一:pandas
两种数据结构:series和dataframe
series:索引(索引自动生成)和标签(人为定义)组成---返回一个对象
obj = pd.Series([1,2,3,4]) obj
# 结果 0 1 1 2 2 3 3 4 dtype: int64
obj = pd.Series(["姓名","年龄","身高","体重"]) obj
# 结果 0 姓名 1 年龄 2 身高 3 体重 dtype: object
obj.values
array(['姓名', '年龄', '身高', '体重'], dtype=object)
obj.index
RangeIndex(start=0, stop=4, step=1)
指定索引
obj = pd.Series(["姓名","年龄","身高","体重"],index=[5,4,3,2]) obj 5 姓名 4 年龄 3 身高 2 体重 dtype: object
通过索引取值
# 取一个值
obj[2] '体重'
# 取一组值
obj[[2,3,5]] 2 体重 3 身高 5 姓名 dtype: object
保留索引值的链接
obj = pd.Series([1,2,3,4],index=["a","b","c","d"]) obj a 1 b 2 c 3 d 4 dtype: int64 obj[obj>2] c 3 d 4 dtype: int64
np.exp(obj) a 2.718282 e ** 1 b 7.389056 e ** 2 c 20.085537 e ** 3 d 54.598150 e **4 dtype: float64
series看做一个字典,它是索引到数据值的一个映射
"a" in obj True
python字典直接创建series
data = {"姓名":"周琦","年龄":25,"国籍":"波兰","特点":"发球失误"}
ret = pd.Series(data)
ret
# 结果 --- 键作为索引,值作为数据值
姓名 周琦
年龄 25
国籍 波兰
特点 发球失误
dtype: object
指定索引的顺序展示字典
index = ["特点","国籍","年龄","姓名"] ret = pd.Series(data,index=index) ret 特点 发球失误 国籍 波兰 年龄 25 姓名 周琦 dtype: object
缺少数据的表示
index = ["特点","国籍","年龄","姓名","年薪"] ret = pd.Series(data,index=index) ret 特点 发球失误 国籍 波兰 年龄 25 姓名 周琦 年薪 NaN # 缺少的数据就用NaN表示 dtype: object
数据集中缺少的数据的检测
pd.isnull(ret)
特点 False
国籍 False
年龄 False
姓名 False
年薪 True
dtype: bool
pd.notnull(ret)
特点 True
国籍 True
年龄 True
姓名 True
年薪 False
dtype: bool
series的加法运算
data1 = {"西安":100,"郑州":200,"太原":300,"武汉":400}
data2 = {"西安":500,"辽宁":200,"太原":300,"南京":400}
ret1 = pd.Series(data1)
ret2 = pd.Series(data2)
ret1 + ret2
南京 NaN
太原 600.0
武汉 NaN
西安 600.0
辽宁 NaN
郑州 NaN
dtype: float64
给series对象和索引命名
ret1.name = "全国城市活力打分值" ret1.index.name = "城市名称" ret1 城市名称 西安 100 郑州 200 太原 300 武汉 400 Name: 全国城市活力打分值, dtype: int64
修改索引值
ret1.index = ['杭州', '上海', '合肥', '福州'] 通过赋值的方式修改索引值 ret1 杭州 100 上海 200 合肥 300 福州 400 Name: 分值, dtype: int64
DataFrame
DataFrame是一个表格类型的数据结构,含有一组有序的列,每列可以是不同的值类型(数值,字符串,布尔值等)
DataFrame既有行索引也有列索引,数据是一个或多个二维块存放的(而不是列表,字典,或者其他的一维数据结构)---具体细节后面会讨论
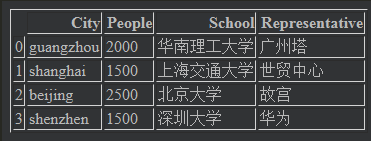
data = {"City":["guangzhou","shanghai","beijing","shenzhen"],
"People":[2000,1500,2500,1500],
"School":["华南理工大学","上海交通大学","北京大学","深圳大学"],
"Representative":["广州塔","世贸中心","故宫","华为"]}
frame = pd.DataFrame(data)
frame
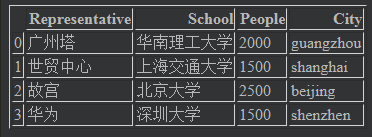
指定列序列的排序方式
data = {"City":["guangzhou","shanghai","beijing","shenzhen"],
"People":[2000,1500,2500,1500],
"School":["华南理工大学","上海交通大学","北京大学","深圳大学"],
"Representative":["广州塔","世贸中心","故宫","华为"]}
frame = pd.DataFrame(data,columns=["Representative","School","People","City"]) # 指定次序
frame
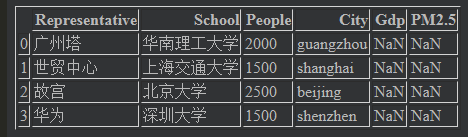
没有数据就会显示缺失值
data = {"City":["guangzhou","shanghai","beijing","shenzhen"],
"People":[2000,1500,2500,1500],
"School":["华南理工大学","上海交通大学","北京大学","深圳大学"],
"Representative":["广州塔","世贸中心","故宫","华为"]}
frame = pd.DataFrame(data,columns=["Representative","School","People","City","Gdp","PM2.5"]) # "Gdp","PM2.5" 这两个是不存在的
frame
通过获取属性,可以获得一个series的列
frame["City"] 0 guangzhou 1 shanghai 2 beijing 3 shenzhen Name: City, dtype: object

获取行:通过索引获取
frame.loc[0] # Representative 广州塔 School 华南理工大学 People 2000 City guangzhou Gdp NaN PM2.5 NaN Name: 0, dtype: object
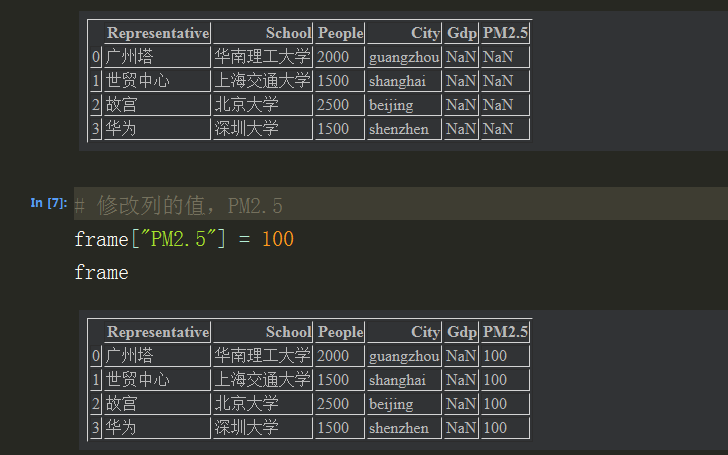
列值的修改:标量值,例如要给空列PM2.5赋值:100
fram["PM2.5"] = 100
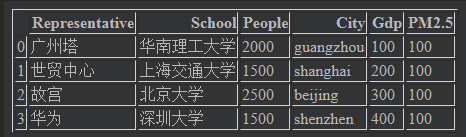
列值的修改:一组值
frame["Gdp"] = [100,200,300,400] frame
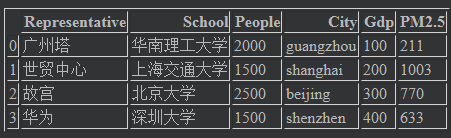
列值的修改:最精确版本,通过series索引的方式进行赋值
val = pd.Series([211,633,770,1003],index=[0,3,2,1]) frame["PM2.5"] = val frame # 结果
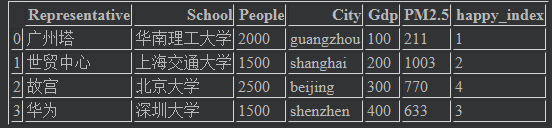
列值的修改:不存在的列将会多一个新列
val = pd.Series([1,3,4,2],index=[0,3,2,1]) # 不存在的列 frame["happy_index"] = val frame # 结果
列的添加
# 添加一个新列,用bool值表示 frame["test"] = frame["PM2.5"] > 60 frame #结果

删除列:删除上面新增的列test
del frame["test"] frame #结果
复制列:字典嵌套
pop = {"guangzhou":{0,2000}}
frame2 = pd.DataFrame(pop)
frame2
# 结果
 frame
# 结果
frame
# 结果
交换行和列:转置
frame.T # 结果

指明索引的复制 # TODO
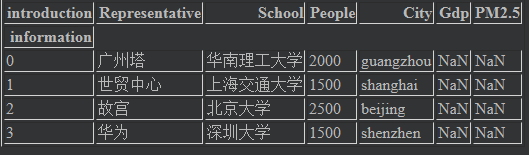
index的name属性,和columns的name属性
frame.index.name = "information" frame.columns.name = "introduction" frame # 结果
DataFrame的valus值获取:返回数组
frame.values # 结果 array([['广州塔', '华南理工大学', 2000, 'guangzhou', nan, nan], ['世贸中心', '上海交通大学', 1500, 'shanghai', nan, nan], ['故宫', '北京大学', 2500, 'beijing', nan, nan], ['华为', '深圳大学', 1500, 'shenzhen', nan, nan]], dtype=object)
pandas中的index可以存在重复值
lable = pd.Index([0,0,1,1]) lable # Int64Index([0, 0, 1, 1], dtype='int64') data = pd.Series(["a","b","c","d"],index=lable) data # 0 a 0 b 1 c 1 d dtype: object data[0] 0 a 0 b dtype: object data[1] 1 c 1 d dtype: object

基本功能使用
一:重新索引
pandas的一个重要的方法就是重新索引,reindex,作用是创建一个新的对象,它的数据符合新的索引
data = pd.Series([1,2,3,4],index=["a","d","c","b"]) data # 结果 a 1 d 2 c 3 b 4 dtype: int64
用该Series的重新索引,就会对根据新索引进行排序,如果某个索引值不在,就引入缺省值
data1 = data.reindex(["a","b","c","d","e","f"]) data1 # 结果 a 1.0 b 4.0 c 3.0 d 2.0 e NaN f NaN dtype: float64
对于时间序列这样的有顺序排序,重新索引可能需要做一些插值处理
data = pd.Series(["a","d","c","b"],index=[0,2,4,6]) data # 结果---索引值不连续,不符合要求,怎么修改呢? 0 a 2 d 4 c 6 b dtype: object data1 = data.reindex(range(8),method="ffill") data1 # 结果变成连续索引 0 a 1 a 2 d 3 d 4 c 5 c 6 b 7 b
借助,DataFrame,reindex可以修改(行)索引和列,传递一个序列时,会重新索引结果的行
frame = pd.DataFrame(np.arange(9).reshape((3,3)),index=["a","b","c"],columns=["Ohio","Texas","California"]) frame # 结果

frame1 = frame.reindex(["a","b","c","d","e"]) # reindex重新索引了,并增加了缺省值,而且数组形状也会自动进行调整。
frame1
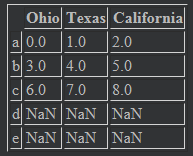
# 行索引列可以用columns的关键字进行索引
states = ["Ohio","Texas","California","NewYork","Washington"] frame1.reindex(columns = states) # 结果
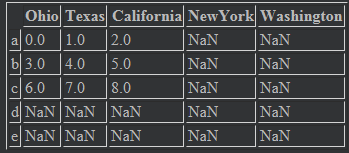

对于Series:删除指定索引的值:drop,返回删除后的结果
data = pd.Series(np.arange(5),index=["a","b","c","d","e"]) data # 结果 a 0 b 1 c 2 d 3 e 4 dtype: int32 new_data = data.drop("c") new_data # 结果 a 0 b 1 d 3 e 4 dtype: int32
new_data = data.drop(["a","c"])
new_data
# 结果
b 1
d 3
e 4
dtype: int32
对于DataFrame删除指定的索引:
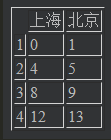
data = pd.DataFrame(np.arange(16).reshape((4,4)),index=[1,2,3,4],columns=["上海","北京","广州","深圳"]) data # 结果new_data = data.drop([4]) # 直接删行 new_data # 结果
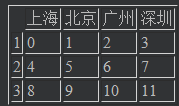
result_data = data.drop("广州",axis="columns") # 直接删列
result_data
# 结果
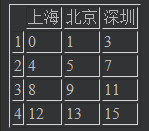
就地删除,不用新的对象进行接收的方法 inplace = True
data.drop(["广州","深圳"],axis="columns",inplace=True) data # 结果
# 谨慎使用,它会消除被删的数据
索引、选取、过滤
data = pd.Series(np.arange(4.),index=["a","b","c","d"]) data # a 0.0 b 1.0 c 2.0 d 3.0 dtype: float64 data["d"] # 按照索引取值 3.0 data[2:4] # 按照值区间进行索引 c 2.0 d 3.0 dtype: float64 data[["a","c","d"]] # 取多个索引的值 a 0.0 c 2.0 d 3.0 dtype: float64 data[data<3] # 按照条件查询 a 0.0 b 1.0 c 2.0 dtype: float64 data["a":"d"] # 索引切片是包含最后一个值的 a 0.0 b 1.0 c 2.0 d 3.0 dtype: float64
切片赋值
data["a":"d"] = 100 data # a 100.0 b 100.0 c 100.0 d 100.0 dtype: float64
DataFrame的索引和切片
data = pd.DataFrame(np.arange(16).reshape((4,4)),index=["shanghai","shenzhen","beijing","chongqing"],columns=["one","two","three","four"]) data #data["two"] # 一般的值索引就是获取列 # shanghai 1 shenzhen 5 beijing 9 chongqing 13 Name: two, dtype: int32 data[["three","one"]] #
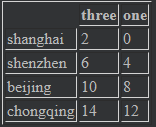
data[:2] # 切片一般都是对行进行切片 #data[data["three"] > 5] #

通过bool型进行索引
data < 10 #结果

data[data<10] = 100 data # 结果

DataFrame的标签运算符,loc和iloc
data = pd.DataFrame(np.arange(16).reshape((4,4)),index=["shanghai","shenzhen","beijing","chongqing"],columns=["one","two","three","four"]) data #
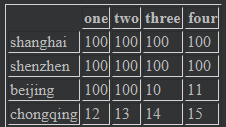
data.loc["shanghai",["two","four"]] #loc["哪一行",["第几列","第几列"] # two 100 four 100 Name: shanghai, dtype: int32 data.loc["two",["shenzhen","chongqing"]] # 报错 KeyError: 'two' # 这里应该是行的标签,不能是列的标签
data.iloc[2,[1,2,3]] # iloc用行的索引值进行选,再用列的索引值进行选 # two 9 three 10 four 11 Name: beijing, dtype: int32
loc和iloc两个函数也适合一个标签或多个标签的索引切片
data.loc[:"beijing",["one","two"]] # 结果
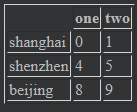
data = pd.DataFrame(np.arange(16).reshape((4,4)),index=["shanghai","shenzhen","beijing","chongqing"],columns=["one","two","three","four"]) data #
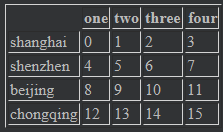
data.iloc[1:3,0:3][data.one > 0] # 1:3 --行索引的切片,0:3列索引的切片,data.one > 0 对值的范围进行限制 # 结果
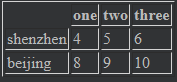
整数索引:比较难
data = pd.Series(np.arange(3.)) data # 0 0.0 1 1.0 2 2.0 dtype: float64 data[-1] # 用整数索引带来的不变,非整数索引可以很高的取代这个问题 # 错误:KeyError: -1 data = pd.Series(np.arange(3.),index=["a","b","c"]) data # a 0.0 b 1.0 c 2.0 dtype: float64 data[-1] # 2.0
如果轴索引使用了整数,数据选取总会使用标签,为了准确,请使用loc或者iloc进行取值
# 对于上面的data[-1]报键错误的情况,可以使用iloc进行准确定位 data.iloc[-1] # 2.0
算数运算
data1 = pd.Series(np.arange(3),index=["a","b","c"]) data2 = pd.Series(np.arange(5),index=["a","b","c","d","e"]) data1 # a 0 b 1 c 2 dtype: int32 data2 # a 0 b 1 c 2 d 3 e 4 dtype: int32 data1 + data2 # a 0.0 b 2.0 c 4.0 d NaN # data1没有这个索引--缺失值代替 e NaN # data1没有这个索引 dtype: float64
对齐操作:dataframe
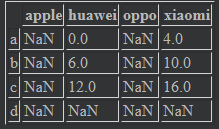
data1 = pd.DataFrame(np.arange(9).reshape((3,3)),index=["a","b","c"],columns=["huawei","oppo","xiaomi"]) data2 = pd.DataFrame(np.arange(12).reshape((4,3)),index=["a","b","c","d"],columns=["huawei","apple","xiaomi"]) data1 #data2 #
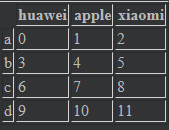
data1 + data2 #
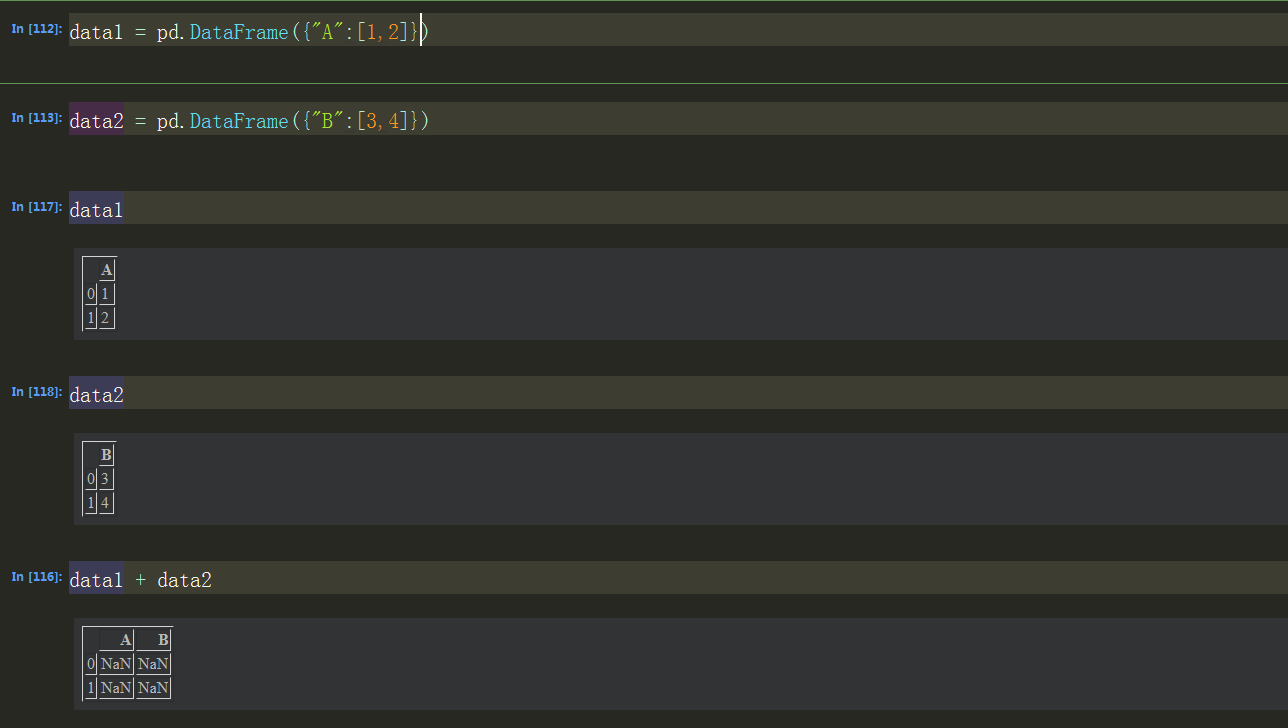
算数方法中填充值
如果:给data1中添加一列B,data2中添加一列A,不就可以解决互相相加不全部为NaN的情况了吗?
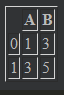
B = pd.Series(np.arange(2)) data1.insert(1,"B",B) #insert(添加的列的索引值,添加的列的名称,添加列的数据) #

A = pd.Series(np.arange(2)) data2.insert(1,"A",A) #data1 + data2 #
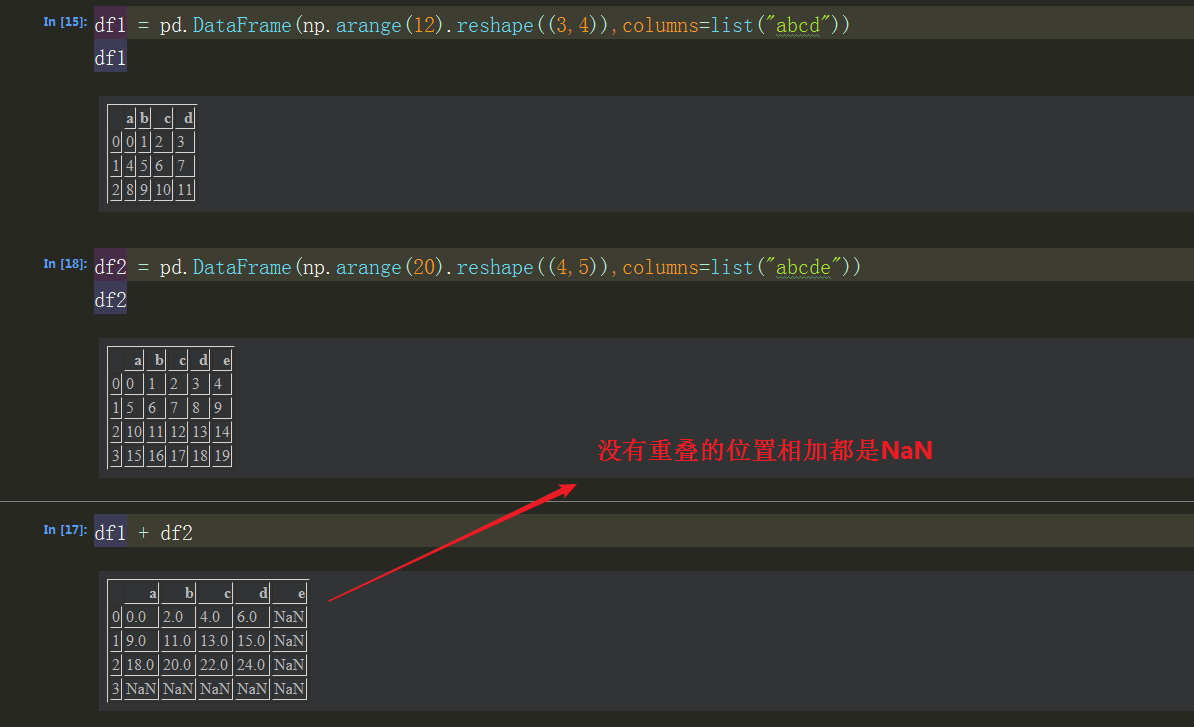
填充值:fill_value = 0
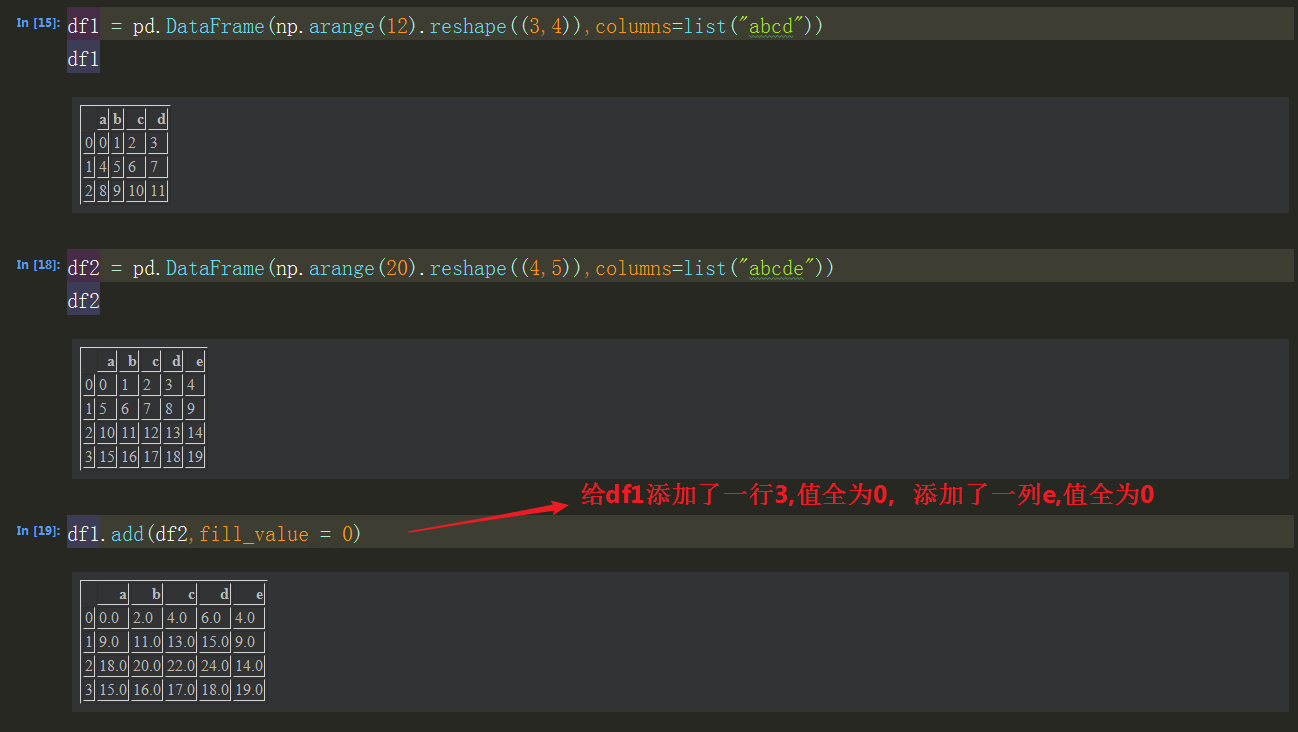
DataFrame和Seriea之间的运算
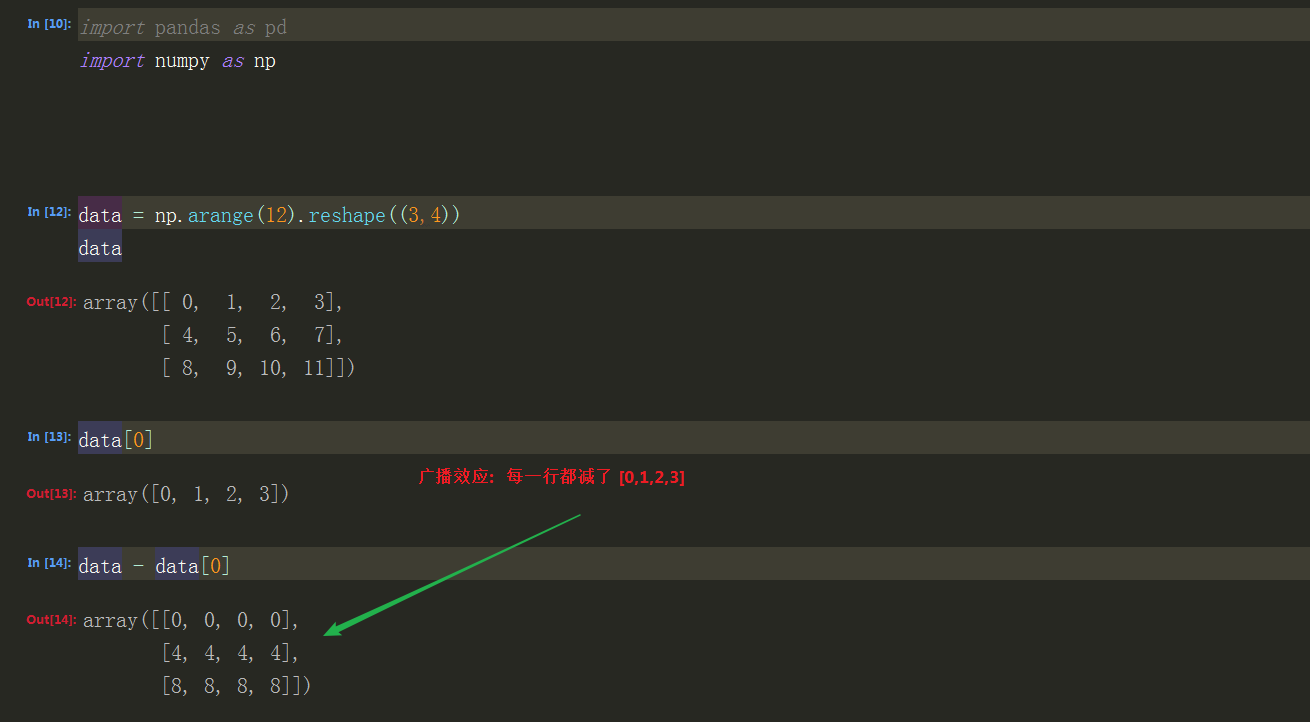
1:numpy的广播效应
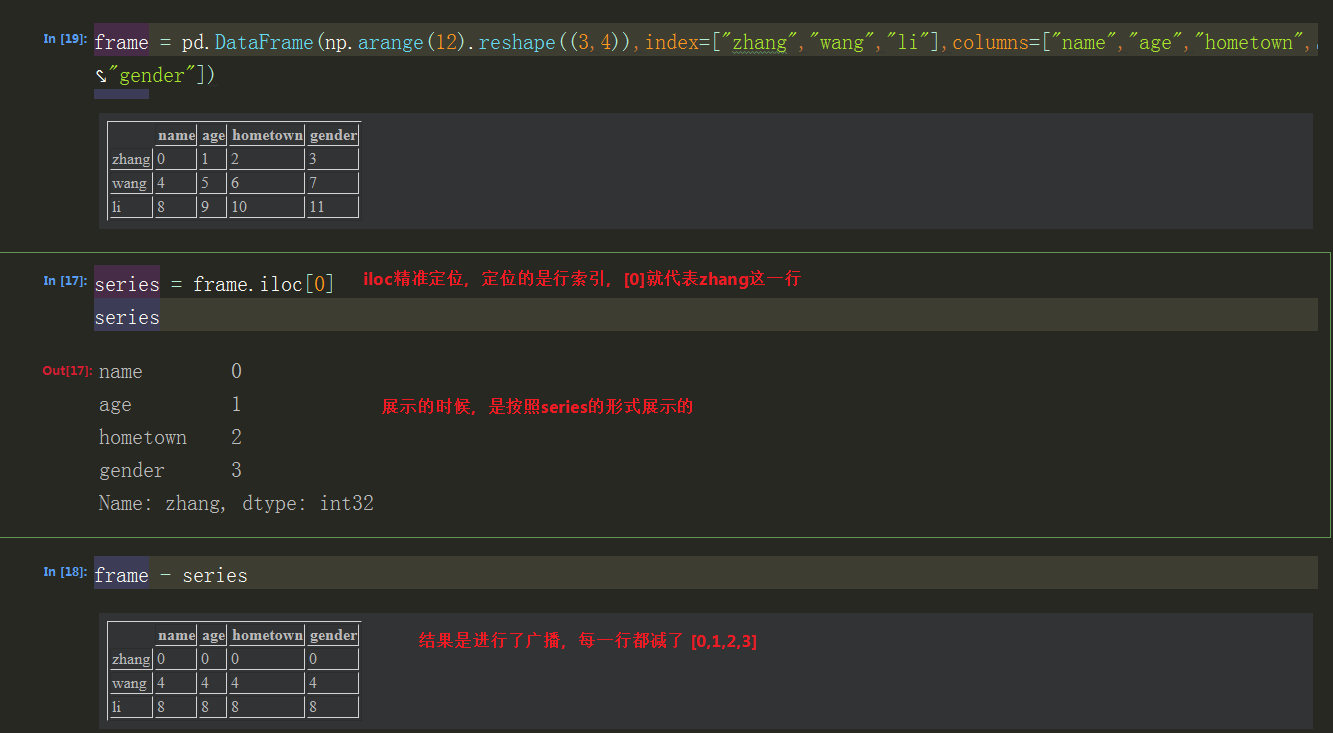
2.dataframe - series的广播效应
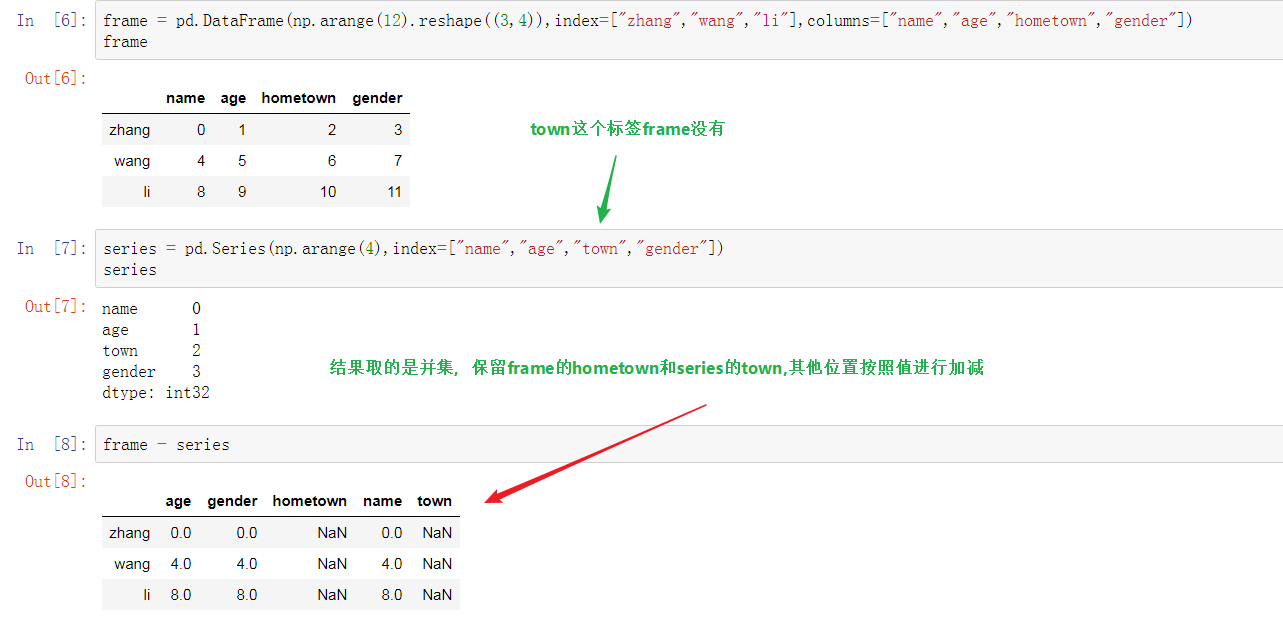
3.没有的行货列,进行算数运算是会使用NaN
4,想让列和列进行加减,必须使用函数进行,还要指明轴
frame = pd.DataFrame(np.arange(12).reshape((3,4)),index=["zhang","wang","li"],columns=["name","age","hometown","gender"]) frameseries = frame["name"] series
zhang 0 wang 4 li 8 Name: name, dtype: int32 frame - series
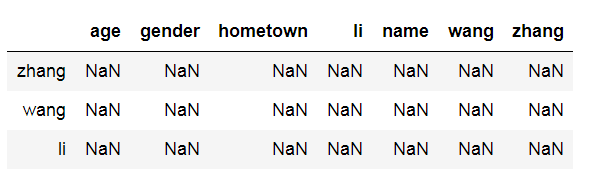
frame.sub(series,axis="index") # 列和列相减的标准写法,axis="index", 当axis="columns" 全部都为NaN