一、time模块
1.在Python中,通常有这几种方式来表示时间:1)时间戳 2)格式化的时间字符串 3)元组(struct_time)共九个元素。由于Python的time模块实现主要调用C库,所以各个平台可能有所不同。
2.UTC(Coordinated Universal Time,世界协调时)亦即格林威治天文时间,世界标准时间。在中国为UTC+8。DST(Daylight Saving Time)即夏令时。
3.时间戳(timestamp)的方式:通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。返回时间戳方式的函数主要有time(),clock()等。
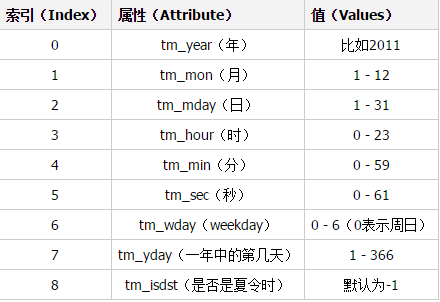
4.元组(struct_time)方式:struct_time元组共有9个元素,返回struct_time的函数主要有gmtime(),localtime(),strptime()。下面列出这种方式元组中的几个元素:
>>> import time
#时间戳 >>> print(time.time()) 1496901701.6700494
#结构化的时间 >>> print(time.localtime()) time.struct_time(tm_year=2017, tm_mon=6, tm_mday=8, tm_hour=14, tm_min=1, tm_sec =59, tm_wday=3, tm_yday=159, tm_isdst=0) >>> print(time.localtime().tm_year) 2017 >>> print(time.gmtime()) time.struct_time(tm_year=2017, tm_mon=6, tm_mday=8, tm_hour=6, tm_min=2, tm_sec= 23, tm_wday=3, tm_yday=159, tm_isdst=0)
#格式化的字符串 >>> print(time.strftime('%Y-%m-%d %H:%M:%S')) 2017-06-08 14:02:38 >>> print(time.strftime('%Y-%m-%d %X')) 2017-06-08 14:02:50 >>> print(time.localtime(13211123)) time.struct_time(tm_year=1970, tm_mon=6, tm_mday=3, tm_hour=5, tm_min=45, tm_sec =23, tm_wday=2, tm_yday=154, tm_isdst=0) >>> print(time.localtime(time.time())) time.struct_time(tm_year=2017, tm_mon=6, tm_mday=8, tm_hour=14, tm_min=3, tm_sec =20, tm_wday=3, tm_yday=159, tm_isdst=0) >>> print(time.mktime(time.localtime())) 1496901809.0 >>> print(time.strftime('%Y %X',time.localtime())) 2017 14:03:40 >>> print(time.strptime('2017-06-04 11:59:59','%Y-%m-%d %X')) time.struct_time(tm_year=2017, tm_mon=6, tm_mday=4, tm_hour=11, tm_min=59, tm_se c=59, tm_wday=6, tm_yday=155, tm_isdst=-1) >>> print(time.ctime(123123132)) Mon Nov 26 08:52:12 1973 >>> print(time.asctime(time.localtime())) Thu Jun 8 14:04:28 2017 >>>
二、random模块
#随机选取一个,用于爬虫更换IP地址 >>> import random >>> proxy_ip=[ ... '1.1.1.1', ... '1.1.1.2', ... '1.1.1.3', ... '1.1.1.4', ... ] >>> >>> print(random.choice(proxy_ip)) 1.1.1.1 >>> print(random.choice(proxy_ip)) 1.1.1.2 >>> print(random.choice(proxy_ip)) 1.1.1.3 >>> print(random.choice(proxy_ip)) 1.1.1.3
#生产验证码 >>> def v_code(n=5): ... res='' ... for i in range(n): ... num=random.randint(0,9) ... s=chr(random.randint(65,90)) ... add=random.choice([num,s]) ... res+=str(add) ... return res ... >>> print(v_code(6)) CLI56J >>> print(v_code(6)) AN6P59 >>> print(v_code(6)) UOAEB5
os模块


1 os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 2 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd 3 os.curdir 返回当前目录: ('.') 4 os.pardir 获取当前目录的父目录字符串名:('..') 5 os.makedirs('dirname1/dirname2') 可生成多层递归目录 6 os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 7 os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname 8 os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname 9 os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 10 os.remove() 删除一个文件 11 os.rename("oldname","newname") 重命名文件/目录 12 os.stat('path/filename') 获取文件/目录信息 13 os.sep 输出操作系统特定的路径分隔符,win下为"\",Linux下为"/" 14 os.linesep 输出当前平台使用的行终止符,win下为" ",Linux下为" " 15 os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为: 16 os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix' 17 os.system("bash command") 运行shell命令,直接显示 18 os.environ 获取系统环境变量 19 os.path.abspath(path) 返回path规范化的绝对路径 20 os.path.split(path) 将path分割成目录和文件名二元组返回 21 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 22 os.path.basename(path) 返回path最后的文件名。如何path以/或结尾,那么就会返回空值。即os.path.split(path)的第二个元素 23 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False 24 os.path.isabs(path) 如果path是绝对路径,返回True 25 os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False 26 os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False 27 os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 28 os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间 29 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间 30 os.path.getsize(path) 返回path的大小
os路径处理
#方式一:推荐使用
import os
#具体应用
import os,sys
possible_topdir = os.path.normpath(os.path.join(
os.path.abspath(__file__),
os.pardir, #上一级
os.pardir,
os.pardir
))
sys.path.insert(0,possible_topdir)
#方式二:不推荐使用
os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
sys模块
sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0) sys.version 获取Python解释程序的版本信息 sys.maxint 最大的Int值 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称
进度条在pycharm中无效,在命令行中执行
>>> import sys,time >>> >>> for i in range(50): ... sys.stdout.write('%s ' %('#'*i)) ... sys.stdout.flush() ... time.sleep(0.1) ... 1 2 3# 4## 5### 6#### 7##### 8###### 9####### 10####### 11######## 12######### 13########## 14########### 15############ 16############# 17############## 18############### 19################ 20################# 21################## 22################### 23#################### 24##################### 25###################### 26####################### 27######################## 28######################### 29########################## 30########################### 31############################ 32############################# 33############################## 34############################### 35################################ 36################################# 37################################## 38################################### 39#################################### 40##################################### 41###################################### 42####################################### 43######################################## 44######################################### 45########################################## 46########################################### 47############################################ 48############################################# 49############################################## 50###############################################
shutil模块
json&pickle
""" Python3 JSON模块的使用 参考链接:https://docs.python.org/3/library/json.html 这里只是介绍最常用的dump、dumps和load、loads """ import json # 自定义了一个简单的数据(Python中的字典类型),要想Python中的字典能够被序列化到json文件中请使用双引号!双引号!双引号! data_obj = { "北京市": { "朝阳区": ["三里屯", "望京", "国贸"], "海淀区": ["五道口", "学院路", "后厂村"], "东城区": ["东直门", "崇文门", "王府井"], }, "上海市": { "静安区": [], "黄浦区": [], "虹口区": [], } } # ---------------------------------------------------分割线------------------------------------------------------------ """ dumps:序列化一个对象 sort_keys:根据key排序 indent:以4个空格缩进,输出阅读友好型 ensure_ascii: 可以序列化非ascii码(中文等) """ s_dumps = json.dumps(data_obj, sort_keys=True, indent=4, ensure_ascii=False) print(s_dumps) # ---------------------------------------------------分割线------------------------------------------------------------ """ dump:将一个对象序列化存入文件 dump()的第一个参数是要序列化的对象,第二个参数是打开的文件句柄 注意打开文件时加上以UTF-8编码打开 * 运行此文件之后在统计目录下会有一个data.json文件,打开之后就可以看到json类型的文件应该是怎样定义的 """ with open("data.json", "w", encoding="UTF-8") as f_dump: s_dump = json.dump(data_obj, f_dump, ensure_ascii=False) print(s_dump) # ---------------------------------------------------分割线------------------------------------------------------------ """ load:从一个打开的文件句柄加载数据 注意打开文件的编码 """ with open("data.json", "r", encoding="UTF-8") as f_load: r_load = json.load(f_load) print(r_load) # ---------------------------------------------------分割线------------------------------------------------------------ """ loads: 从一个对象加载数据 """ r_loads = json.loads(s_dumps) print(r_loads) arg = '{"bakend": "www.oldboy.org", "record": {"server": "100.1.7.9", "weight": 20, "maxconn": 30}}' a = json.loads(input('请输入添加的数据:'),encoding='utf-8') print(a)
shelve模块
shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型
import shelve
f=shelve.open(r'sheve.txt')
# f['stu1_info']={'name':'egon','age':18,'hobby':['piao','smoking','drinking']}
# f['stu2_info']={'name':'gangdan','age':53}
# f['school_info']={'website':'http://www.pypy.org','city':'beijing'}
print(f['stu1_info']['hobby'])
f.close()
xml模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
xml的格式如下,就是通过<>节点来区别数据结构的:
<?xml version="1.0"?> <data> <country name="Liechtenstein"> <rank updated="yes">2</rank> <year>2008</year> <gdppc>141100</gdppc> <neighbor name="Austria" direction="E"/> <neighbor name="Switzerland" direction="W"/> </country> <country name="Singapore"> <rank updated="yes">5</rank> <year>2011</year> <gdppc>59900</gdppc> <neighbor name="Malaysia" direction="N"/> </country> <country name="Panama"> <rank updated="yes">69</rank> <year>2011</year> <gdppc>13600</gdppc> <neighbor name="Costa Rica" direction="W"/> <neighbor name="Colombia" direction="E"/> </country> </data>
configparser模块
hashlib模块
hash:一种算法 ,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
三个特点:
1.内容相同则hash运算结果相同,内容稍微改变则hash值则变
2.不可逆推
3.相同算法:无论校验多长的数据,得到的哈希值长度固定。
1 import hashlib 2 3 m=hashlib.md5()# m=hashlib.sha256() 4 5 m.update('hello'.encode('utf8')) 6 print(m.hexdigest()) #5d41402abc4b2a76b9719d911017c592 7 8 m.update('alvin'.encode('utf8')) 9 10 print(m.hexdigest()) #92a7e713c30abbb0319fa07da2a5c4af 11 12 m2=hashlib.md5() 13 m2.update('helloalvin'.encode('utf8')) 14 print(m2.hexdigest()) #92a7e713c30abbb0319fa07da2a5c4af 15 16 ''' 17 注意:把一段很长的数据update多次,与一次update这段长数据,得到的结果一样 18 但是update多次为校验大文件提供了可能。 19 '''
suprocess模块
logging模块
用于便捷记录日志且线程安全的模块 import logging ''' 一:如果不指定filename,则默认打印到终端 二:指定日志级别: 指定方式: 1:level=10 2:level=logging.ERROR 日志级别种类: CRITICAL = 50 FATAL = CRITICAL ERROR = 40 WARNING = 30 WARN = WARNING INFO = 20 DEBUG = 10 NOTSET = 0 三:指定日志级别为ERROR,则只有ERROR及其以上级别的日志会被打印 ''' logging.basicConfig(filename='access.log', format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p', level=10) logging.debug('debug') logging.info('info') logging.warning('warning') logging.error('error') logging.critical('critical') logging.log(10,'log') #如果level=40,则只有logging.critical和loggin.error的日志会被打印