N-gram统计语言模型
1.统计语言模型
自然语言从它产生開始,逐渐演变成一种上下文相关的信息表达和传递的方式。因此让计算机处理自然语言。一个主要的问题就是为自然语言这样的上下文相关特性建立数学模型。这个数学模型就是自然语言处理中常说的
统计语言模型,它是今天全部自然语言处理的基础,而且广泛应用与机器翻译、语音识别、印刷体和手写体识别、拼写纠错、汉字输入和文献查询。
2.N-Gram
N-Gram是大词汇连续语音识别中经常使用的一种语言模型。对中文而言,我们称之为汉语语言模型(CLM,
Chinese Language Model)。汉语语言模型利用上下文中相邻词间的搭配信息,在须要把连续无空格的拼音、笔划,或代表字母或笔划的数字,转换成汉字串(即句子)时。能够计算出具有最大概率的句子,从而实现到汉字的自己主动转换。无需用户手动选择。避开了很多汉字相应一个同样的拼音(或笔划串,或数字串)的重码问题。 搜狗拼音和微软拼音的主要思想就是N-gram模型的,只是在里面多增加了一些语言学规则而已。
3.用数学的方法描写叙述语言规律
第一个句子出现的概率最大,因此。第一个句子最有可能句子结构合理。这种方法更普通而严格的描写叙述是: 假定S表示某一个有意义的句子,由一连串特定顺序排列的词w1,w2,w3,...,wn组成。这里n是句子的长度。如今,我想知道S在文本中(语料库)出现的可能性,也就是数学上所说的S的概率P(S)。我们须要一个模型来估算概率。既然S=w1,w2,w3,...,wn。那么最好还是把P(S)展开表示: P(S)=P(w1,w2,w3,...,wn)



那么对于当中的非常多词对的组合,在语料库中都没有出现,依据最大似然估
计得到的概率将会是0。这会造成非常大的麻烦,在算句子的概率时一旦当中的某项为0。那么整个句子的概率就会为0,最后的结果是,我们的模型仅仅能算可怜兮兮的几个句子,而大部分的句子算得的概率是0. 因此,我们要进行数据平滑(data Smoothing),数据平滑的目的有两个:一个是使全部的N-gram概率之和为1,使全部的N-gram概率都不为0,有关数据平滑处理的方法能够參考《数学之美》第33页的内容。4.马尔科夫如果
为了解决參数空间过大的问题。引入了马尔科夫如果:随意一个词的出现的概率只与它前面出现的有限的一个或者几个词有关。
如果一个词的出现的概率仅于它前面出现的一个词有关。那么我们就称之为bigram model(二元模型)。
即
P(S) = P(W1,W2,W3,…,Wn)=P(W1)P(W2|W1)P(W3|W1,W2)…P(Wn|W1W2…Wn-1)
≈P(W1)P(W2|W1)P(W3|W2)…P(Wi)|P(Wi-1)...P(Wn|Wn-1)
假设一个词的出现仅依赖于它前面出现的两个词,那么我们就称之为trigram(三元模型)。
在实践中用的最多的就是bigram和trigram了,并且效果非常不错。
高于四元的用的非常少,由于训练它(求出參数)须要更庞大的语料。并且数据稀疏严重,时间复杂度高,精度却提高的不多。当然,也能够如果一个词的出现由前面N-1个词决定,相应的模型略微复杂些,被称为N元模型。
5.怎样预计条件概率问题
6.在一个语料库样例
在训练语料库中统计序列C(W1 W2…Wn) 出现的次数和C(W1 W2…Wn-1)出现的次数。
以下我们用bigram举个样例。如果语料库总词数为13,748
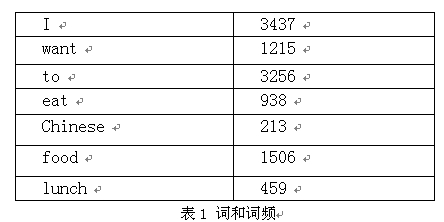
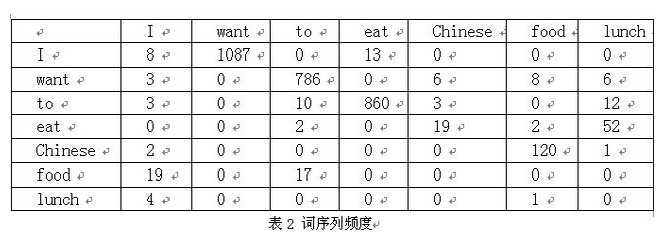
P(I want to eat Chinese food)
=P(I)*P(want|I)*P(to|want)*P(eat|to)*P(Chinese|eat)*P(food|Chinese)
=0.25*1087/3437*786/1215*860/3256*19/938*120/213
=0.000154171
对与 I to Chinese want food eat 的概率远低于I want to eat Chinese food,所以后者句子结构更合理。
注:P(wang|I)=C(I want)|C(I)=1087/3437
网上非常多资料中,表1 词与词频和表2 词序列频度是没有的,所以造成文章表意不清。
对于 1).高阶语言模型 2).模型的训练、零概率问题和平滑方法 3).语料库的选取等问题,《数学之美》中都有具体解说,在此不再概述。
版权声明:本文博主原创文章,博客,未经同意不得转载。