关于线性回归
- 许多真实的过程能够用线性模型来近似
- 线性回归通常作为更大系统的一个模块
- 线性系统能有解析解,不需要迭代逼近,而是直接可以求解出来
- 线性预测提供了对许多机器学习核心概念的介绍,例如定义目标函数、梯度下降等
一元线性回归
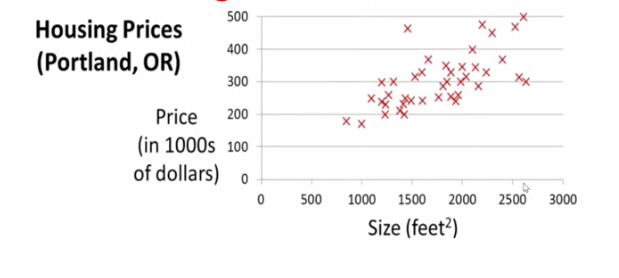
比如一个朋友要买房子,如今已知一些房价的面积和对应价格。我们希望能得到一个模型已知面积预测房价。该图中有许多样本点,每个点横轴对应面积大小、纵轴对应的是房价价格。该问题是一个监督学习的问题,输入数据(大小)、输出数据(价格),并且是一个回归问题。
对于当前情况的表示:
- 输入样本是m个
- x是输入(特征)
- y是输出(目标变量)
- (x,y)代表一对训练样本
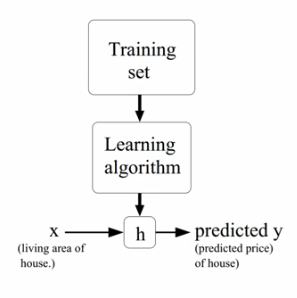
回顾一下监督学习,给定输入数据x,也给出目标的数据y,期望学习一个从输入x到输出y之间的映射。要学习从x到y的映射需要一个模型假设h,模型假设就是采用何种模型来模拟输入到输出的映射关系。之后要建立目标函数,之后使用优化算法来使得目标函数取得极小值。这个过程叫做学习的过程。对于该问题如何表示模型假设呢?我们可以用一条直线来模拟房屋大小和价格的关系。输入是x,输出是y,参数有两个斜率和截距。因为输入仅仅只有一个数值所以我们称该种回归是一元的线性回归。
基于监督学习的过程,我们要求解模型的参数。我们要定义损失函数,也就是要优化的目标函数。损失函数有一个别名叫做能量函数。原因是:
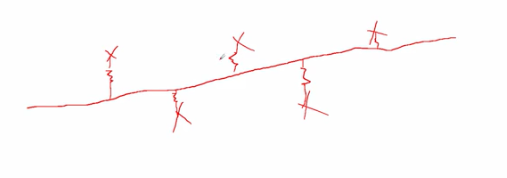
假设数据点与最终模型(直线)之间有弹簧进行连接,在期望的位置,弹簧既没有压缩也没有拉伸,所以弹性势能为0.如果不是最理想的位置,有些弹簧为压缩了,有些弹簧被拉伸了,这种情况下得到的直线是不理想的。为了得到理想的直线,我们希望弹簧既不拉伸也不压缩能量为0,所以叫能量函数。
我们训练过程中希望得到的模型预测的值与实际的值尽可能接近,我们用模型输出与期望做差,为了防止有正有负的情况,所以平方,进而得到损失函数。之所以前面除以2m,为了求导方便,该损失函数叫做均方误差。
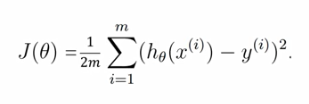
我们要基于该目标函数进行优化,找到对应模型参数,使得模型参数取某个参数的时候,整个目标函数取得最小值。
python实现均方误差
def computeErrorForLineGivenPoints(θ0, 01, points);:
totalError= 0
for i in range(0, len(points)):
totalError += (points[i].y- (θ1 * points[i].x+θ0)) ** 2
return totalError / 2*float(len(points))
有了模型假设之后,我们来看一下这个问题。
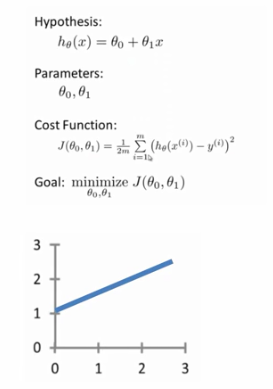
- 首先我们的模型假设是线性函数,有两个参数,斜率和截距
- 损失函数我们定义为均方误差函数
- 目标是找到两个参数,使得损失函数的值最小
- 假设函数的图像是一条直线
为了简化这个模型,我们假设截距为0,仅仅考虑斜率,来使得损失函数值最小。
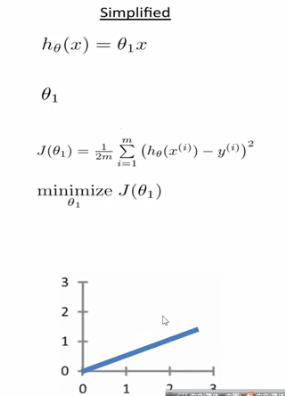
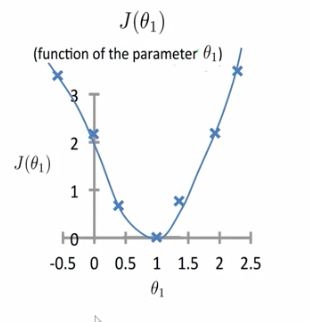
具体例子,假设实际上当斜率取得1的时候损失函数的值取得极小,但是实际上我们并不知道斜率取得什么值的时候,损失函数取得的值最小。那么我们假设斜率取得别的值的时候(不等于1时候),看它的损失函数值如何变化。

比如斜率等于0.5或者0的时候,还有斜率取其他值的时候。我们可以得到当k取不同的值的时候,损失函数的大小。进而画出损失函数大小随着k变化的曲线。我们的优化是使得误差取得极小值的时候,当k取得1的时候,损失函数最小。
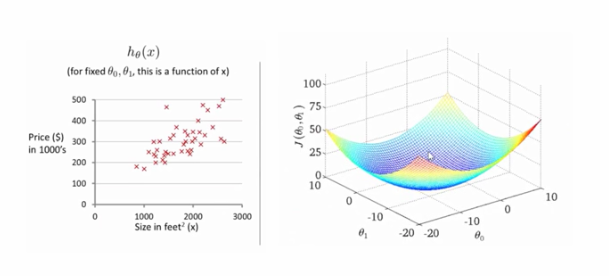
当我们考虑两个参数的时候,需要找到两个参数使得损失函数取得极小。假如将两个参数和损失函数大小关系画出来,是一个曲面,像一个碗。在碗底的时候损失函数取得值最小。如何求解这种一元线性回归我们可以采用梯度下降算法。
梯度下降算法
在定义了损失函数的情况下,我们希望找到模型的参数来使得损失函数值最小。
- 开始的时候,我们并不清楚参数设定为什么值使得损失函数取得最小值,所以要给参数一个随机值作为初始值
- 我们希望通过不断的调整参数的值来使得损失函数的值减小
- 经过多次迭代使得函数降到极小值
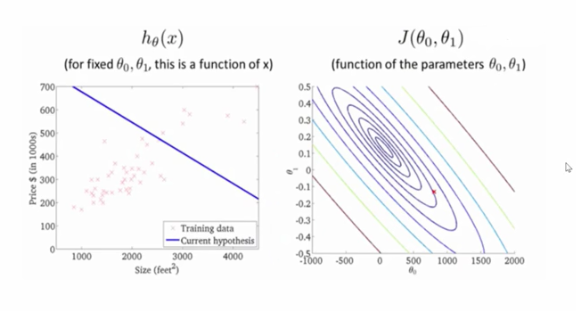
假设一开始的参数的值确定了如上的模型,我们可以明显的看到模型与数据之间是不匹配的。接着我们可以通过不断的调整模型的两个参数,使得最终直线到达最佳的合适的位置。

下图更为直观的可以看出损失函数随着两个参数变化,而得到的结果。我们初始确定一个θ0和θ1的值,通过多步骤迭代,一点一点的下降,直到最低点没法再下降了,
也就找到了我们要求解的参数。
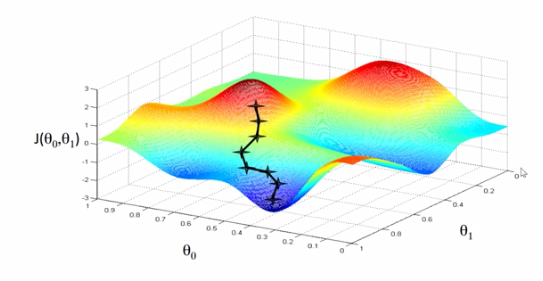
如何让每次的迭代损失函数的值都下降呢?
高等数学中,一个函数沿着负梯度的方向,下降是最快的。所以沿着负的梯度方向进行下降,到达极值点的速度是最快的。但是最终到达的极值点与初始位置的选取有着很大的关系。因为沿着当前点的梯度下降到达的最终极值点可能是局部的极值点。
梯度下降算法的表达式:
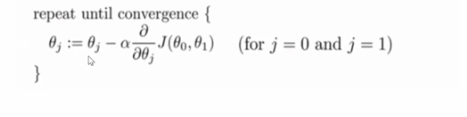
1.从一个初始的值,利用梯度方向来调整参数值,我们对每一个参数求偏导数
2.因为是负梯度所以前面有一个负号
3.α叫学习率,又或者叫做步长,如果α取得小,步子小,取得大,步子大
梯度下降算法

当前情况:已知定义损失函数的情况下,我们希望找到模型的参数θ0、θ1来使得模型损失函数取得极小值
整体过程:
1.因为一开始不清楚参数θ0、θ1取什么值使得损失函数取得最小的值,所以初始参数的选取是随机的
2.我们希望调整参数的值,每调整一次参数的值,就使得损失函数的值变小,我们其实清楚很难一次性将参数调到位,所以希望通过一次次的迭代来最终使得找到参数使得损失函数取得极小值
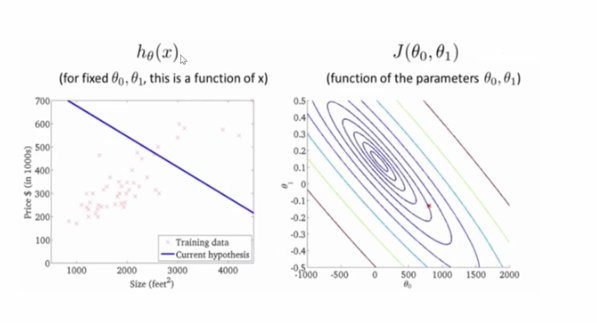
以上的图例说明了该过程,一开始参数随机选取,我们可以看出数据在直线两侧分布是不均匀的,该直线不可以拟合数据。通过不断的迭代调整参数使得损失函数的值不断减小,找到最终的我们要的参数,使得损失函数的值取得最小。

该曲面是取不同参数得到损失函数的值所构成的曲面,横轴和纵轴分别是两个参数,该曲面有个名字叫做误差曲面。该曲面像一个山坡,我们每一次下降一点,每一次下降一点,最后就会到达山底。也就是损失函数值最小的位置。如何让每次迭代都是朝山脚走(下降),而不是朝山顶走(上升)呢?高等数学中讲过沿着函数的负梯度的方向是函数下降最快的方向。所以让函数每次沿着它值下降最快的方向下降,那么就能快速到达山脚(最小值)。
注意:最终所得到的的最小值和起始的参数有很大的关系!
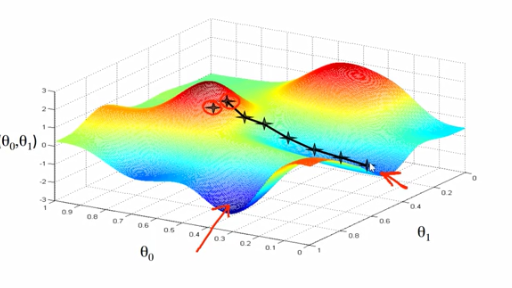
比如从该点梯度下降走,最终走到的位置是如图的轨迹终点的位置。而从另外一个起始点下降,可能得到的最终位置是另外的一个极小值点。换句话说你找到的极小值可能是局部的极小值,而非全局的极小值。
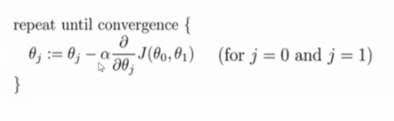
1.一个初始的值利用梯度方向来不断调整参数
2.对每一个参数求偏导数,因为是负梯度所以前面有符号
3.α是学习率,决定每次迭代步子走的大小

注意:梯度下降更新参数值的时候,两个参数要同时更新,而不是一个更新完之后另外一个更新。
直观例子

假设损失函数仅仅只有一个参数,损失函数如图所示。对于一个参数求它的梯度,当然就是它的斜率。比如左边的那个图,该点斜率是正的,θ减去一个整数,θ朝着左边移动,也就是朝着中间那个取得极小值点在移动,再或者右边那个图,该点斜率是负数,θ减去该点梯度(负数斜率)乘以一个参数α,相当于θ加上了一个整数,θ值在增大,也就是θ再向右边移动,进而不断接近中间的取得损失函数极小值的参数值。
关于学习率:
假如α取得的很小的话,每次参数变化会比较小,可能需要迭代的次数会比较多,才可以找到损失函数取得极小值的参数。比如这样:

α的值取得的比较大的话,容易扯到蛋,步长太大了,可能最后算法不收敛了,所以学习率要不能太小(收敛速度慢),也不能太大(不收敛左右摇摆不定)

一个函数在极值点的斜率是0,参数减去一个0,参数就不变了,当参数几乎不变了,我们就知道到达了所谓的极值点,收敛到了我们想要的位置。

其实即使你不怎么改变学习率,每次的步长依旧是在减小的,这是为什么呢?因为梯度下降的过程中导数的值在不断的变小,进而乘以学习率就会不断的变小,总之就是一开始梯度下降的步长会比较大,但是随着不断接近极值点,斜率不断减小,进而步子也会不断减小。

我们现在已知梯度下降算法一般表达式,和模型以及损失函数。可以进行代入计算对各个参数偏导数,进而进行梯度下降。

以上的梯度算法叫做批梯度下降算法,批就是批量的意思,迭代每一次都用到所有的样本,但是我们的样本可能很多,几百万个,直接全都读入内存可能会导致电脑内存爆炸,这时候批梯度算法会受限,所以我们平时用到的大多都是随机梯度下降算法。
最小二乘参数估计法
最小二乘参数估计法和梯度下降算法是完全不同的,因为它不需要进行逐次的迭代。
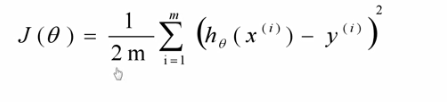
我们在梯度下降算法的过程中需要定义损失函数,中学我们就学过,想要求得一个函数的极值,需要找到该函数导数为0的点。使代价函数取得极小值的参数的解析解是在代价函数相对于参数的偏导数为0处取得。基于以上基本的思想,我们得出了用cost function分别对θg和θ1求偏导数,并令偏导数为0,进而得到两个参数θ0、θ1
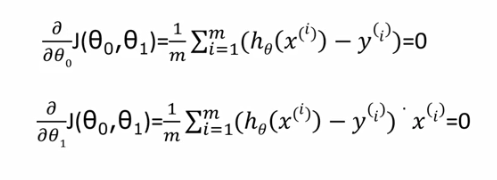
推导的过程:
1.求θ0
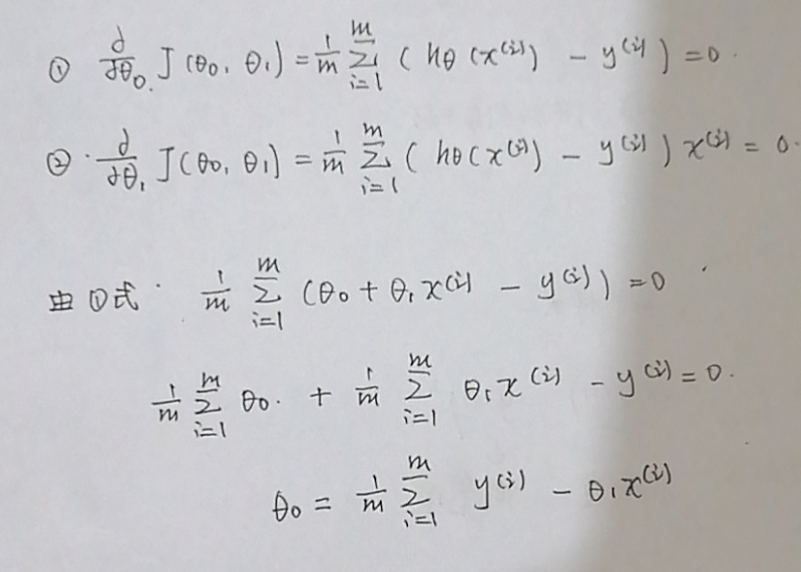
2.求θ1

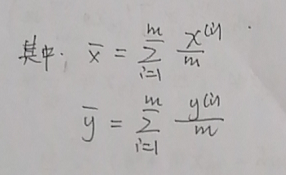
例子:
假设我们试图对某一社区中个人受教育程度x)对年平均收入(f(x)) 的影响进行研究。从该社区中随机收集了11名个体的数据,利用该数据来获得最佳线性回归模型。

计算过程仅仅需要代入我们之前推导的公式就ok了!

多元线性回归
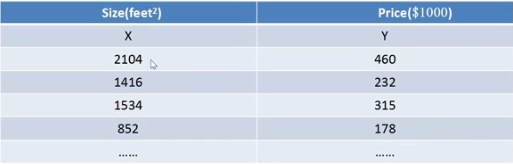
一元线性回归我们仅仅考虑一个因素比如房子的大小对价格的影响,但是实际上对于房子的影响因素是有许多的比如地域、房屋年龄、...等等,所以对于已知多个因素来预测房价,我们可以采用多元线性回归。
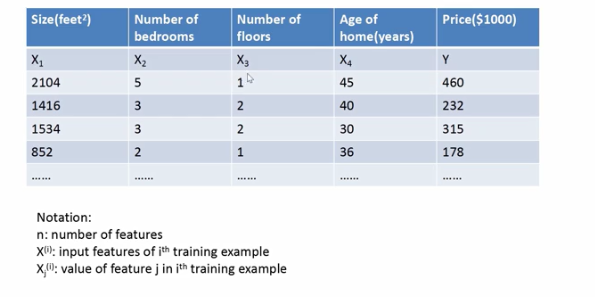
一元线性回归模型仅仅只有两个参数而多元线性回归模型有好多个参数:
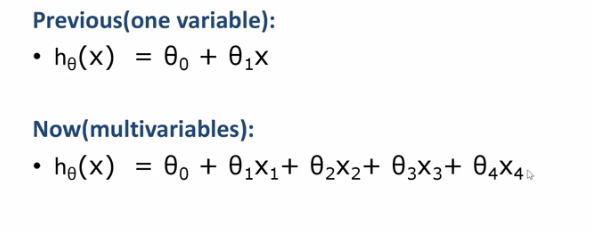
因为多元线性回归有多个参数,为了方便我们要写成矩阵的形式。

- 输入向量写成[x0,x1,x2,...,xn]^T列向量,其中xo是1,为了和θ矩阵相乘得到θ0
- 参数写成[θ0,θ1,θ2,...,θn]^T列向量
- 进而模型可以写成矩阵相乘的形式
多元线性回归梯度下降算法
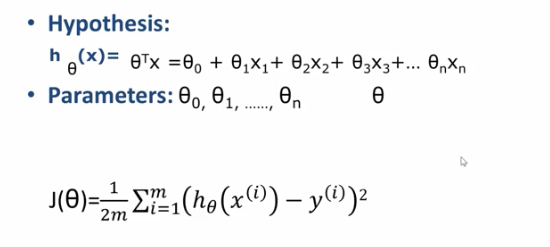
- 梯度下降算法目标函数是均方误差的损失函数
- 模型假设是多元线性回归的模型,hθ相对与一元线性回归来说多了一些参数
梯度下降的过程相对与一元来说,仅仅就是多了许多参数:

对于多元线性回归我们可以将损失函数和模型代入进去得到:

多元线性回归最小二乘法(normequation方法)
假设我们用四个特征来预测房价:
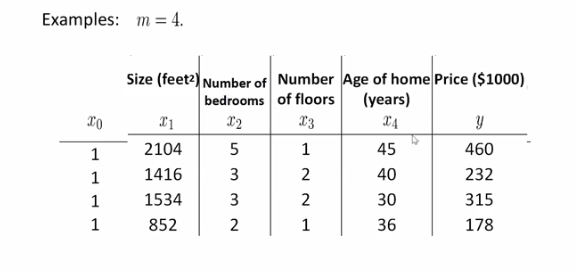
我们可以将输入表现为矩阵的形式,矩阵的行数对应样本数,矩阵的列数对应着特征数。

输出也表现为矩阵的形式:
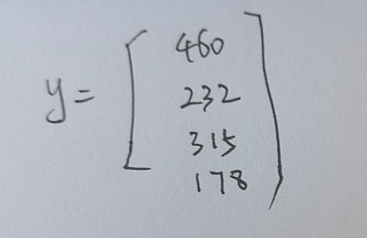
这样表示的好处在于求参数方便,存在公式来求参数:

推导:
1.损失函数表示为矩阵的形式

2.矩阵求导,对于一元的形式我们直接求导令其等于0求参数就ok,多元我们也想这么搞,但是这样太麻烦了,我们决定使用矩阵求导的方式,同时更新参数。


- 矩阵求导公式在上图的红字所示
- 对已经化为矩阵形式的损失函数求导并令其为0
- 求解参数θ
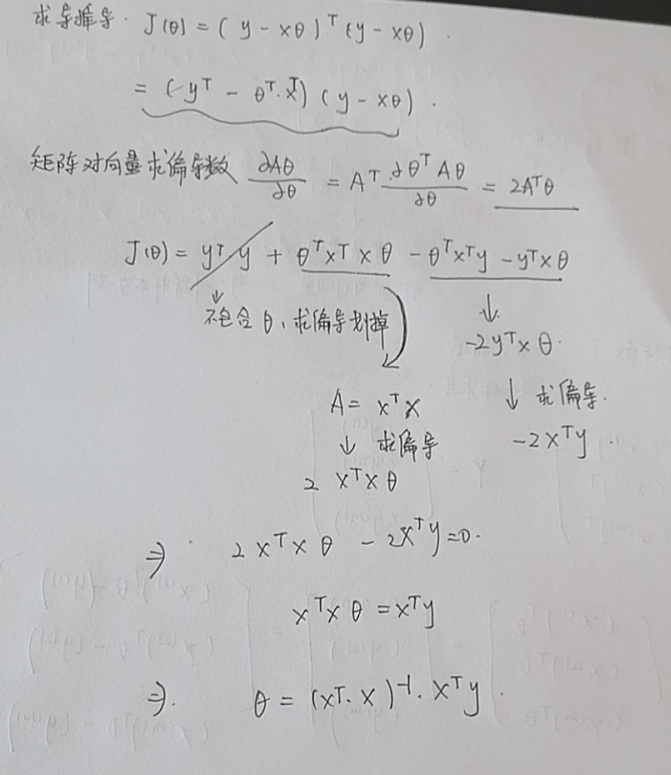
梯度下降VS最小二乘法
| 梯度下降 | 最小二乘 |
|---|---|
| 需要选择学习率 | 不需要选择学习率 |
| 需要多次迭代 | 不需要迭代 |
| 特征数多依旧工作很好 | 需要计算矩阵的逆 |
| n非常大的时候工作变慢 |
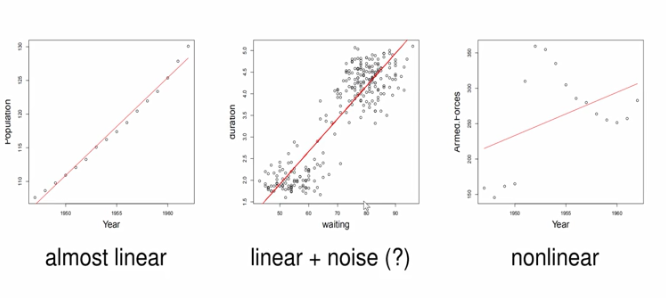
线性回归的概率解释

- 对于最左边的数据图,数据显然是符合线性分布的
- 中间的图,大体符合线性分布,中间伴随着噪声
- 最右边的图显然不是按照着线性分布的
我们可以使用线性模型来回归这些数据
对于有噪声的数据可以用一下的表达式来进行建模:
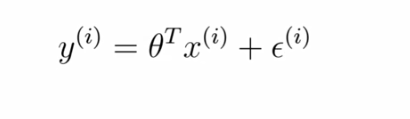
- 前面是对输入进行线性变换
- 后面加的是噪声项
- θ代表参数矩阵[θ0,θ1,θ2,θ3]^T
- e^i代表第i个数据的噪声

- εi代表第i个样本的噪音
- 它符合独立同分布假设
- 服从高斯分布,其实意思就是各个点基本上都均匀的分布在直线周围
- ε均值为0
由于ε符合正态分布,所以它的概率密度函数就可以展示出来:
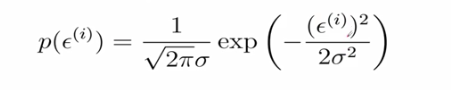
该式表名y围绕着直线周围分布,在模型给定的情况下,y是由直线上的点加上噪音构成的,y也是符合高斯分布的。均值:以直线上点为中心分布,方差不变。
下图是参数似然度,利用极大似然方法求解θ。
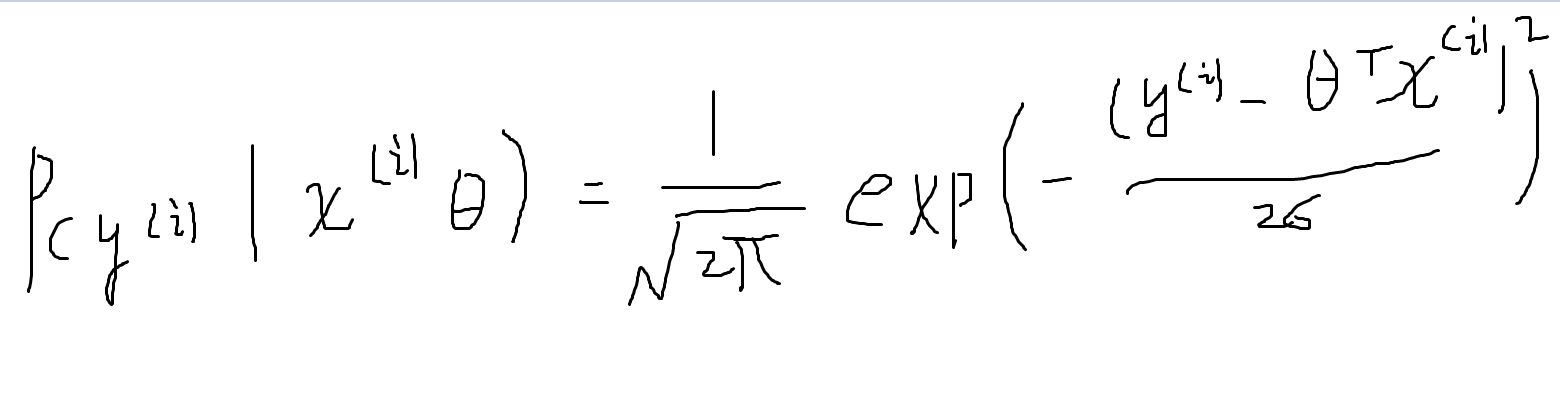
利用独立同分布的假设,将所有样本写出乘积的形式。

为了好计算求log的似然度:

求参数使得极大似然函数取得极大值,得到参数:

极大似然和均方误差结果是一样的,无论是采用极大似然取极大值,还是均方误差取极小值,结果都是一样的。
岭回归

对于多元线性回归,我们可以采用最小二乘法也就是normequation方法。用到该方法过程中,我们要求解矩阵的逆。但是我们知道有些矩阵是不可逆的,对于这种情况,对于不可逆的矩阵叫做奇异矩阵,我们应当如何求解呢?这就引出了岭回归的方法。
基本数学概念

- 矩阵与它的逆矩阵乘积是单位矩阵
- 只有方阵才有逆矩阵
- 不可逆矩阵称为奇异矩阵( singular matrix)
- 可逆矩阵称为非奇异矩阵
如何判断矩阵是非奇异还是奇异的呢(可逆不可逆)
从代数上若一个方阵A可逆,当且仅当该方阵对应的行列式(记为: detA)不为0
矩阵的秩

范数
- 用来衡量向量的大小
- 将向量映射到非负值的函数
- 范数是满足下列性质的任意函数:

范数的性质:
- 只有在向量本身为0的情况下,范数才为0
- 两个向量之和的范数小于两个向量之和
- 任意实数α,乘以一个向量的范数等于α乘以一个向量的范数
常用范数:
p=几就是几范数,代入下面的公式:
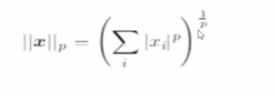

何时x^TX不可以逆
- 包含冗余特征(即这些特征不线性独立)
比如原来的特征为(x1,x2,x3,x4(面积用平方)),之后又加了一个特征x5(表示面积用平米),导致x4,x5两列线性相关,秩<n,进而导致矩阵不可逆
- 特征数比样本还多的时候
方程的个数比未知数的个数还要少,所以会导致r<n,无穷多解满足该情况,进而矩阵不可逆
如何用岭回归求解参数
罗生门现象:参数解不唯一,有很多个

解决方法:增加奥卡姆剃刀原理,增加正则化项

对于增加正则化项的损失函数求导并令其等于0,解出θ

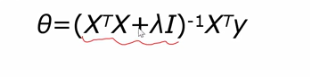
将不可逆的矩阵后面加了一个参数乘以单位矩阵(可逆),进而使得不可逆矩阵变成可逆矩阵,进而求解模型的参数。这个方法就叫做岭回归方法。
Lasso回归

不可逆时候也可以用lasso回归
- 增加的正则化项是一范数
- 一范数在零点不可求导