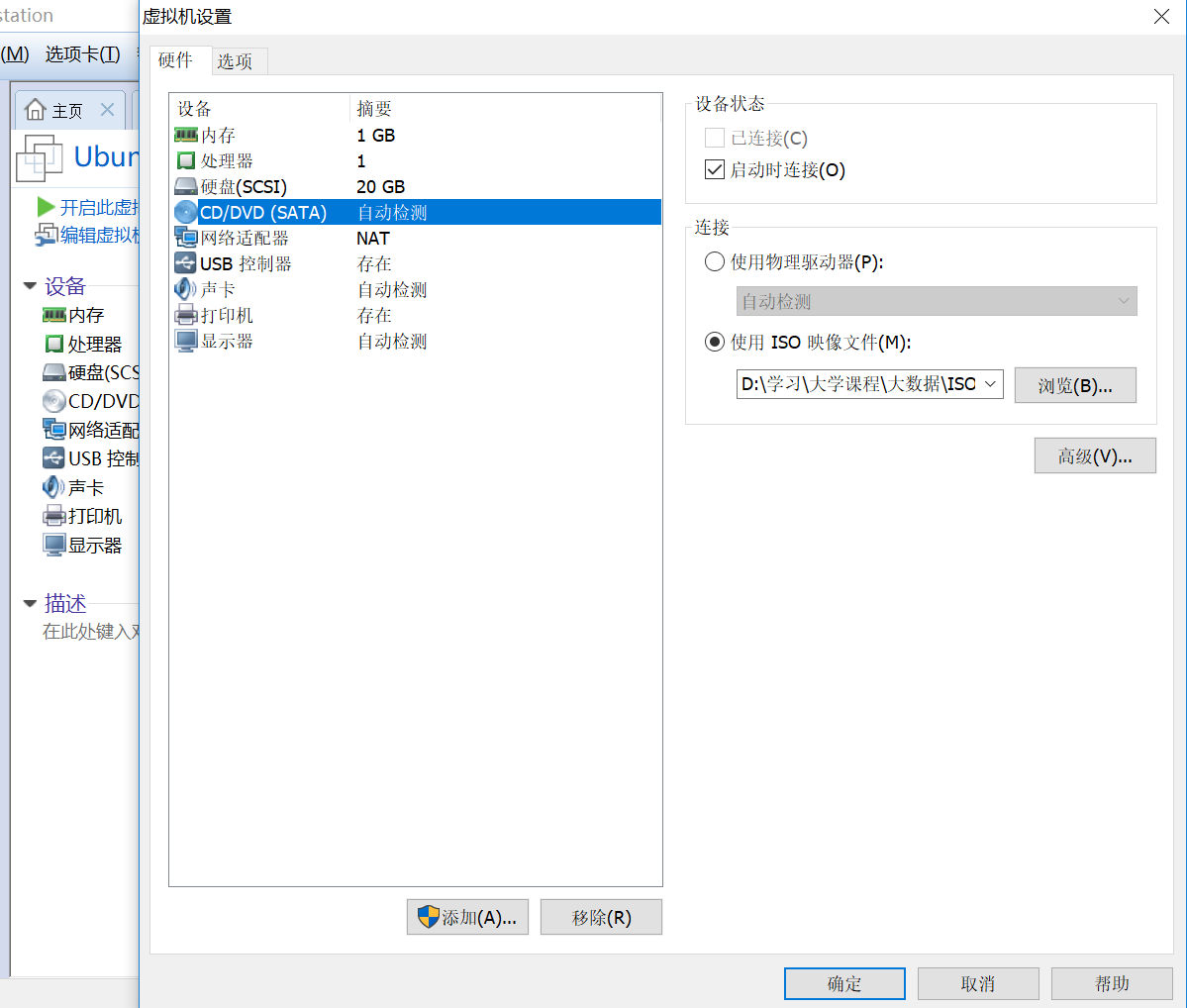
⑧开机,选择点击“安装Ubuntu Kylin”
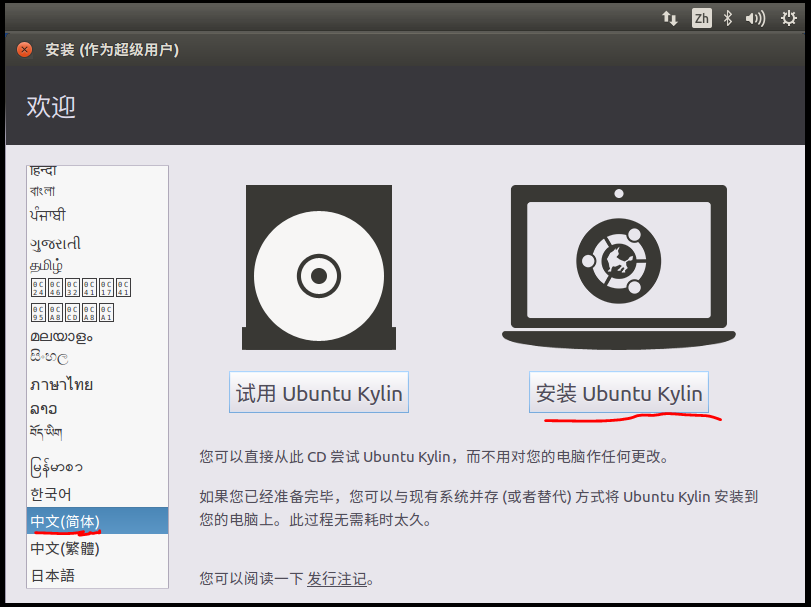
⑨以下两个选项可选可不选
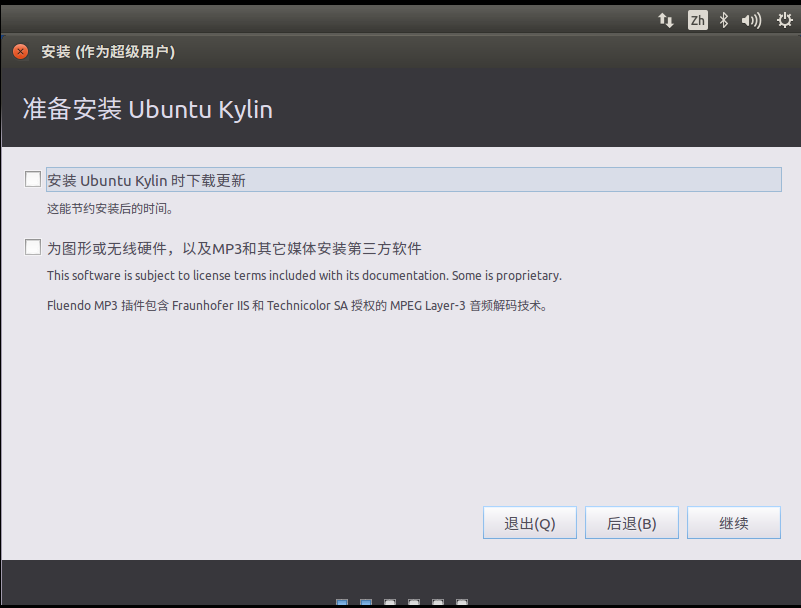
⑩点击“继续”后,进入如下界面,这里我采用默认选项,然后点击“现在安装”
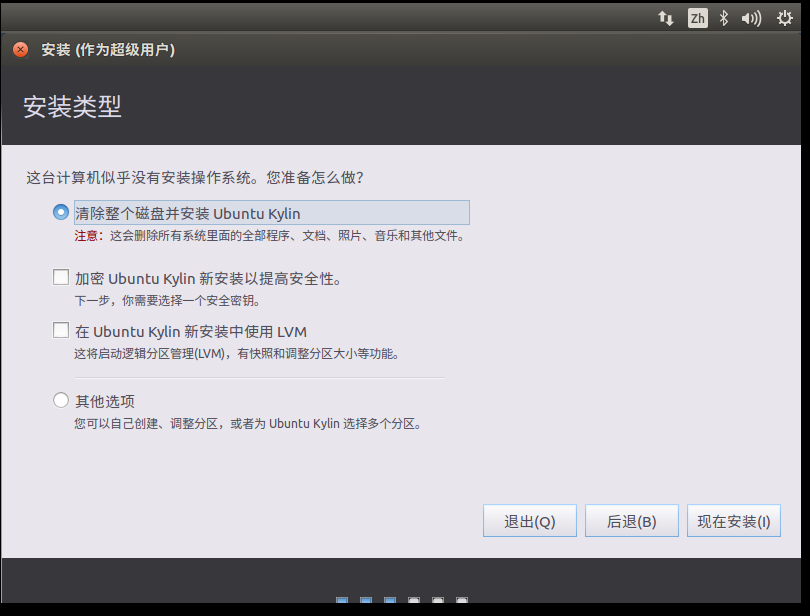
跳出弹框,确认后点击“继续”

接着是,选择时区(Shanghai),键盘布局(左右栏目都选汉语即可),设置用户名(我的用户名设为zy)和密码
等待安装,等候系统自动安装完成,最后,安装完成后重启。
安装Mysql:打开终端,依此敲入如下命令,安装过程中要设置Mysql用户的root密码,一定要记住!

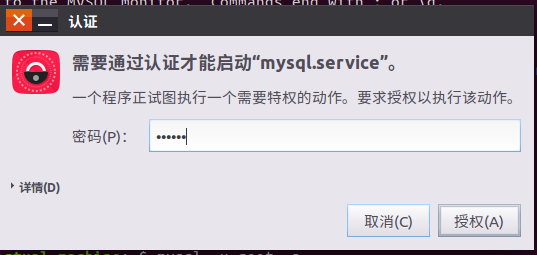
安装完成后,敲如下命令,弹出一个框开启提示框,输入当前Ubuntu用户密码,即可开启Mysql 服务器

敲入以下命令,确认是否启动成功:


至此,mysql节点处于LISTEN状态表示启动成功。
敲入如下命令,即可进入mysql shell界面:


2.windows 与 虚拟机互传文件
由于我安装的是VMware Workstation,所以window与虚拟机交互文件的方式与Virtualbox有所区别,通过搜寻资料,得出要安装Vmware-tools,按步骤操作安装成功实现window与虚拟机互传文件。
参考资料如下:
Vmware虚拟机的ubuntu系统如何与主机共享文件夹:https://blog.csdn.net/thudream2018/article/details/81321818
Ubuntu16.04 64位下安装VMware Tools过程:https://blog.csdn.net/weixin_37182342/article/details/80236632
3.安装Hadoop
windows下载文件hadoop-2.7.1解压后,重命名为hadoop把它放在共享文件夹下,接着复制hadoop到虚拟机(Ubuntu)的/usr/local路径下。
1)创建hadoop用户,并设置登陆密码,和增加管理员权限以方便部署。
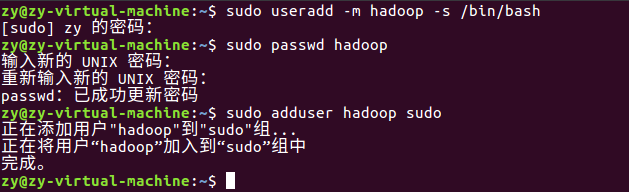
登出,选择hadoop用户登入:
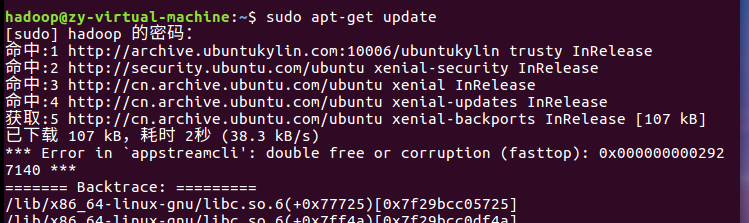
用hadoop用户登录后,先更新一下apt:
2)SSH登录权限设置:
安装SSH server(默认已经安装了SSH client)
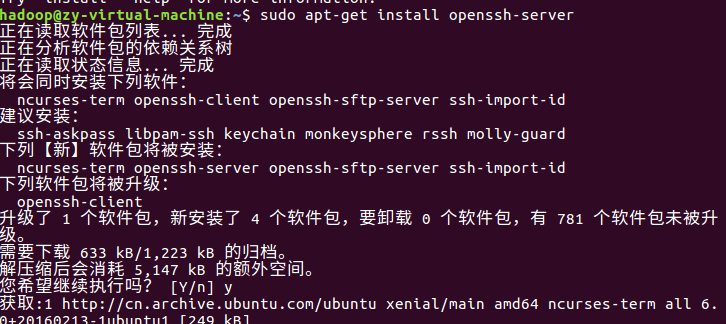
安装后,使用ssh localhost按提示操作可以登录本机,但每次都要输入hadoop密码。
所以,为了方便,需要配置SSH无密码登陆:
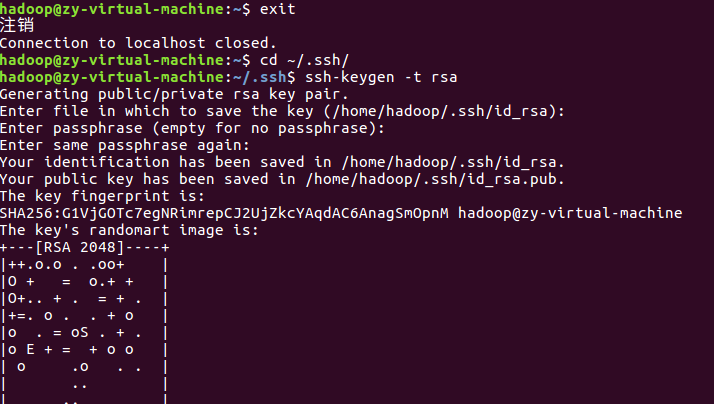

至此,再用 ssh localhost 命令,无需输入密码就可以直接登陆了。
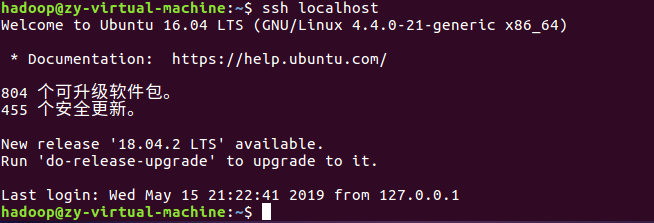
输入ps -e | grep ssh 来查看是否安装成功(如图,表示安装成功。)

3)安装Java环境
上述安装过程需要访问网络下载相关文件,需要保持联网状态。安装结束后,需要配置JAVA_HOME环境变量,在Linux终端下输入下面命令打开当前登录用户的环境变量配置文件bashrc:

在文件最前面或最后添加如下单独一行(注意,等号“=”前后不能有空格)然后保存退出

接下来,执行source ~/.bashrc让环境变量立即生效。然后检验是否设置正确
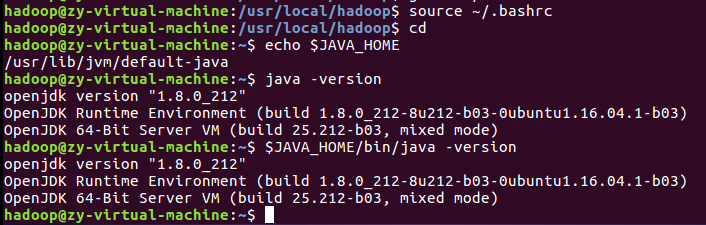
至此,就成功安装了Java环境。
4)伪分布式安装配置
进行下一步之前,再次确认

检查hadoop是否可用

伪分布式模式:Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。
①修改配置文件 core-site.xml
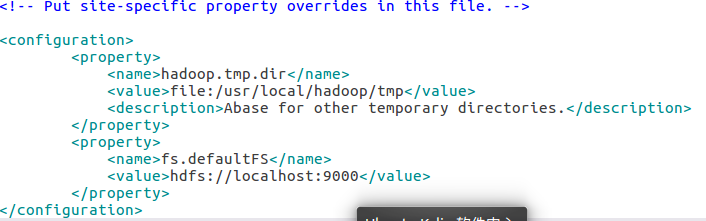
②修改配置文件hdfs-site.xml
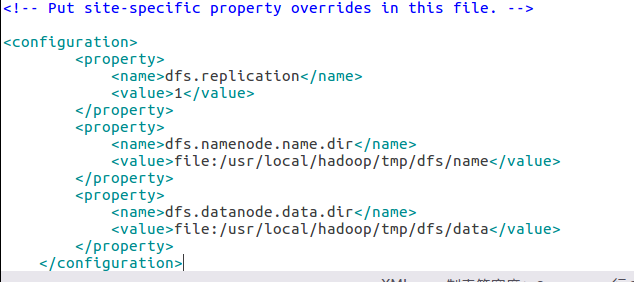
③配置完成后,执行 NameNode 的格式化 ./bin/hdfs namenode -format
出现如下错:
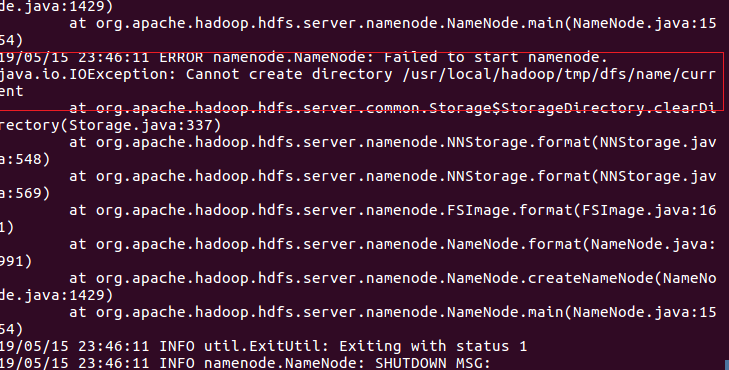
通过查找资料,得出问题,是权限不够无法再目录内新建文件。
参考资料:(Hadoop格式化namenode错误:java.io.IOException: Cannot create directory)https://blog.csdn.net/emilsinclair4391/article/details/51520524
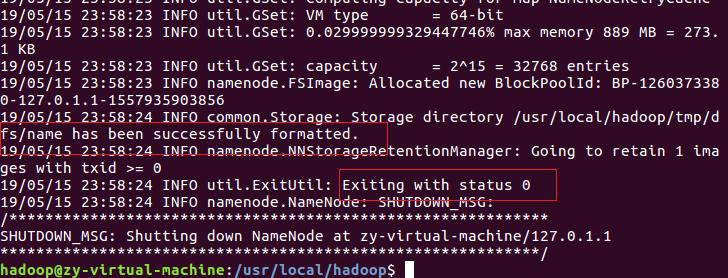
解决问题之后,重新执行 NameNode 的格式化 ./bin/hdfs namenode -format,显示成功。
④接着开启NameNode和DataNode守护进程:

⑤查看判断是否成功启动(出现如下所示,表示成功启动):

运行Hadoop伪分布式实例
①伪分布式读取的是 HDFS 上的数据,要使用 HDFS。
②首先需要在 HDFS 中创建用户目录:
③创建目录 input,其对应的绝对路径就是 /user/hadoop/input:
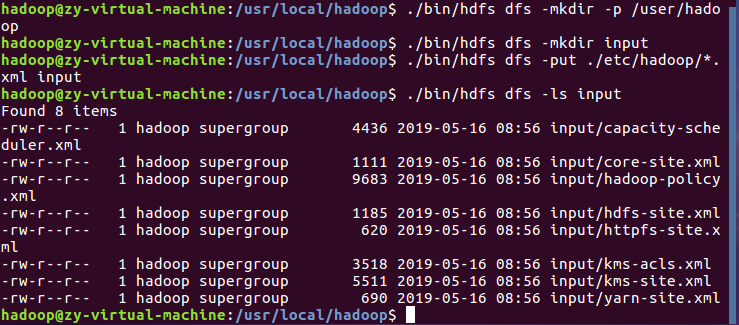
将 /usr/local/hadoop/etc/hadoop 复制到分布式文件系统中的 /user/hadoop/input 中:
④查看文件列表:
⑤伪分布式运行 MapReduce 作业:


⑥运行Hadoop伪分布式实例

⑦关闭Hadoop
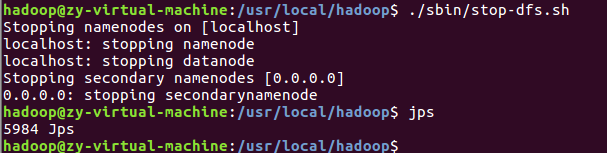
注意:下次启动 hadoop 时,无需进行 NameNode 的初始化,只需要运行 ./sbin/start-dfs.sh 开启 NameNode 和 DataNode 守护进程就可以!