http数据流分析
http请求报文结构:请求行、首部、空行、主体。
如下图:
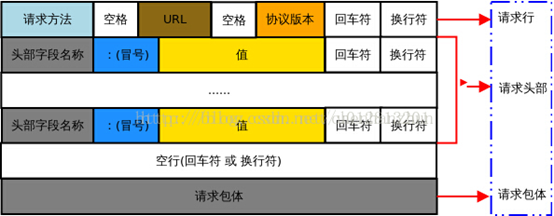
请求行分为:请求方法、url、协议版本
1、常用请求方法有如下几种:
GET:从服务器获取一份文档
HEAD:只从服务器获取文档的首部
POST:向服务器发送需要处理的数据,常用于表单提交。
PUT:将请求的主体部分存储在服务器上,从服务器上向客户发送文档
TRACE:对可能经过代理服务器传送到服务器上去的报文进行追踪
OPTIONS:决定可以在服务器上执行哪些方法
DELETE:从服务器上删除一份文档
2、url:
HTTP使用统一资源定位符(URL):协议:// 主机:端口 / 路径
3、协议版本
http/1.0和http/1.1
首部由头部字段名称加值构成
一. 通用头部字段 (General Header Fields)
该字段在请求头和响应头都会使用到,下方是常用的通用头部字段:
1、 Cache-Control
用来操作缓存的工作机制,下方截图响应头中的的Cache-Control的参数为private和max-age=10。private缓存是私有的,仅像特定用户提供相应的缓存信息。如果是public,那么就意味着可向任意方提供相应的缓存信息。max-age = 10表示缓存有效期为10秒。从下方的Expires(过期时间)和Last-Modified(最后修改时间)就可以看出,这两者之间的差值正好是10秒。
2、Connection
该字段可以控制不转发给代理服务器的首部字段以及管理持久连接,下方这个响应报文头中的Connection就是用来管理持久连接的,其参数为keep-alive,就是保持持久连接的意思。可以使用close参数将其关闭。
3、Transfer-Encoding
该字段表示报文在传输过程中采用的编码方式,在HTTP/1.1的报文传输过程中仅对分块编码有效。下方这个截图就是Transfer-Encoding在Response Header中的使用,后边根的chunked(分块)的参数,说明报文是分块进行传输的。
4、Via
该字段是为了追踪请求和响应报文测传输路径,报文经过代理或者网关是会在Via字段添加该服务器的信息,然后再进行转发。
二.请求头部字段 (Request Header Fields)
顾名思义,请求头部字段当然是在请求头中才使用的字段。该字段用于补充请求的附加信息,客户端信息等。接下来将给出常用而且比较重要的几个请求头部字段。
1 Accept
该字段可通知服务器用户代理能够处理的媒体类型以及该媒体类型对应的优先级。媒体类型可使用“type/subtype”这种形式来指定,分号后边紧跟着的是该类型的优先级。如下所示。
2 Accept-Encoding
该字段用来告知服务器,客户端这边可支持的内容编码以及相应内容编码的优先级, 下方就是Accept-Encoding的用法。gzip表示由文件压缩程序gzip(GNU zip)生成的编码格式。compress表示UNIX文件压缩程序compress生成的编码格式。deflate表示组合使用zlib格式以及有deflate压缩算法生成的编码格式。identity表示不执行压缩或者使用一致的默认编码格式。
3 Accept-Language
该字段用来告知服务器,客户端可处理的自然语言集,以及对应语言集的优先级。以下方的截图为例,Accept-Language后方跟了三个属性,分别是“zh-CN”, "zh;q=0.8",“en;q=0.6”。也就是说客户端可处理三种自然预言集,zh-CN,其优先级是1(最高)。第二种是zh ,其优先级是0.8,次之。第三个是en,优先级为0.6,优先级在三者之间最低。
4 Authorization
用来告知服务器用户端的认证信息,下方就是连接公司内部SVN系统时需要认证时的请求头部信息。
如果你没有填写认证信息的话,那么就会返回401 Unauthorized。
5 If-Match 与If-None-Match
上面这两个请求头部字段都是带有逻辑判断的,从上面的英文我们不难看出两者恰好相反。两者后方都跟着串字符串,如If-Match "xcsldjh49773hce", 后边这个字符的匹配对象是ETag(稍后会介绍)。If-Match的请求是如果后方的字符串与ETag相等则服务器端进行请求,否则不进行处理。If-None-Match是If-Match的非操作,同样是匹配ETag, 如果Etag没有匹配成功就处理请求,否则不处理。
6 If-Modified-Since与If-Unmodified-Since
If-Modified-Since也是带有逻辑判断的请求头部字段,该字段后方跟的是一个日期,意思是在该日期后发生了资源更新,那么服务器就会处理该请求。If-Unmodified-Since就是 If-Modified-Since的非操作。
7 If-Range
if-Range字段后方也是跟的Etag, 该字段要结合着Range字段进行使用。其所代表的意思就是如果Etag匹配成功,请求的内容就按照Range字段所规定的范围进行返回,否则返回全部的内容。
8 Referer
其实Referer是一个错误的拼写,但是一直在使用。正确的英文单词应该是Referrer(此处可翻译为:来历、来路)。Referer字段后方跟的是一个URI, 该URI就是发起请求的URI
9 User-Agent
该字段会将请求方的浏览器和用户代理名称等信息传达给服务器。下方就是从我当前笔记本的Chrome浏览器请求网络时的User-Agent信息。
Burp抓包分析
GET报文

该报文采用get方式请求资源,资源位置是/show_content.asp,请求的参数是articleid,参数值为13591,采用http/1.1的版本
首部字段包括,host、accept、user-agent、referer、cookie等等。各个字段具体含义上面有详解。
POST报文
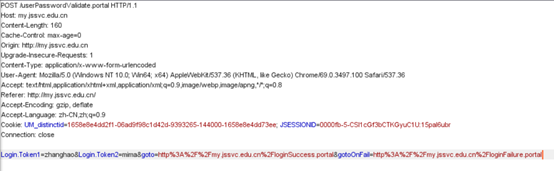
该报文采用post方式请求资源,资源位置是/userpasswordvaldate.portal,请求的参数是login.token1、login.token2等,参数值为zhanghao、mima,采用http/1.1的版本
首部字段包括,host、accept、user-agent、referer、cookie等等。各个字段具体含义上面有详解
http响应报文结构:状态行、首部、空格、主体
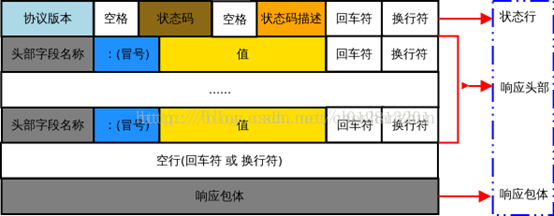
状态行:协议版本 (空格) 状态码 (空格) 短语
协议版本有http/1.0和http/1.1
状态码描述文本有如下取值:
200 OK:表示客户端请求成功;
400 Bad Request:表示客户端请求有语法错误,不能被服务器所理解;
401 Unauthonzed:表示请求未经授权,该状态代码必须与 WWW-Authenticate 报头域一起使用;
403 Forbidden:表示服务器收到请求,但是拒绝提供服务,通常会在响应正文中给出不提供服务的原因;
404 Not Found:请求的资源不存在,例如,输入了错误的URL;
500 Internal Server Error:表示服务器发生不可预期的错误,导致无法完成客户端的请
503 Service Unavailable:表示服务器当前不能够处理客户端的请求,在一段时间之后,服务器可能会恢复正常;
响应首部:首部名 :(空格)首部值
1 Accept-Ranges
该字段用来告知客户端服务器那边是否支持范围请求(请求部分内容,请求头中使用Range字段)。Accept-Ranges的值为bytes时,就说明服务器支持范围请求,为none时,说明服务器不支持客户端的范围请求。
2 Age
该字段告知客户端,源服务器在多久前创建了该响应。
3 Etag
Etag是服务器当前请求的服务器资源(图片,HTML页面等)所对应的一个独有的字符串。不同资源间的Etag是不同的,当资源更新时Etag也会进行更新。
所以结合着请求头中的If-Match等逻辑请求头,可以判断当前Client端已经加载的资源在服务器端是否已经更新了。当初次请求一个资源,如图片时,我们可以将其Etag进行保存,在此请求时,可放在If-None-Match后方,进行资源更新。如果服务器资源并未修改,就不对该请求做出响应。
4 Location
Location字段一般与重定向结合着使用。比如我访问“www.baidu.com/hello”这个连接的响应报文。因为服务器上并没有/hello这个资源路径,所以给我重定向了error.html页面,这个重定向的URL就存储在Location字段中
5 Server
该响应字段表明了服务器端使用的服务器型号,下方是博客园某张图片的响应头,使用的Web服务器是Tengine, Tengin是淘宝发起的Web服务器项目,是基于Nginx的,关于Tengin的相关内容,请自行Google吧。
6 Vary
Vary可对缓存进行控制,通过该字段,源服务器会向代理服务器传达关于本地缓存使用方法的命令。下方就是Vary的使用,Vary后方的参数是Accept-Encoding。其意思是返回的缓存要以Accept-Encoding为准。当请求的Accept-Encoding的参数与缓存内容的Accept-Encoding参数一致时就返回缓存内容,否则就请求源服务器。
7 WWW-Authenticate
该字段用于HTTP的访问认证,在状态码401 Unauthorized中肯定带有此字段,该字段用来指定客户端的认证方案(Basic或者Digest)。参数realm的字符串是为了辨别请求URL指定资源所受到的保护策略。
响应主体:服务器返回给客户端的文本信息;
Html格式的文档。
Burp抓包分析

报文用了http/1.1版本的协议,使用了cache-controt、content-type、exprires、server、setcookie等字段,字段具体含义上面有详细解释。
报文主题是html文档。
HTTP协议通信机制
大家都知道一般的通信流程:首先客户端发送一个请求(request)给服务器,服务器在接收到这个请求后将生成一个响应(response)返回给客户端。
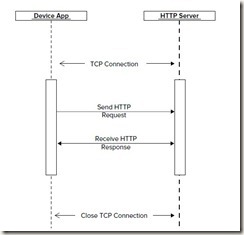
1. Request和Response的格式
Request格式:
HTTP请求行
(请求)头
空行
可选的消息体
注:请求行和标题必须以<CR><LF> 作为结尾(也就是,回车然后换行)。空行内必须只有<CR><LF>而无其他空格。在HTTP/1.1 协议中,所有的请求头,除Host外,都是可选的。
实例:
GET / HTTP/1.1
Host: gpcuster.cnblogs.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US; rv:1.9.0.10) Gecko/2009042316 Firefox/3.0.10
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-us,en;q=0.5
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Keep-Alive: 300
Connection: keep-alive
If-Modified-Since: Mon, 25 May 2009 03:19:18 GMT
Response格式:
HTTP状态行
(应答)头
空行
可选的消息体
实例:
HTTP/1.1 200 OK
Cache-Control: private, max-age=30
Content-Type: text/html; charset=utf-8
Content-Encoding: gzip
Expires: Mon, 25 May 2009 03:20:33 GMT
Last-Modified: Mon, 25 May 2009 03:20:03 GMT
Vary: Accept-Encoding
Server: Microsoft-IIS/7.0
X-AspNet-Version: 2.0.50727
X-Powered-By: ASP.NET
Date: Mon, 25 May 2009 03:20:02 GMT
Content-Length: 12173
消息体的内容(略)
2. 建立连接的方式
HTTP支持2中建立连接的方式:非持久连接和持久连接(HTTP1.1默认的连接方式为持久连接)。
1) 非持久连接
让我们查看一下非持久连接情况下从服务器到客户传送一个Web页面的步骤。假设该贝面由1个基本HTML文件和10个JPEG图像构成,而且所有这些对象都存放在同一台服务器主机中。再假设该基本HTML文件的URL为:gpcuster.cnblogs.com/index.html。
下面是具体步骡:
1.HTTP客户初始化一个与服务器主机gpcuster.cnblogs.com中的HTTP服务器的TCP连接。HTTP服务器使用默认端口号80监听来自HTTP客户的连接建立请求。
2.HTTP客户经由与TCP连接相关联的本地套接字发出—个HTTP请求消息。这个消息中包含路径名/somepath/index.html。
3.HTTP服务器经由与TCP连接相关联的本地套接字接收这个请求消息,再从服务器主机的内存或硬盘中取出对象/somepath/index.html,经由同一个套接字发出包含该对象的响应消息。
4.HTTP服务器告知TCP关闭这个TCP连接(不过TCP要到客户收到刚才这个响应消息之后才会真正终止这个连接)。
5.HTTP客户经由同一个套接字接收这个响应消息。TCP连接随后终止。该消息标明所封装的对象是一个HTML文件。客户从中取出这个文件,加以分析后发现其中有10个JPEG对象的引用。
6.给每一个引用到的JPEG对象重复步骡1-4。
上述步骤之所以称为使用非持久连接,原因是每次服务器发出一个对象后,相应的TCP连接就被关闭,也就是说每个连接都没有持续到可用于传送其他对象。每个TCP连接只用于传输一个请求消息和一个响应消息。就上述例子而言,用户每请求一次那个web页面,就产生11个TCP连接。
2) 持久连接
非持久连接有些缺点。首先,客户得为每个待请求的对象建立并维护一个新的连接。对于每个这样的连接,TCP得在客户端和服务器端分配TCP缓冲区,并维持TCP变量。对于有可能同时为来自数百个不同客户的请求提供服务的web服务器来说,这会严重增加其负担。其次,如前所述,每个对象都有2个RTT的响应延长——一个RTT用于建立TCP连接,另—个RTT用于请求和接收对象。最后,每个对象都遭受TCP缓启动,因为每个TCP连接都起始于缓启动阶段。不过并行TCP连接的使用能够部分减轻RTT延迟和缓启动延迟的影响。
在持久连接情况下,服务器在发出响应后让TCP连接继续打开着。同一对客户/服务器之间的后续请求和响应可以通过这个连接发送。整个Web页面(上例中为包含一个基本HTMLL文件和10个图像的页面)自不用说可以通过单个持久TCP连接发送:甚至存放在同一个服务器中的多个web页面也可以通过单个持久TCP连接发送。通常,HTTP服务器在某个连接闲置一段特定时间后关闭它,而这段时间通常是可以配置的。持久连接分为不带流水线(without pipelining)和带流水线(with pipelining)两个版本。如果是不带流水线的版本,那么客户只在收到前一个请求的响应后才发出新的请求。这种情况下,web页面所引用的每个对象(上例中的10个图像)都经历1个RTT的延迟,用于请求和接收该对象。与非持久连接2个RTT的延迟相比,不带流水线的持久连接已有所改善,不过带流水线的持久连接还能进一步降低响应延迟。不带流水线版本的另一个缺点是,服务器送出一个对象后开始等待下一个请求,而这个新请求却不能马上到达。这段时间服务器资源便闲置了。
HTTP/1.1的默认模式使用带流水线的持久连接。这种情况下,HTTP客户每碰到一个引用就立即发出一个请求,因而HTTP客户可以一个接一个紧挨着发出各个引用对象的请求。服务器收到这些请求后,也可以一个接一个紧挨着发出各个对象。如果所有的请求和响应都是紧挨着发送的,那么所有引用到的对象一共只经历1个RTT的延迟(而不是像不带流水线的版本那样,每个引用到的对象都各有1个RTT的延迟)。另外,带流水线的持久连接中服务器空等请求的时间比较少。与非持久连接相比,持久连接(不论是否带流水线)除降低了1个RTT的响应延迟外,缓启动延迟也比较小。其原因在于既然各个对象使用同一个TCP连接,服务器发出第一个对象后就不必再以一开始的缓慢速率发送后续对象。相反,服务器可以按照第一个对象发送完毕时的速率开始发送下一个对象。
3. 缓存的机制
HTTP/1.1中缓存的目的是为了在很多情况下减少发送请求,同时在许多情况下可以不需要发送完整响应。前者减少了网络回路的数量;HTTP利用一个“过期(expiration)”机制来为此目的。后者减少了网络应用的带宽;HTTP用“验证(validation)”机制来为此目的。
HTTP定义了3种缓存机制:
l Freshness allows a response to be used without re-checking it on the origin server, and can be controlled by both the server and the client. For example, the Expires response header gives a date when the document becomes stale, and the Cache-Control: max-age directive tells the cache how many seconds the response is fresh for.
l Validation can be used to check whether a cached response is still good after it becomes stale. For example, if the response has a Last-Modified header, a cache can make a conditional request using the If-Modified-Since header to see if it has changed.
l Invalidation is usually a side effect of another request that passes through the cache. For example, if URL associated with a cached response subsequently gets a POST, PUT or DELETE request, the cached response will be invalidated.
4. 响应授权激发机制
这些机制能被用于服务器激发客户端请求并且使客户端授权。
详细的信息请参考:RFC 2617: HTTP Authentication: Basic and Digest Access
5. 基于HTTP的应用
多线程下载
- 下载工具开启多个发出HTTP请求的线程
- 每个http请求只请求资源文件的一部分:Content-Range: bytes 20000-40000/47000
- 合并每个线程下载的文件
6.HTTPS传输协议原理
两种基本的加解密算法类型

通信过程:
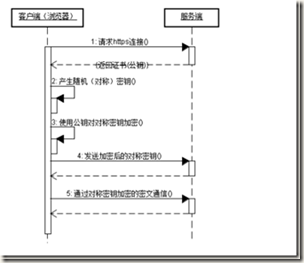
优点:
- 客户端产生的密钥只有客户端和服务器端能得到
- 加密的数据只有客户端和服务器端才能得到明文
- 客户端到服务端的通信是安全的
- 服务器和客户端交互:
7.http请求的几个方法:
我们经常会遇到这个问题GET和POST的区别
我们看看GET和POST的区别
1. GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,如EditPosts.aspx?name=test1&id=123456. POST方法是把提交的数据放在HTTP包的Body中.
2. GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制.
3. GET方式需要使用Request.QueryString来取得变量的值,而POST方式通过Request.Form来获取变量的值。
4. GET方式提交数据,会带来安全问题,比如一个登录页面,通过GET方式提交数据时,用户名和密码将出现在URL上,如果页面可以被缓存或者其他人可以访问这台机器,就可以从历史记录获得该用户的账号和密码.