1.前提:
总体思路,利用多线程(mutiSpider)爬取博客园首页推荐博客,根据用户名爬取该用户的阅读排行榜(TopViewPosts),评论排行榜(TopFeedbackPosts),推荐排行榜(TopDiggPosts),然后对得到的数据进行处理(合并目录),再进行基本排序(这里我们已阅读排行榜为例),排序阅读最多的文章,然后利用词云(wordcloud)生成图片,最后发送邮件给自己。(有兴趣的小伙伴可以部署到服务器上!)
1.1参考链接:
大神博客:https://www.cnblogs.com/lovesoo/p/7780957.html (推荐先看这个,我是在此博客基础上进行改进与扩充了的)
词云下载:https://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud (我下载的这个wordcloud-1.5.0-cp36-cp36m-win32.whl)
邮件发送:https://www.runoob.com/python/python-email.html (菜鸟教程推荐)
1.2实现效果:

2.环境配置:
python3.6.5(对应cp36,最好记住这个,因为以后下载一些whl文件都会用到)
pycharm + QQ邮箱授权码 + wordcloud-1.5.0-cp36-cp36m-win32.whl
win10,64位(虽然我是64位,但是下载词云win_amd64.whl不兼容,改成win32.whl就兼容了)
2.0 读者需要提供的东西:
1.词云所需要的图片(我是avatar.jpg)与电脑字体(具体见View_wordcloud函数
2.邮箱的SMTP授权码(密码就是授权码)
3.默认所有代码、图片等都在同一文件夹下面。
)
2.1需要导入的库(词云 + 邮件 + 爬虫)

注:1.requests,beatuifulsoup,是爬虫需要,wordcloud,jieba,是词云需要,smtplib,email是邮件需要,其余都是些基本Python语法
2.安装wordcloud词云的时候容易报错,官方链接 ,官网下载然后在本地cmd下pip install 即可。
3.编写爬虫
3.1博客园首页推荐博客
选中XHR,找到https://www.cnblogs.com/aggsite/UserStats,直接requests获取,返回的是html格式

#coding:utf-8
import requests
r=requests.get('https://www.cnblogs.com/aggsite/UserStats')
print r.text
然后可以需要对数据进行基本处理,一种是使用Beautiful Soup解析Html内容,另外一种是使用正则表达式筛选内容。
其中BeautifulSoup解析时,我们使用的是CSS选择器.select方法,查找id="blogger_list" > ul >li下的所有a标签元素,同时对结果进行处理,去除了"更多推荐博客"及""博客列表(按积分)链接。
使用正则表达式筛选也是同理:我们首先构造了符合条件的正则表达式,然后使用re.findall找出所有元素,同时对结果进行处理,去除了"更多推荐博客"及""博客列表(按积分)链接。
这样我们就完成了第一步,获取了首页推荐博客列表。


1 #coding:utf-8 2 import requests 3 import re 4 import json 5 from bs4 import BeautifulSoup 6 7 # 获取推荐博客列表 8 r = requests.get('https://www.cnblogs.com/aggsite/UserStats') 9 10 # 使用BeautifulSoup解析 11 soup = BeautifulSoup(r.text, 'lxml') 12 users = [(i.text, i['href']) for i in soup.select('#blogger_list > ul > li > a') if 'AllBloggers.aspx' not in i['href'] and 'expert' not in i['href']] 13 print json.dumps(users,ensure_ascii=False) 14 15 # 也可以使用使用正则表达式 16 user_re=re.compile('<a href="(http://www.cnblogs.com/.+)" target="_blank">(.+)</a>') 17 users=[(name,url) for url,name in re.findall(user_re,r.text) if 'AllBloggers.aspx' not in url and 'expert' not in url] 18 print json.dumps(users,ensure_ascii=False)
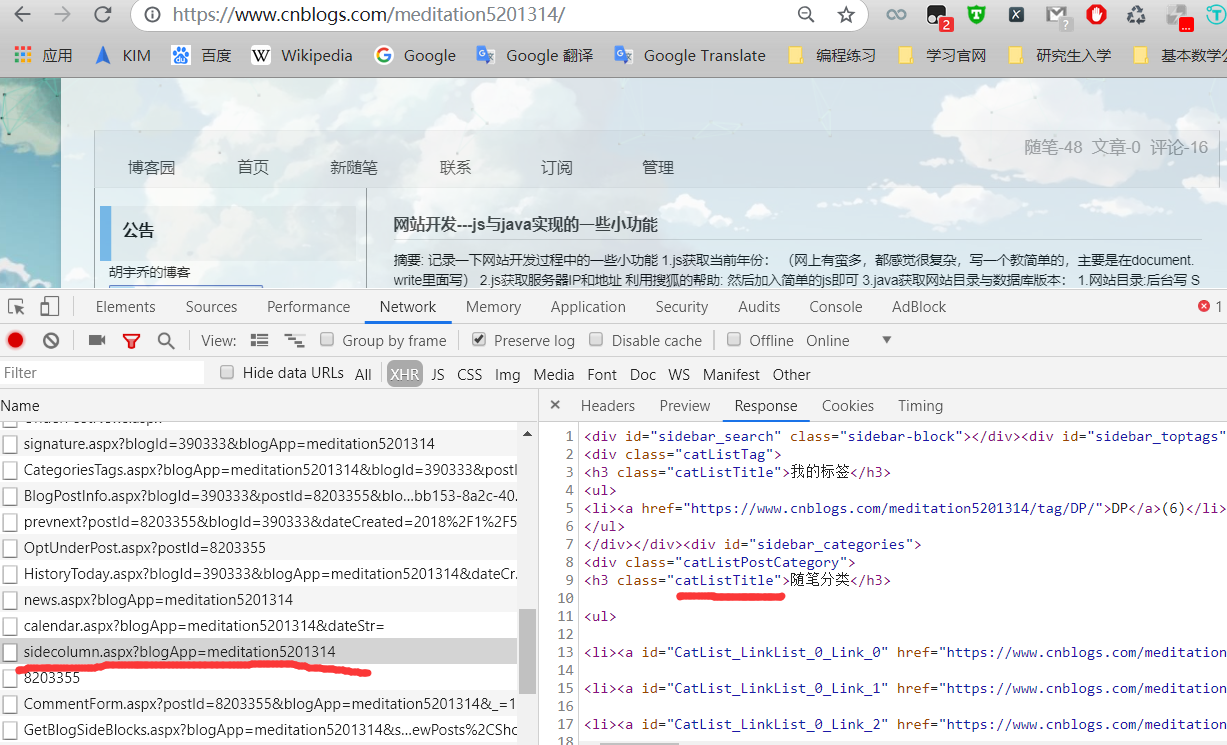
然后,这里就能获取推荐用户的博客了,我们接下来需要进入某个用户博客,找到接口sidecolumn.aspx,这个接口返回了我们需要的信息:随笔分类,点击Headers查看接口调用信息,可以看到这也是一个GET类型接口,路径含有博客用户名,且传入参数blogApp=用户名:查看Header:
https://www.cnblogs.com/meditation5201314/mvc/blog/sidecolumn.aspx?blogApp=meditation5201314,直接发送requests请求即可
#coding:utf-8
import requests
user='meditation5201314'
url = 'http://www.cnblogs.com/{0}/mvc/blog/sidecolumn.aspx'.format(user)
blogApp = user
payload = dict(blogApp=blogApp)
r = requests.get(url, params=payload)
print r.text
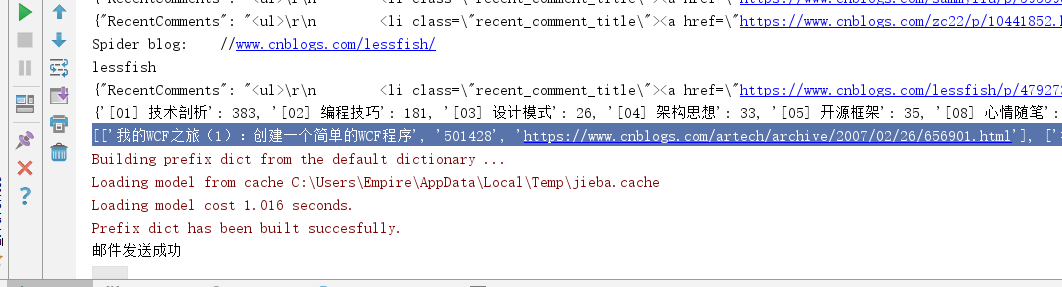
到此,便可以获得博客的分类目录及文章数量信息,其余2个我就不展示了,总共3个功能,获取用户的阅读排行榜(TopViewPosts),评论排行榜(TopFeedbackPosts),推荐排行榜(TopDiggPosts),具体见推荐博客 另外多线程爬虫代码也在这里面,比较简单,然后就是对数据进行排序处理了。见如下代码
具体完整代码
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 # @Time : 2019/5/7 21:37 4 # @Author : Empirefree 5 # @File : __init__.py.py 6 # @Software: PyCharm Community Edition 7 8 import requests 9 import re 10 import json 11 from bs4 import BeautifulSoup 12 from concurrent import futures 13 from wordcloud import WordCloud 14 import jieba 15 import os 16 from os import path 17 import smtplib 18 from email.mime.text import MIMEText 19 from email.utils import formataddr 20 from email.mime.image import MIMEImage 21 from email.mime.multipart import MIMEMultipart 22 23 def Cnblog_getUsers(): 24 r = requests.get('https://www.cnblogs.com/aggsite/UserStats') 25 # 使用BeautifulSoup解析推荐博客 26 soup = BeautifulSoup(r.text, 'lxml') 27 users = [(i.text, i['href']) for i in soup.select('#blogger_list > ul > li > a') if 28 'AllBloggers.aspx' not in i['href'] and 'expert' not in i['href']] 29 #print(json.dumps(users, ensure_ascii=False)) 30 return users 31 def My_Blog_Category(user): 32 myusers = user 33 category_re = re.compile('(.+)((d+))') 34 url = 'https://www.cnblogs.com/{0}/mvc/blog/sidecolumn.aspx'.format(myusers) 35 blogApp = myusers 36 payload = dict(blogApp = blogApp) 37 r = requests.get(url, params=payload) 38 # 使用BeautifulSoup解析推荐博客 39 soup = BeautifulSoup(r.text, 'lxml') 40 category = [re.search(category_re, i.text).groups() for i in soup.select('.catListPostCategory > ul > li') if 41 re.search(category_re, i.text)] 42 #print(json.dumps(category, ensure_ascii=False)) 43 return dict(category=category) 44 45 def getPostsDetail(Posts): 46 # 获取文章详细信息:标题,次数,URL 47 post_re = re.compile('d+. (.+)((d+))') 48 soup = BeautifulSoup(Posts, 'lxml') 49 return [list(re.search(post_re, i.text).groups()) + [i['href']] for i in soup.find_all('a')] 50 51 def My_Blog_Detail(user): 52 url = 'http://www.cnblogs.com/mvc/Blog/GetBlogSideBlocks.aspx' 53 blogApp = user 54 showFlag = 'ShowRecentComment, ShowTopViewPosts, ShowTopFeedbackPosts, ShowTopDiggPosts' 55 payload = dict(blogApp=blogApp, showFlag=showFlag) 56 r = requests.get(url, params=payload) 57 58 print(json.dumps(r.json(), ensure_ascii=False)) 59 #最新评论(数据有点不一样),阅读排行榜 评论排行榜 推荐排行榜 60 TopViewPosts = getPostsDetail(r.json()['TopViewPosts']) 61 TopFeedbackPosts = getPostsDetail(r.json()['TopFeedbackPosts']) 62 TopDiggPosts = getPostsDetail(r.json()['TopDiggPosts']) 63 #print(json.dumps(dict(TopViewPosts=TopViewPosts, TopFeedbackPosts=TopFeedbackPosts, TopDiggPosts=TopDiggPosts),ensure_ascii=False)) 64 return dict(TopViewPosts=TopViewPosts, TopFeedbackPosts=TopFeedbackPosts, TopDiggPosts=TopDiggPosts) 65 66 67 def My_Blog_getTotal(url): 68 # 获取博客全部信息,包括分类及排行榜信息 69 # 初始化博客用户名 70 print('Spider blog: {0}'.format(url)) 71 user = url.split('/')[-2] 72 print(user) 73 return dict(My_Blog_Detail(user), **My_Blog_Category(user)) 74 75 def mutiSpider(max_workers=4): 76 try: 77 with futures.ThreadPoolExecutor(max_workers=max_workers) as executor: # 多线程 78 #with futures.ProcessPoolExecutor(max_workers=max_workers) as executor: # 多进程 79 for blog in executor.map(My_Blog_getTotal, [i[1] for i in users]): 80 blogs.append(blog) 81 except Exception as e: 82 print(e) 83 def countCategory(category, category_name): 84 # 合并计算目录数 85 n = 0 86 for name, count in category: 87 if name.lower() == category_name: 88 n += int(count) 89 return n 90 91 if __name__ == '__main__': 92 #Cnblog_getUsers() 93 #user = 'meditation5201314' 94 #My_Blog_Category(user) 95 #My_Blog_Detail(user) 96 print(os.path.dirname(os.path.realpath(__file__))) 97 bmppath = os.path.dirname(os.path.realpath(__file__)) 98 blogs = [] 99 100 # 获取推荐博客列表 101 users = Cnblog_getUsers() 102 #print(users) 103 #print(json.dumps(users, ensure_ascii=False)) 104 105 # 多线程/多进程获取博客信息 106 mutiSpider() 107 #print(json.dumps(blogs,ensure_ascii=False)) 108 109 # 获取所有分类目录信息 110 category = [category for blog in blogs if blog['category'] for category in blog['category']] 111 112 # 合并相同目录 113 new_category = {} 114 for name, count in category: 115 # 全部转换为小写 116 name = name.lower() 117 if name not in new_category: 118 new_category[name] = countCategory(category, name) 119 sorted(new_category.items(), key=lambda i: int(i[1]), reverse=True) 120 print(new_category) 121 TopViewPosts = [post for blog in blogs for post in blog['TopViewPosts']] 122 sorted(TopViewPosts, key=lambda i: int(i[1]), reverse=True) 123 print(TopViewPosts)
4.生成词云
对推荐博客内容进行处理(List格式),有关词云具体使用可以百度,简单介绍就是在给定的img和txt生成图片,就是把2者结合起来,font_path是自己电脑本机上的,去C盘下面搜一下就行,不一定大家都一样。
注:词云安装:这个比较复杂,我在pycharm下面install 没安装好,我是先去官网下载了whl文件,然后在cmd下
pip install wordcloud-1.5.0-cp36-cp36m-win32.whl
,然后把生成的文件夹重新放入到pycharm的venv/Lib/site_packages/下面,然后就弄好了(个人推荐这种办法,百试不爽!)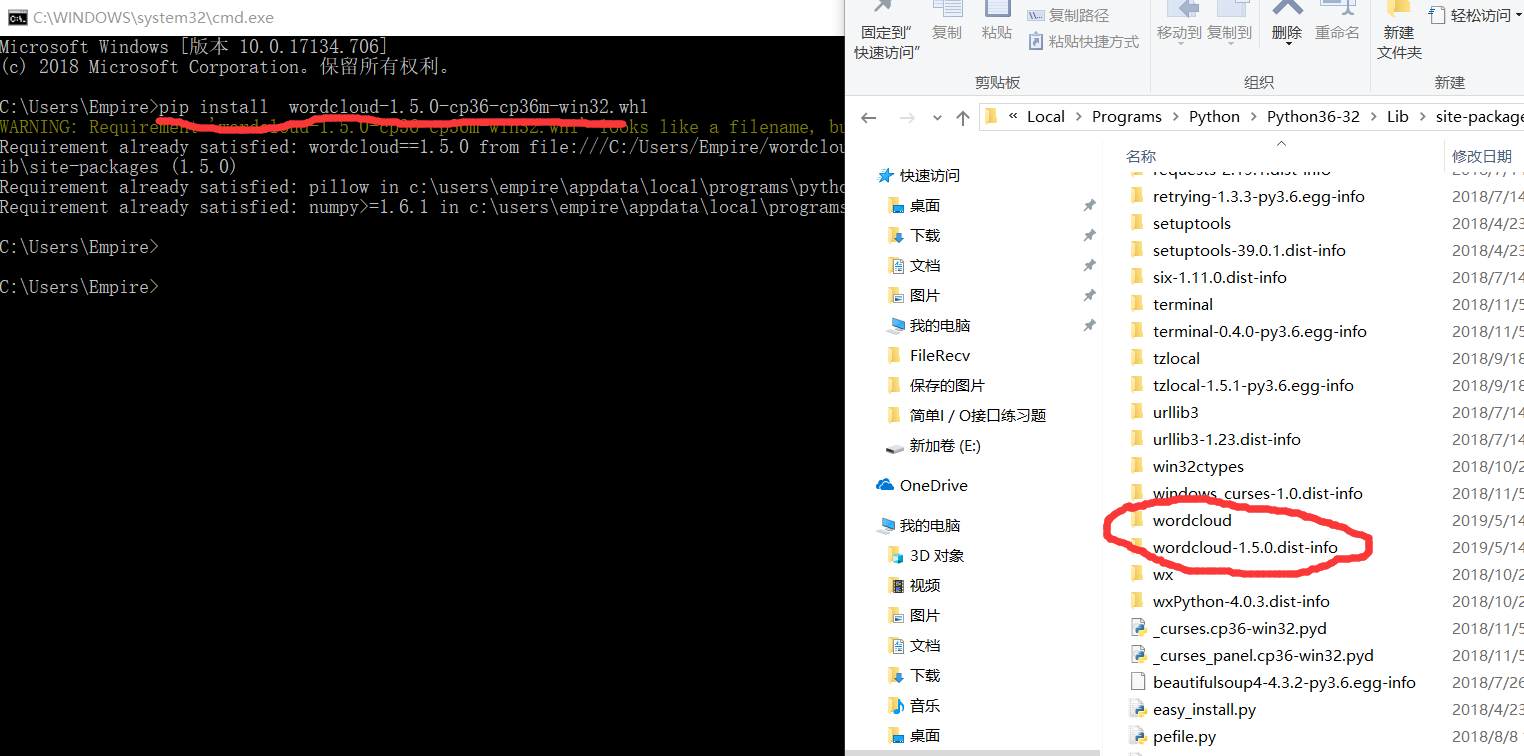
def View_wordcloud(TopViewPosts):
##生成词云
# 拼接为长文本
contents = ' '.join([i[0] for i in TopViewPosts])
# 使用结巴分词进行中文分词
cut_texts = ' '.join(jieba.cut(contents))
# 设置字体为黑体,最大词数为2000,背景颜色为白色,生成图片宽1000,高667
cloud = WordCloud(font_path='C:\Windows\WinSxS\amd64_microsoft-windows-b..core-fonts-chs-boot_31bf3856ad364e35_10.0.17134.1_none_ba644a56789f974c\msyh_boot.ttf', max_words=2000, background_color="white", width=1000,
height=667, margin=2)
# 生成词云
wordcloud = cloud.generate(cut_texts)
# 保存图片
file_name = 'avatar'
wordcloud.to_file('{0}.jpg'.format(file_name))
# 展示图片
wordcloud.to_image().show()
cloud.to_file(path.join(bmppath, 'temp.jpg'))
在上面代码中,我们利用cloud.to_file(path.join(bmppath, 'temp.jpg')),保存了temp.jpg,所以后面发送的图片就直接默认是temp.jpg了
5.发送邮件:
去QQ邮箱申请一下授权码,然后发送给自己就好了,内容嵌套img这个教麻烦,我查了很久,需要用cid指定一下,有点像ajax和format。
def Send_email():
my_sender = '1842449680@qq.com' # 发件人邮箱账号
my_pass = 'XXXXXXXX这里是你的授权码哎' # 发件人邮箱密码
my_user = '1842449680@qq.com' # 收件人邮箱账号,我这边发送给自己
ret = True
try:
msg = MIMEMultipart()
# msg = MIMEText('填写邮件内容', 'plain', 'utf-8')
msg['From'] = formataddr(["Empirefree", my_sender]) # 括号里的对应发件人邮箱昵称、发件人邮箱账号
msg['To'] = formataddr(["Empirefree", my_user]) # 括号里的对应收件人邮箱昵称、收件人邮箱账号
msg['Subject'] = "博客园首页推荐博客内容词云" # 邮件的主题,也可以说是标题
content = '<b>SKT 、<i>Empirefree</i> </b>向您发送博客园最近内容.<br><p><img src="cid:image1"><p>'
msgText = MIMEText(content, 'html', 'utf-8')
msg.attach(msgText)
fp = open('temp.jpg', 'rb')
img = MIMEImage(fp.read())
fp.close()
img.add_header('Content-ID', '<image1>')
msg.attach(img)
server = smtplib.SMTP_SSL("smtp.qq.com", 465) # 发件人邮箱中的SMTP服务器,端口是25
server.login(my_sender, my_pass) # 括号中对应的是发件人邮箱账号、邮箱密码
server.sendmail(my_sender, [my_user, ], msg.as_string()) # 括号中对应的是发件人邮箱账号、收件人邮箱账号、发送邮件
server.quit() # 关闭连接
except Exception: # 如果 try 中的语句没有执行,则会执行下面的 ret=False
ret = False
if ret:
print("邮件发送成功")
else:
print("邮件发送失败")
最终完整代码:
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 # @Time : 2019/5/7 21:37 4 # @Author : Empirefree 5 # @File : __init__.py.py 6 # @Software: PyCharm Community Edition 7 8 import requests 9 import re 10 import json 11 from bs4 import BeautifulSoup 12 from concurrent import futures 13 from wordcloud import WordCloud 14 import jieba 15 import os 16 from os import path 17 import smtplib 18 from email.mime.text import MIMEText 19 from email.utils import formataddr 20 from email.mime.image import MIMEImage 21 from email.mime.multipart import MIMEMultipart 22 23 def Cnblog_getUsers(): 24 r = requests.get('https://www.cnblogs.com/aggsite/UserStats') 25 # 使用BeautifulSoup解析推荐博客 26 soup = BeautifulSoup(r.text, 'lxml') 27 users = [(i.text, i['href']) for i in soup.select('#blogger_list > ul > li > a') if 28 'AllBloggers.aspx' not in i['href'] and 'expert' not in i['href']] 29 #print(json.dumps(users, ensure_ascii=False)) 30 return users 31 def My_Blog_Category(user): 32 myusers = user 33 category_re = re.compile('(.+)((d+))') 34 url = 'https://www.cnblogs.com/{0}/mvc/blog/sidecolumn.aspx'.format(myusers) 35 blogApp = myusers 36 payload = dict(blogApp = blogApp) 37 r = requests.get(url, params=payload) 38 # 使用BeautifulSoup解析推荐博客 39 soup = BeautifulSoup(r.text, 'lxml') 40 category = [re.search(category_re, i.text).groups() for i in soup.select('.catListPostCategory > ul > li') if 41 re.search(category_re, i.text)] 42 #print(json.dumps(category, ensure_ascii=False)) 43 return dict(category=category) 44 45 def getPostsDetail(Posts): 46 # 获取文章详细信息:标题,次数,URL 47 post_re = re.compile('d+. (.+)((d+))') 48 soup = BeautifulSoup(Posts, 'lxml') 49 return [list(re.search(post_re, i.text).groups()) + [i['href']] for i in soup.find_all('a')] 50 51 def My_Blog_Detail(user): 52 url = 'http://www.cnblogs.com/mvc/Blog/GetBlogSideBlocks.aspx' 53 blogApp = user 54 showFlag = 'ShowRecentComment, ShowTopViewPosts, ShowTopFeedbackPosts, ShowTopDiggPosts' 55 payload = dict(blogApp=blogApp, showFlag=showFlag) 56 r = requests.get(url, params=payload) 57 58 print(json.dumps(r.json(), ensure_ascii=False)) 59 #最新评论(数据有点不一样),阅读排行榜 评论排行榜 推荐排行榜 60 TopViewPosts = getPostsDetail(r.json()['TopViewPosts']) 61 TopFeedbackPosts = getPostsDetail(r.json()['TopFeedbackPosts']) 62 TopDiggPosts = getPostsDetail(r.json()['TopDiggPosts']) 63 #print(json.dumps(dict(TopViewPosts=TopViewPosts, TopFeedbackPosts=TopFeedbackPosts, TopDiggPosts=TopDiggPosts),ensure_ascii=False)) 64 return dict(TopViewPosts=TopViewPosts, TopFeedbackPosts=TopFeedbackPosts, TopDiggPosts=TopDiggPosts) 65 66 67 def My_Blog_getTotal(url): 68 # 获取博客全部信息,包括分类及排行榜信息 69 # 初始化博客用户名 70 print('Spider blog: {0}'.format(url)) 71 user = url.split('/')[-2] 72 print(user) 73 return dict(My_Blog_Detail(user), **My_Blog_Category(user)) 74 75 def mutiSpider(max_workers=4): 76 try: 77 with futures.ThreadPoolExecutor(max_workers=max_workers) as executor: # 多线程 78 #with futures.ProcessPoolExecutor(max_workers=max_workers) as executor: # 多进程 79 for blog in executor.map(My_Blog_getTotal, [i[1] for i in users]): 80 blogs.append(blog) 81 except Exception as e: 82 print(e) 83 def countCategory(category, category_name): 84 # 合并计算目录数 85 n = 0 86 for name, count in category: 87 if name.lower() == category_name: 88 n += int(count) 89 return n 90 91 def View_wordcloud(TopViewPosts): 92 ##生成词云 93 # 拼接为长文本 94 contents = ' '.join([i[0] for i in TopViewPosts]) 95 # 使用结巴分词进行中文分词 96 cut_texts = ' '.join(jieba.cut(contents)) 97 # 设置字体为黑体,最大词数为2000,背景颜色为白色,生成图片宽1000,高667 98 cloud = WordCloud(font_path='C:\Windows\WinSxS\amd64_microsoft-windows-b..core-fonts-chs-boot_31bf3856ad364e35_10.0.17134.1_none_ba644a56789f974c\msyh_boot.ttf', max_words=2000, background_color="white", width=1000, 99 height=667, margin=2) 100 # 生成词云 101 wordcloud = cloud.generate(cut_texts) 102 # 保存图片 103 file_name = 'avatar' 104 wordcloud.to_file('{0}.jpg'.format(file_name)) 105 # 展示图片 106 wordcloud.to_image().show() 107 cloud.to_file(path.join(bmppath, 'temp.jpg')) 108 109 def Send_email(): 110 my_sender = '1842449680@qq.com' # 发件人邮箱账号 111 my_pass = 'XXXXXXXX' # 授权码 112 my_user = '1842449680@qq.com' # 收件人邮箱账号,我这边发送给自己 113 114 115 ret = True 116 try: 117 118 msg = MIMEMultipart() 119 # msg = MIMEText('填写邮件内容', 'plain', 'utf-8') 120 msg['From'] = formataddr(["Empirefree", my_sender]) # 括号里的对应发件人邮箱昵称、发件人邮箱账号 121 msg['To'] = formataddr(["Empirefree", my_user]) # 括号里的对应收件人邮箱昵称、收件人邮箱账号 122 msg['Subject'] = "博客园首页推荐博客内容词云" # 邮件的主题,也可以说是标题 123 124 content = '<b>SKT 、<i>Empirefree</i> </b>向您发送博客园最近内容.<br><p><img src="cid:image1"><p>' 125 msgText = MIMEText(content, 'html', 'utf-8') 126 msg.attach(msgText) 127 fp = open('temp.jpg', 'rb') 128 img = MIMEImage(fp.read()) 129 fp.close() 130 img.add_header('Content-ID', '<image1>') 131 msg.attach(img) 132 133 server = smtplib.SMTP_SSL("smtp.qq.com", 465) # 发件人邮箱中的SMTP服务器,端口是25 134 server.login(my_sender, my_pass) # 括号中对应的是发件人邮箱账号、邮箱密码 135 server.sendmail(my_sender, [my_user, ], msg.as_string()) # 括号中对应的是发件人邮箱账号、收件人邮箱账号、发送邮件 136 server.quit() # 关闭连接 137 except Exception: # 如果 try 中的语句没有执行,则会执行下面的 ret=False 138 ret = False 139 if ret: 140 print("邮件发送成功") 141 else: 142 print("邮件发送失败") 143 144 if __name__ == '__main__': 145 #Cnblog_getUsers() 146 #user = 'meditation5201314' 147 #My_Blog_Category(user) 148 #My_Blog_Detail(user) 149 print(os.path.dirname(os.path.realpath(__file__))) 150 bmppath = os.path.dirname(os.path.realpath(__file__)) 151 blogs = [] 152 153 # 获取推荐博客列表 154 users = Cnblog_getUsers() 155 #print(users) 156 #print(json.dumps(users, ensure_ascii=False)) 157 158 # 多线程/多进程获取博客信息 159 mutiSpider() 160 #print(json.dumps(blogs,ensure_ascii=False)) 161 162 # 获取所有分类目录信息 163 category = [category for blog in blogs if blog['category'] for category in blog['category']] 164 165 # 合并相同目录 166 new_category = {} 167 for name, count in category: 168 # 全部转换为小写 169 name = name.lower() 170 if name not in new_category: 171 new_category[name] = countCategory(category, name) 172 sorted(new_category.items(), key=lambda i: int(i[1]), reverse=True) 173 print(new_category) 174 TopViewPosts = [post for blog in blogs for post in blog['TopViewPosts']] 175 sorted(TopViewPosts, key=lambda i: int(i[1]), reverse=True) 176 print(TopViewPosts) 177 178 View_wordcloud(TopViewPosts) 179 Send_email()
总结:总体功能就是根据推荐博客,爬取推荐用户的阅读排行榜 评论排行榜 推荐排行榜,然后数据处理成,将处理好的数据整合成词云,最后发送给用户
难点1:爬取用户和博客所用到的一系列爬虫知识(正则,解析等等)
难点2:词云的安装(确实挺麻烦的。。。。。)
难点3:邮件发送内容嵌套image(菜鸟教程没有给出QQ邮箱内嵌套图片,自己去官网找的。)