KNN:
就是计算特征之间的距离,某一个待预测的数据分别与已知的所有数据计算他们之间的特征距离,选出前N个距离最近的数据,这N个数据中哪一类的数据最多,就判定待测数据归属哪一类。
 假如N=3,图中待测圆就属于个数最多那个:三角类
假如N=3,图中待测圆就属于个数最多那个:三角类
总结:
1、KNN是分类数据最简单最有效的算法
2、缺点就是存储空间消耗大,计算耗时。
决策树:
信息增益:划分数据集之前之后信息发生的变化叫做信息增益。
信息公式:
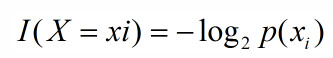
熵:信息的期望值(熵越高也就是数据混合数据越多,杂乱程度越大)
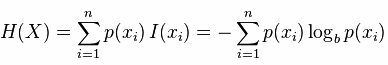
算法思想:选择最好信息增益最大的属性也就是熵最小的特征
注意:特征和特征值的区别,一个特征有几个特征值。比如:性别特征有男、女两个特征值。
算法过程:
1、先计算划分数据前的熵(主要是计算类的概率,然后求熵)
2、然后根据特征进行划分数据集,计算划分后的数据熵(根据特征的每一个特征值划分数据,可以计算每一个特征值的信息,最后可以计算特征的熵)
3、划分前的数据熵减去划分后的熵得到信息增益,选择使数据信息增益最大的那个特征,也就是最好的划分特征。
4、重复2、3(形成一棵树)最后将数据分类成功。(每一个叶子结点代表一个类)
总结:
1、速度快,容易理解,适合高纬度。
2、容易过拟合,由于训练数据中存在噪音数据,决策树的某些节点有噪音数据作为分割标准,导致决策树无法代表真实数据。