MapReduce(四)
1.shuffle过程
2.map中setup,map,cleanup的作用。
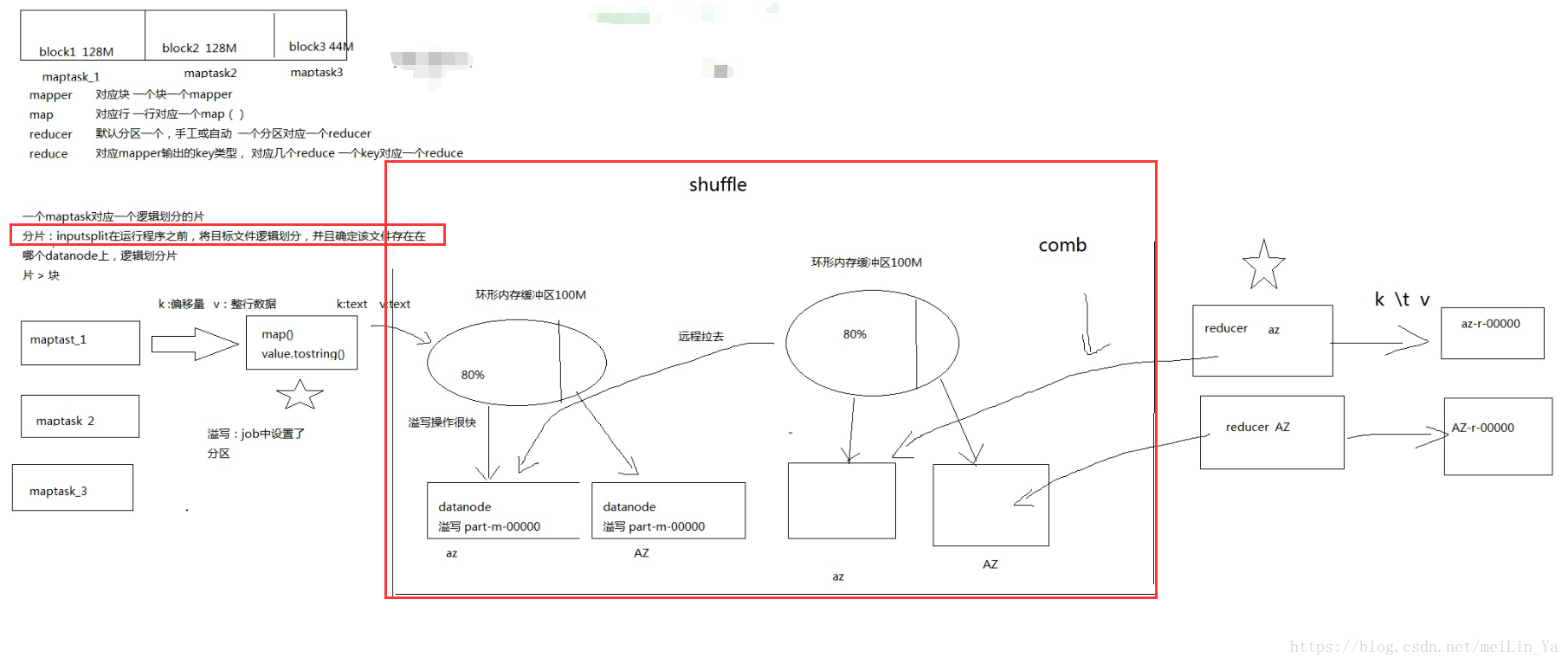
一.shuffle过程
https://blog.csdn.net/techchan/article/details/53405519
来张图吧
二.map中setup,map,cleanup的作用。
- setup(),此方法被MapReduce框架仅且执行一次,在执行Map任务前,进行相关变量或者资源的集中初始化工作。若是将资源初始化工作放在方法map()中,导致Mapper任务在解析每一行输入时都会进行资源初始化工作,导致重复,程序运行效率不高!
- run()映射k,v 数据
- cleanup(),此方法被MapReduce框架仅且执行一次,在执行完毕Map任务后,进行相关变量或资源的释放工作。若是将释放资源工作放入方法map()中,也会导致Mapper任务在解析、处理每一行文本后释放资源,而且在下一行文本解析前还要重复初始化,导致反复重复,程序运行效率不高!
代码测试 Cleanup的作用
package com.huhu.day04;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.net.URI;
import java.util.HashSet;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.filecache.DistributedCache;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* 在这里进行wordCount统计 在一遍英语单词中 不统计 i have 这两个单词
*
* @author huhu_k
*
*/
public class TestCleanUpEffect extends ToolRunner implements Tool {
private Configuration conf;
public static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private Path[] localCacheFiles;
// 不通过MapReduce过滤计算的word
private HashSet<String> keyWord;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
Configuration conf = context.getConfiguration();
localCacheFiles = DistributedCache.getLocalCacheFiles(conf);
keyWord = new HashSet<>();
for (Path p : localCacheFiles) {
BufferedReader br = new BufferedReader(new FileReader(p.toString()));
String word = "";
while ((word = br.readLine()) != null) {
String[] str = word.split(" ");
for (String s : str) {
keyWord.add(s);
}
}
br.close();
}
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] line = value.toString().split(" ");
for (String str : line) {
for (String k : keyWord) {
if (!str.contains(k)) {
context.write(new Text(str), new IntWritable(1));
}
}
}
}
@Override
protected void cleanup(Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
}
}
public static class MyReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable v : values) {
sum += v.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
TestCleanUpEffect t = new TestCleanUpEffect();
Configuration conf = t.getConf();
String[] other = new GenericOptionsParser(conf, args).getRemainingArgs();
if (other.length != 2) {
System.err.println("number is fail");
}
int run = ToolRunner.run(conf, t, args);
System.exit(run);
}
@Override
public Configuration getConf() {
if (conf != null) {
return conf;
}
return new Configuration();
}
@Override
public void setConf(Configuration arg0) {
}
@Override
public int run(String[] other) throws Exception {
Configuration con = getConf();
DistributedCache.addCacheFile(new URI("hdfs://ry-hadoop1:8020/in/advice.txt"), con);
Job job = Job.getInstance(con);
job.setJarByClass(TestCleanUpEffect.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(other[0]));
FileOutputFormat.setOutputPath(job, new Path(other[1]));
return job.waitForCompletion(true) ? 0 : 1;
}
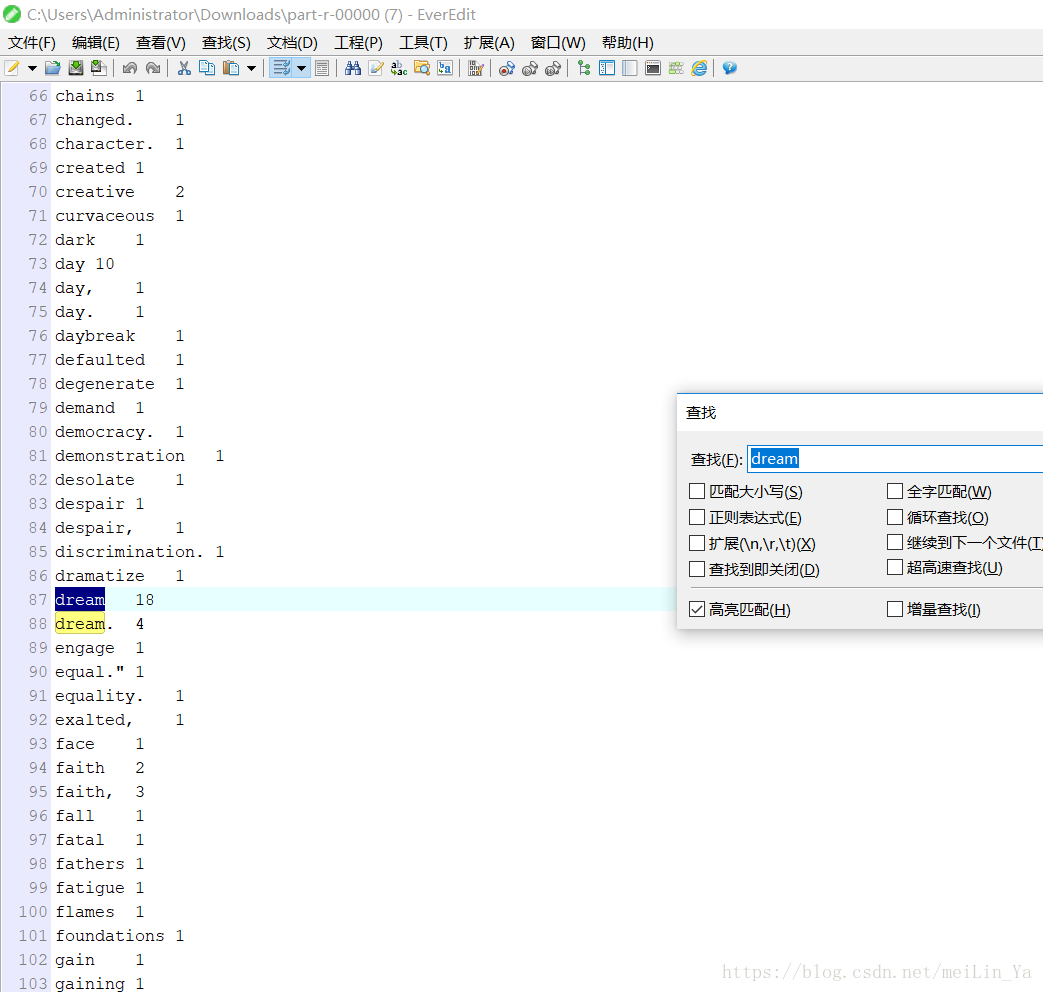
}我是使用在setup中过滤另一个文件:advice 然后通过运行,wordCount时,adivce中有的word则过滤不计算。我的数据分别是:

运行结果:
测试mapper中cleanup的作用
package com.huhu.day04;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class TestCleanUpEffect extends ToolRunner implements Tool {
private Configuration conf;
public static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private Map<String, Integer> map = new HashMap<String, Integer>();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] line = value.toString().split(" ");
for (String s : line) {
if (map.containsKey(s)) {
map.put(s, map.get(s) + 1);
} else {
map.put(s, 1);
}
}
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
for (Map.Entry<String, Integer> m : map.entrySet()) {
context.write(new Text(m.getKey()), new IntWritable(m.getValue()));
}
}
}
public static class MyReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void setup(Context context) throws IOException, InterruptedException {
}
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
for (IntWritable v : values) {
context.write(key, new IntWritable(v.get()));
}
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
}
}
public static void main(String[] args) throws Exception {
TestCleanUpEffect t = new TestCleanUpEffect();
Configuration conf = t.getConf();
String[] other = new GenericOptionsParser(conf, args).getRemainingArgs();
if (other.length != 2) {
System.err.println("number is fail");
}
int run = ToolRunner.run(conf, t, args);
System.exit(run);
}
@Override
public Configuration getConf() {
if (conf != null) {
return conf;
}
return new Configuration();
}
@Override
public void setConf(Configuration arg0) {
}
@Override
public int run(String[] other) throws Exception {
Configuration con = getConf();
Job job = Job.getInstance(con);
job.setJarByClass(TestCleanUpEffect.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// 默认分区
job.setPartitionerClass(HashPartitioner.class);
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(other[0]));
FileOutputFormat.setOutputPath(job, new Path(other[1]));
return job.waitForCompletion(true) ? 0 : 1;
}
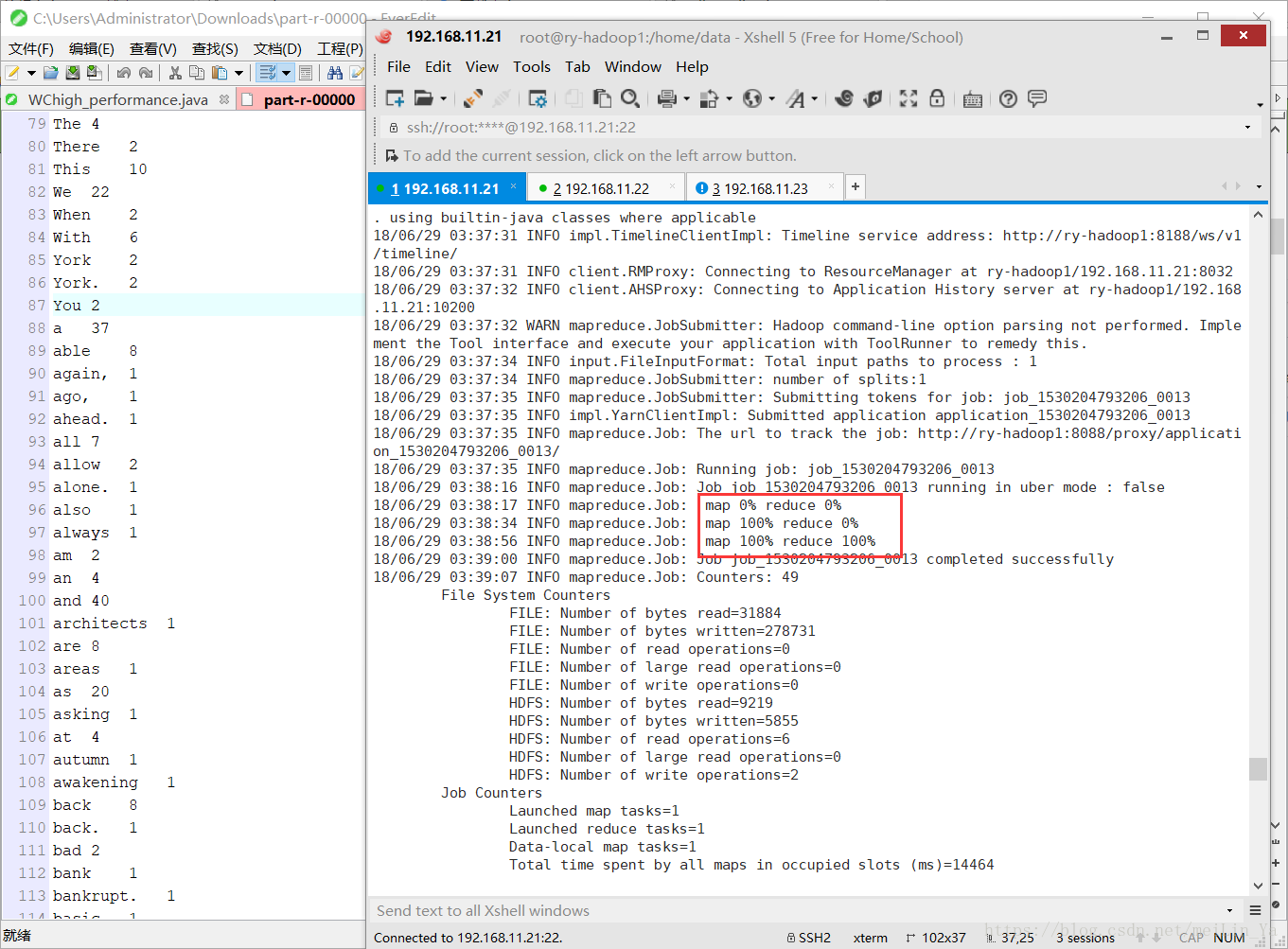
}使用map来处理数据,减小reducer的压力,并使用mapper中的cleanup方法
运行结果
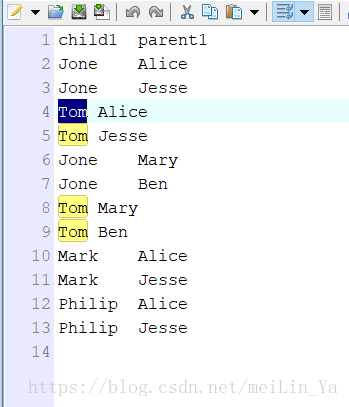
打印孩子的所有父母(爷爷,姥爷,奶奶,姥姥),看下数据

package com.huhu.day04;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* 分代计算 将 孩子 父母 奶奶 姥姥 分为一代
*
* @author huhu_k
*
*/
public class ProgenyCount extends ToolRunner implements Tool {
public static class MyMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] line = value.toString().split(" ");
String childname = line[0];
String parentname = line[1];
if (line.length == 2 && !value.toString().contains("child")) {
context.write(new Text(childname), new Text("t1:" + childname + ":" + parentname));
context.write(new Text(parentname), new Text("t2:" + childname + ":" + parentname));
}
}
}
public static class MyReduce extends Reducer<Text, Text, Text, Text> {
boolean flag = true;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
}
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
if (flag) {
context.write(new Text("child1"), new Text("parent1"));
flag = false;
}
List<String> child = new ArrayList<>();
List<String> parent = new ArrayList<>();
for (Text v : values) {
String line = v.toString();
System.out.println(line+"**");
if (line.contains("t1")) {
parent.add(line.split(":")[2]);
System.err.println(line.split(":")[2]);
} else if (line.contains("t2")) {
System.out.println(line.split(":")[1]);
child.add(line.split(":")[1]);
}
}
for (String c : child) {
for (String p : parent) {
context.write(new Text(c), new Text(p));
}
}
}
}
public static void main(String[] args) throws Exception {
ProgenyCount t = new ProgenyCount();
Configuration conf = t.getConf();
String[] other = new GenericOptionsParser(conf, args).getRemainingArgs();
if (other.length != 2) {
System.err.println("number is fail");
}
int run = ToolRunner.run(conf, t, args);
System.exit(run);
}
@Override
public Configuration getConf() {
return new Configuration();
}
@Override
public void setConf(Configuration arg0) {
}
@Override
public int run(String[] other) throws Exception {
Configuration con = getConf();
Job job = Job.getInstance(con);
job.setJarByClass(ProgenyCount.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// 默认分区
// job.setPartitionerClass(HashPartitioner.class);
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path("hdfs://ry-hadoop1:8020/in/child.txt"));
Path path = new Path("hdfs://ry-hadoop1:8020/out/mr");
FileSystem fs = FileSystem.get(getConf());
if (fs.exists(path)) {
fs.delete(path, true);
}
FileOutputFormat.setOutputPath(job, path);
return job.waitForCompletion(true) ? 0 : 1;
}
}