zoukankan
html css js c++ java
十七 Python分布式爬虫打造搜索引擎Scrapy精讲—深度优先与广度优先原理
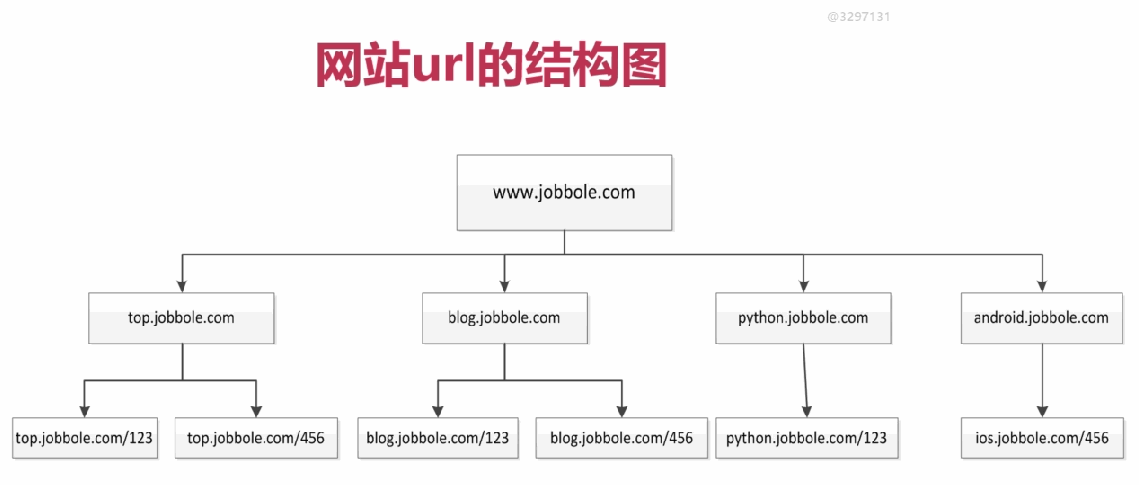
网站树形结构
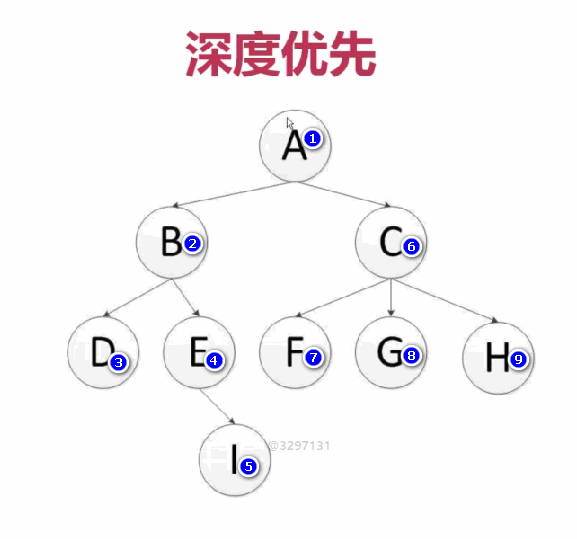
深度优先
是从左到右深度进行爬取的,以深度为准则从左到右的执行(递归方式实现)
Scrapy默认是深度优先的
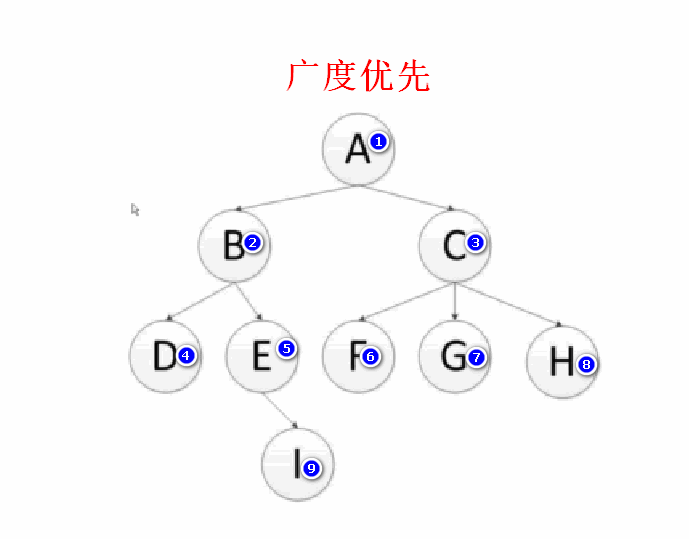
广度优先
是以层级来执行的,(列队方式实现)
查看全文
相关阅读:
QAU 18校赛 J题 天平(01背包 判断能否装满)
滚动数组
Leapin' Lizards HDU
Sabotage UVA
Food HDU
两个Button 加通一个手势,那么 第一个的就失效了,
终于把聊天记录保存到数据库当中去了,
添加好友,
XEP 0055 (Jabber search) with iphone SDK
手机ip,
原文地址:https://www.cnblogs.com/meng-wei-zhi/p/8182659.html
最新文章
2-string相关函数
30-01背包的最优解
29-整数转为小数(**高精度)
10-1015.德才论
28-同色三角形
RPC与其实现方式概念笔记
spring-data-redis使用jdk序列化时increment的异常
spring-data-redis序列化实践笔记
get与post区别
SpringMVC与Struts2区别与比较总结
热门文章
TCP协议与UDP协议的区别(yet)
spring boot 及 redis 实现分布式session 实践笔记
ajax 跨域 session 及 spring boot分布式session
spring boot redis 接入笔记
两个变量交换值
Minimum Cost POJ
Minimum Cost POJ
A Plug for UNIX POJ
Dining POJ
QAU 17校赛 J题 剪丝带(完全背包变形)
Copyright © 2011-2022 走看看