今天主要讲一下深度学习泰斗Geofrey Hinton 2006年发表在Nature上的一篇论文《Reducing the Dimensionality of Data with Neural Networks》。这篇文章也是第一篇深度学习的论文,在之前的话没有很好的方法应用在深度学习网络上。这篇论文发表之后,人们的灵感纷纷涌现,进而深度学习得到了快速发展和巨大的进步。
论文地址:https://science.sciencemag.org/content/sci/313/5786/504.full.pdf
直接上干货,根据图片讲解容易理解,这里用图像压缩为例,网络训练过程如下:
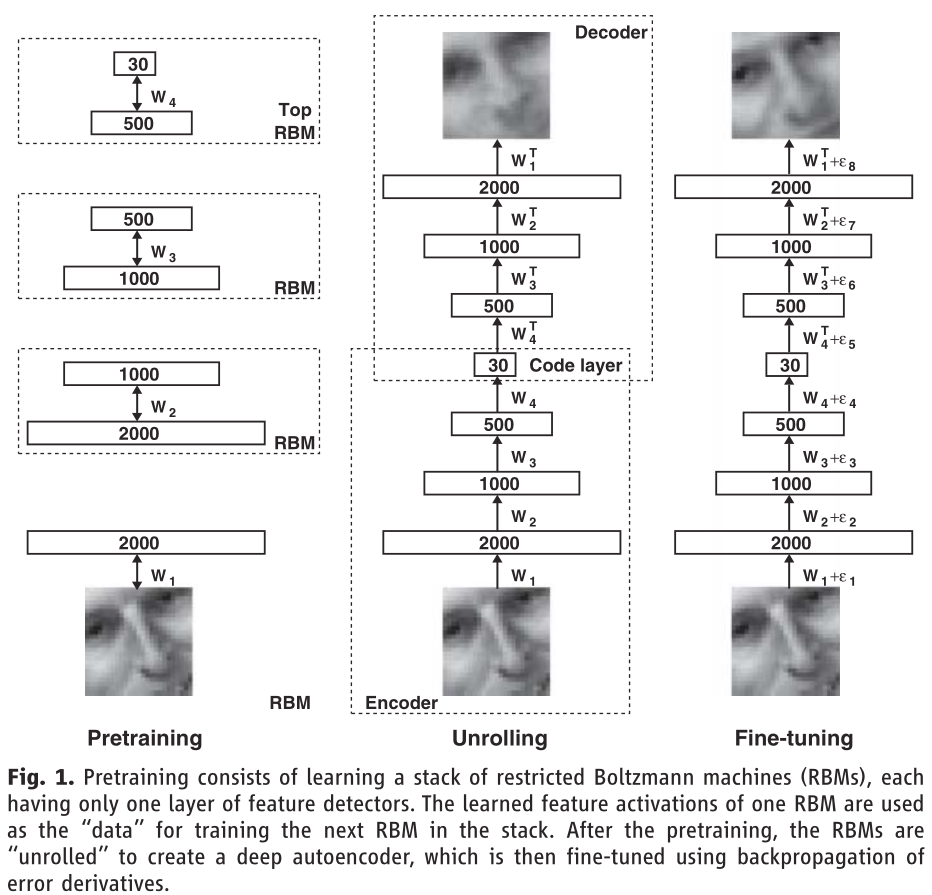
具体讲解
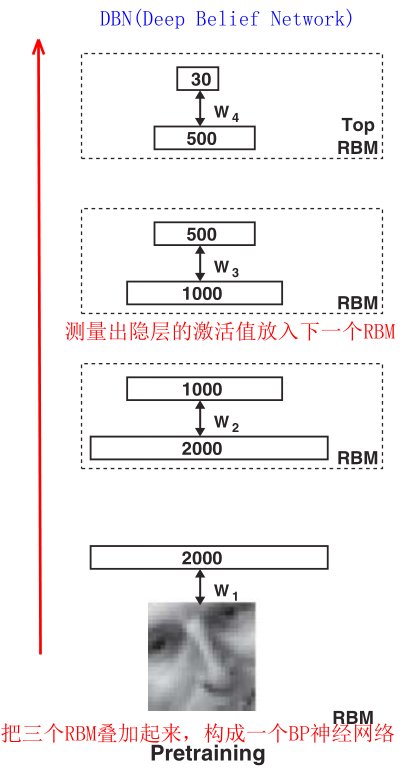
1. 首先看左边的Pretraining,这里最下面,一开始是一张2000个像素的图片,然后构建了3个受限玻尔兹曼机。
第一个RBM,可见层有2000个神经元,隐层有1000个神经元,先将2000个像素的图片输入到第一个RBM中训练,训练好之后得到隐层1000个神经元的输出,等于就是提取了1000个特征,把1000个值保存下来之后输入第二个RBM,可见层有1000个神经元,隐层有500个神经元,训练第二个RBM之后可以得到500个特征的值。最后在把500个值输入到第三个RBM中,可见层有500个神经元,隐层有30个神经元,最后得到30个特征。意思就是从2000个像素的图片不断训练,最后提取出30个图片的特征值。
这是把三个受限玻尔兹曼机堆叠起来构成一个BP网络。
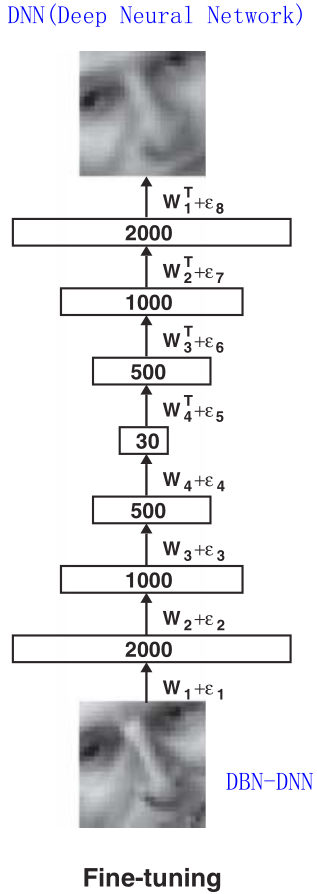
2. 然后看中间的Unrolling,它是由一个编码过程和一个解码过程组成的。首先编码过程它使用的是左边的三个堆叠的RBN,并且使用左边堆叠的RBM已经训练好的权值W1, W2, W3, W4。然后解码过程它就是将RBM反过来,并将权值求其转置。通过输入一张原图进入该网络,然后最后得到的输出有点模糊。

3. 最后看最右边的结构,它实际就是在中间的结构上做了个Fine-tuning。Fine-tuning就是微调的意思。最右边构建的BP神经网络使用的权值的初始值就是前面用的权值W1, W2, W3, W4进行训练。通过这个构建类似于中间的网络结构进行训练之后对初始值的权值进行了改变,E1, E2, ... , E7就是对这些权值进行的微调。最后显示出来的效果就比中间的那个结构效果要好。
原理是:利用左边结构堆叠起来的受限玻尔兹曼机训练,得到的网络权值作为右边整个结构的权值的初始值。再使用堆叠起来的受限玻尔兹曼机训练时得到的权值已经很接近全局最小值,从而避免了如果我们随机取值容易掉入局部最小值的情况。
总结
这篇文章的思想还是挺简单,主要是运用堆叠的受限玻尔兹曼机(RBM)进行预训练,得到网络的权值,这样堆叠起来的网络我们就称为深度置信网络DBN(Deep Belief Network)。然后我们利用预训练好的权值作为神经网络DNN(Deep Neural Network)的权值的初始值,进行训练,这个网络我们可以称为DBN-DNN。
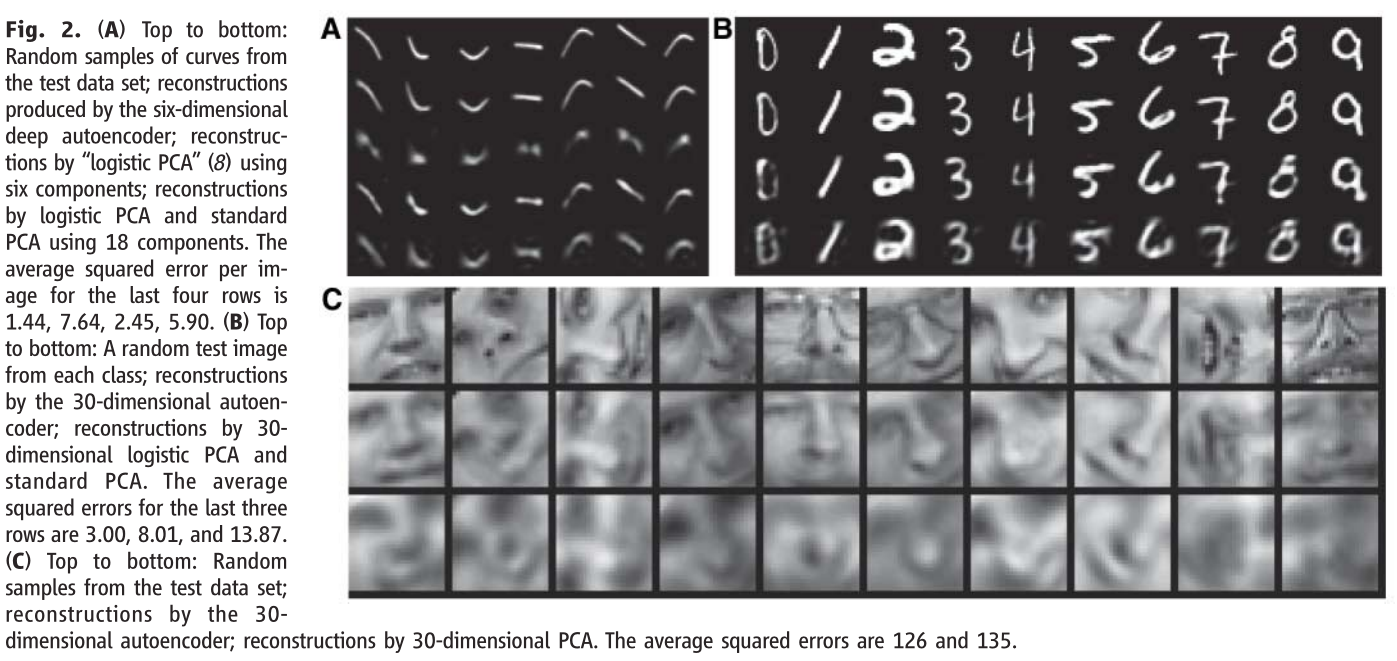
然后我们看到这篇文章做的实验:
A图中,第一行是原图;第二行是使用DBN-DNN这个网络对图片进行压缩所得到的图片;后面几行是用其它技术对原图进行压缩的结果,可以看到只有第二行使用DBN-DNN的效果最好。
B图和C图同样也是,第一行是原图;第二行是使用DBN-DNN之后的效果,后面也是使用的是其它技术。我们可以看到较与以前的方法,我们这个结合了DBN-DNN的方法效果是最好的。
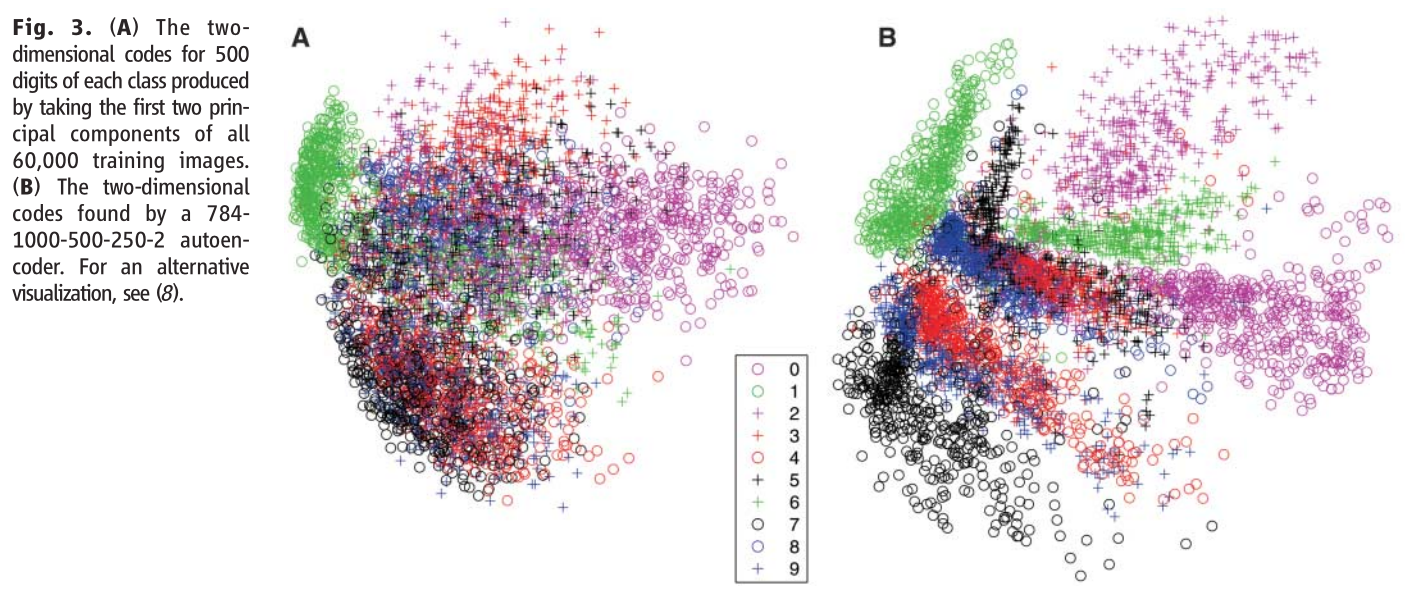
前面的实验是说的图片压缩,这里的实验是将DBN-DNN用到图片分类,也可以得到一个好的效果。可以看到,中间竖着的0到9表示10个数字。A图片是使用principal components analysis (PCA)得到的结果,我们可以看到上面的点很密集,点区分的不是很明显,效果不太好。B图就是使用DBN-DNN(DBN预训练之后再使用DNN训练)之后效果,可以看到每个种类的点区分的比较明显,分类效果好很多。
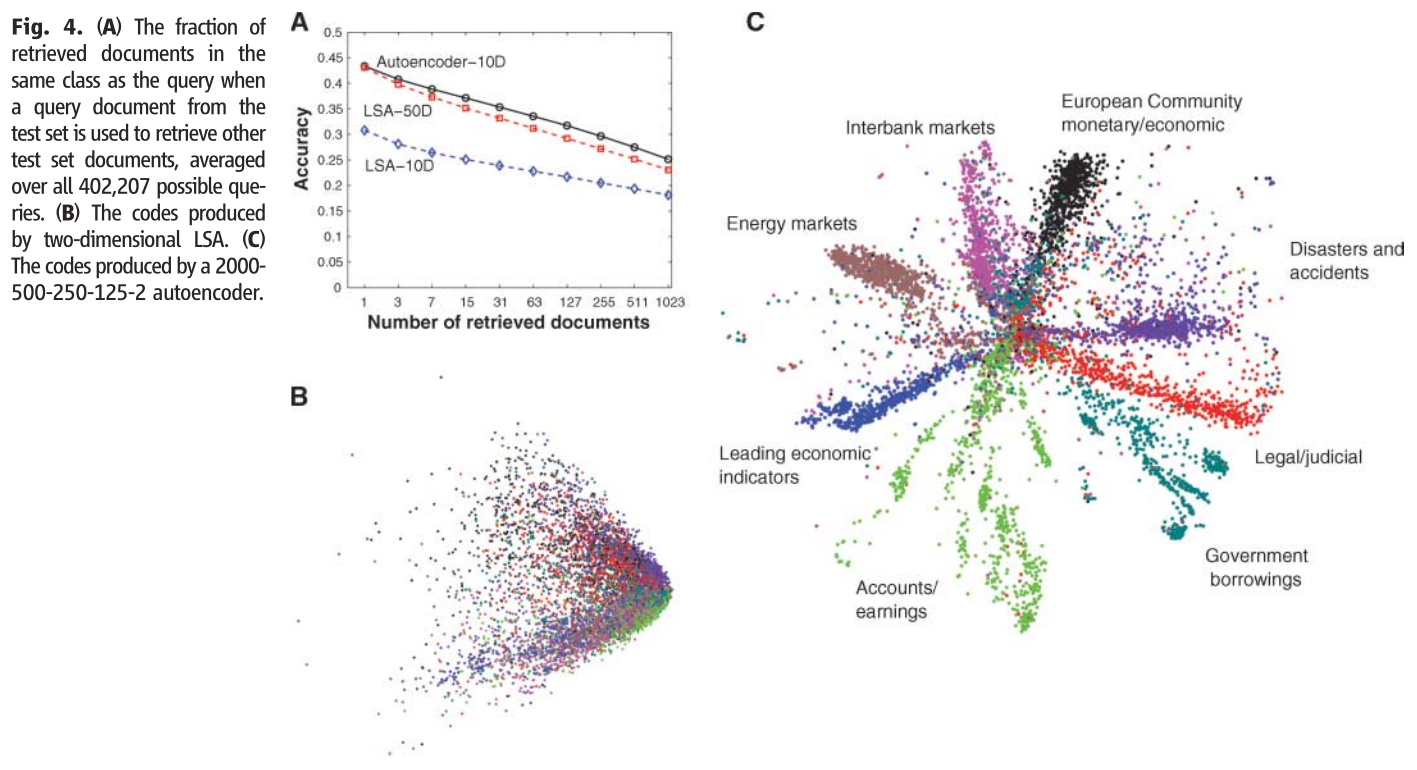
下面做的实验是关于文本分类的问题,B图使用的是传统的LSA的方法产生的效果,可以看到颜色比较混乱,分类的效果不是很好。C图使用的是DBN-DNN的方法,可以看到其颜色区分的很开,分类效果更好。
总结:我们构建一个比较深层的网络的时候,如果使用了堆叠的RBM的预训练的方法,就可以使得我们深层的神经网络得到一个更好的效果。因为深层的网络的权值的初始值就是在全局最小值的附近,我们再稍加训练,它就能掉入全局最小值,所以就有一个非常好的效果。