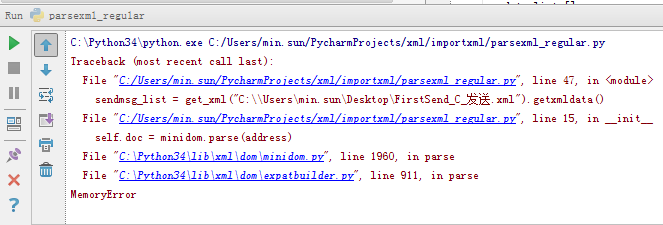
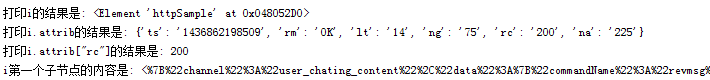在使用minido解析xml文件时,因为文件过大,结果报错MemoryError。查询后得知是因为minidom在解析时是将所有文件放到内存里的,很占用内存,所以要考虑换一种方法来处理xml文件。
ElementTree相比minidom消耗内存更小,下面是ElementTree的一些简单用法
XML源文件中的部分内容:

#导入ElementTree
from xml.etree import ElementTree
#读入并解析XML文件,读入的是树形结构
doc = ET.parse(XML文件地址)
#.getroot()获得xml文件的根节点
root = self.doc.getroot()
#.findall()找到根节点下的所有子节点
httpSample_nodes = root.findall('httpSample') #httpSample为子节点的tag
for i in httpSample_nodes:
print("打印i的结果是:",i)
#.attrib获得节点的所有属性结果存在字典结构里
print("打印i.attrib的结果是:",i.attrib)
#.attrib["rc"]获得节点"rc"的属性值
print('打印i.attrib["rc"]的结果是:',i.attrib["rc"])
#.getchildren()获得节点的所有子节点,.getchildren()[0]获得子节点的第一个子节点
i.getchildren()[0]
#.text获得节点的内容
print("打印i的text的结果是:",i.text)
print("i第一个子节点的内容是:",i.getchildren()[0].text)
具体的打印结果如下: