本文推荐搭配 一条 sql 的执行过程详解 查看。主要说明 InnoDB Buffer Pool 的内部执行原理,在使用索引时就加载对应的数据页到缓冲池中操作,如果没有用到索引会进行全表扫描,将所有数据都加载到缓冲池中查找、操作,如果数据量大会分批依次传入 Buffer Pool 进行查询。也就是说磁盘上的数据都是通过缓冲池来筛选读取的。
结构
在 InnoDB 存储引擎层维护着一个缓冲池,通过其可以避免对磁盘频繁的IO操作。下面是其内部结构的概要图(实际没有这么简单,本文只着重说一下它的“读”、“写”缓存)。其本质就是将磁盘上的数据页移到内存中,以此来减少对磁盘数据的直接IO。
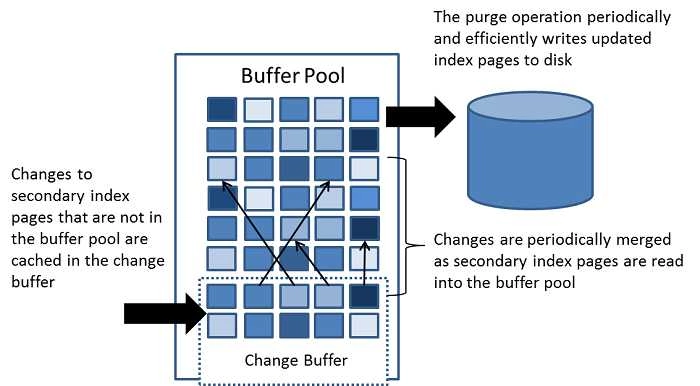
可以看到内部含有一个小区域,叫做 Change Buffer,这个是用 InnoDB 的 "写"缓存,而外面的是 InnoDB 的 “读”缓存。
读缓存
预读
MySQL 内部一般都会使用缓冲池,而如果多次语句操作的是相邻的记录,那么就会多次进行磁盘读取,导致速度降低,所以 MySQL 一般在读取数据时都是采用预读方式,读取指定数据周围的多条数据。而在 InnoDB 引擎中的数据是以页为单位进行存储的,并且提出了“数据页”概念。数据页的结构如下,大小默认为 16K,关于数据页这里就不过多阐述,感兴趣可以查看原博客。对硬盘上的数据读取最小单位就是数据页。
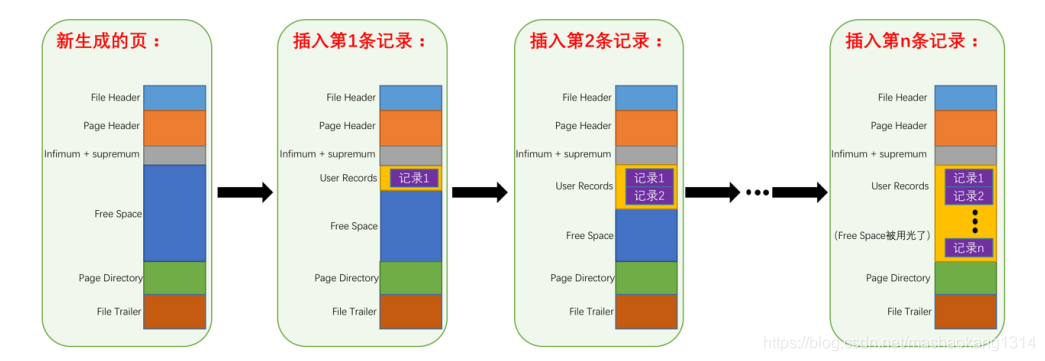
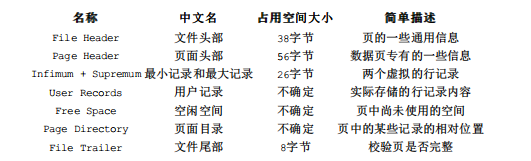
而在数据页上面,还分为区(Extent)、段(Segment)、表空间(Tablespace),它们之间的包含关系如下图。具体可以查看原博客。
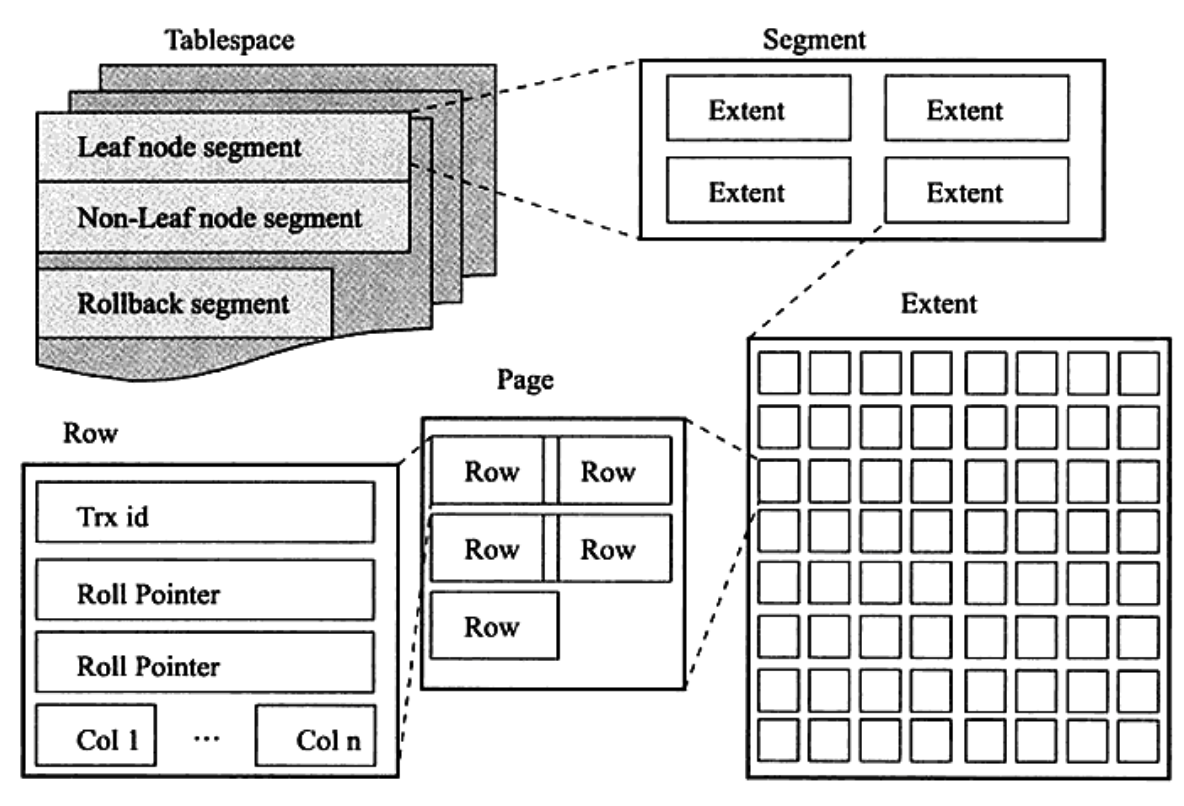
InnoDB 引擎在预读时, 有两种预读算法。线性预读和随机预读。
1、线性预读(innodb_read_ahead_threshold)
选择是否预读下一个 Extent 的数据。有一个重要的参数 innodb_read_ahead_threshold,如果当前 Extent 中连续读取的数据页超过规定值,就会将下一个 Extent 的数据也读到缓冲池中。innodb_read_ahead_threshold 的范围是 0-64(因为一个 Extent 也就64页)。
2、随机预读(innodb_random_read_ahead)
用来设置是否将当前 Extent 的剩余页也预读到缓冲池中,由于这种预读性能不稳定,所以MySQL 5.5开始默认关闭。
缓冲池的LRU算法
InnoDB 的缓冲池数据的存储算法是改进版的 LRU 算法,以此来避免了传统 LRU 算法的两个问题,预读失效和缓冲池污染。
LRU 算法简单来说,如果用链表来实现,将最近命中(加载)的数据页移在头部,未使用的向后偏移,直至移除链表。这样的淘汰算法就叫做 LRU 算法。但是其会含有前面说得两个问题。
1、预读失效
在磁盘上读取数据时,可能会因为操作不当导致多个用不到的数据页加载到缓冲池。从而导致之前经常被使用的数据页缓存被无用的数据页挤到尾部,甚至被移出缓存,那么就会降低性能。而 InnoDB 的解决方案是将缓冲池分为两部分,新生代和老年代,比例默认为5:3,分别存储常用的数据页以及不常用的数据页,新生代位于头部,新生代位于尾部,这两部分都有头部和尾部。当从磁盘的数据页移入缓冲池中时,首先是放入老年代的头部,然后进行筛选,使用到的数据页会移入新生代的头部,未使用的数据页会随着时间流逝而慢慢移入老年代的尾部,直至淘汰。
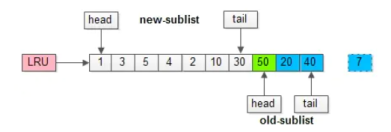
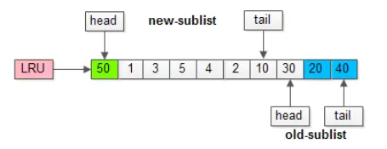
2、缓冲池污染。
在处理数据页时,如果需要对大量数据页进行筛选(但是没有用到),那么还是会使大量的热点数据页被挤出。如 select * from student where name like '张%';name字段包含索引,那么在执行时虽然会先加载到老年代的头部,但是因为每条数据都需要筛选,所以都会移入新生代头部,导致新生代热点数据页被挤到老年代甚至移除。InnoDB 为了解决这个问题,使用了 "老年代停留时间窗口" 机制,这个机制是设置一个时间,如果在老年代的数据页被调用后还需要去检查它在老年代的停留时间是否达到了这个规定时间,达到了才能移入新生代头部,否则只会移到老年代头部。
写缓存(Change Buffer)
写缓存(Change Buffer)在5.5之前叫做 插入缓存(insert Buffer),因为只支持插入的缓存,在随后版本又添加了 update、delete,所以改名 change Buffer。因为直接对磁盘进行IO操作会比较耗时,如果我们的程序在高并发的场景,同时某段时间写操作非常多,那么如果直接更新到磁盘上数据库的压力就会非常大,甚至崩溃。为了避免这种情况,可以错开高峰期,让数据在系统空闲时再更新到磁盘,那么该如何实现,Change Buffer就起到这样的作用。
名词
Merge:将 change buffer 中保存的 SQL 更新到缓冲池,并将 change buffer 的变更记入 redo log。
Purge:清理 undo log。
Flush:刷脏页,也就是将未应用到磁盘的修改更新到磁盘。在 flush 时会阻塞其他的操作。其本质是通过缓冲池中的脏页替换掉磁盘上对应的数据页。
脏页:内存中与磁盘数据不同的数据页称为 "脏页"。
执行
在写操作语句进来时,首先会判断缓冲池是否存在这条写操作对应的数据页,如果存在直接更新数据页中对应的数据,然后将对数据页的操作逻辑记入 redo log;如果不存在,那么会将对数据页的修改逻辑写入 Change Buffer 以及 redo log,等到下次读取未修改的数据页到缓冲池中会触发 Merge ,将 Change Buffer 中对应的写操作更新至该数据页,然后把 change buffer 的变更记入 redo log。(如果是插入操作且包含唯一索引那么当缓冲池中不存在对应数据页时直接将数据页读取到缓冲池然后判断唯一性,然后再把对数据页的修改逻辑写入 redo log,不会用到 change buffer)
redo log 的作用是保证修改数据不会丢失,因为此时这些写操作是没有更新到磁盘的,先持久化到文件中,如果发生断电异常重启后还可以通过 redo log 来还原写操作来修改到内存缓冲池中的数据,然后再通过缓冲池的数据页更新到磁盘。
Redo log 落盘(Flush)的时机
1、mysql系统后台会定期落盘
2、mysql 正常关闭时
3、redo log 满了时(redo log 是固定大小的,采用循环写)
4、缓冲池在读取数据页进来时内存不足需要淘汰部分数据页,而淘汰的数据页如果是脏页也会导致落盘。
Flush 控制
因为 flush 会阻塞其他操作,所以如果频繁地进行 flush 就会对 SQL 执行造成影响,这也是为什么有时候在执行简单的 SQL 时却产生了卡顿,这就是因为正好触发了 flush。所以需要去控制 Flush 执行来减少影响。
1、提高 flush 的速度。可以通过设置 innodb_io_capacity 参数来提高。这个参数表示刷脏页的最大能力,当然实际刷脏页的速度不是就一直是设置的最大值,它会根据当前脏页的比例和这个参数来调整。参数可以设置为磁盘的 IOPS。而磁盘的IOPS 可以通过 fio 来测试。测试命令:fio -filename=$filename -direct=1 -iodepth 1 -thread -rw=randrw -ioengine=psync -bs=16k -size=500M -numjobs=10 -runtime=10 -group_reporting -name=mytest
2、设置触发 flush 的脏页比例上限(对应触发 Flush 时机的第五条),通过 innodb_max_dirty_pages_pct 来设置。默认是 75%。
3、控制是否开启关联落盘。通过 innodb_flush_neighbors 来设置。如果为 0 表示在刷脏页时只会刷当前脏页,如果为 1 表示刷脏页时如果相邻的数据页也是脏页就一起更新到磁盘,而这个相邻的脏页如果相邻的数据页也是脏页那么也会更新到磁盘,直到相邻的不是脏页。如果当前机器磁盘 IO 能力比较差,那么可以开启,可以减少很多不必要的 IO,而如果磁盘 IO 比较强,可以开启来提高此次执行的响应速度。在 MySQL8.0 中已经将此参数默认值设为 0。
Change Buffer 适用场景
1、更新后立刻读取该数据的操作少。如果操作的数据页在缓冲池中不存在,那么会将修改逻辑存入 change buffer,而读取缓冲池不存在的数据页时又需要加载到缓冲池,将 change buffer 中的该数据页的写操作逻辑应用到缓冲池,并将 change buffer 的变更记录到 redo log,而 change buffer 的目的就是减少对磁盘数据页的读取,所以 change buffer 并没有起到作用,同时还增加了 change buffer 的维护成本。
2、非唯一索引,如果使用的是唯一索引进行插入操作,那么操作的数据需要进行唯一性检查,所以必须将相应数据页先加载到缓冲池中,判断是否唯一,如果唯一才能更新,过程中不会用到 Change Buffer。
Redo log 与 Change Buffer 的关系
redo log 是记录修改操作,防止断电丢失写操作,降低随机写消耗(转成顺序写);Change Buffer 是为了将写操作延迟更新到缓冲池,降低随机读的消耗(不需要频繁从磁盘读数据页)。
相关参数
Buffer Pool :
1、innodb_buffer_pool_size:缓冲池大小,在内存足够的条件下,越大越好。
2、innodb_old_blocks_pct:老年代占整个LRU链长度的比例,默认是37,即整个LRU的新生代和老年代长度比例是63:37。(如果配置是100就变成普通的LRU了)
3、innodb_old_blocks_time:老年代停留时间窗口,单位是毫秒,默认是1000,即同时满足“被访问”与“在老年代停留时间超过1秒”两个条件,才会被插入到新生代头部。
4、show engine innodb status 结果 " Buffer pool hit rate " 显示内存命中率。
Change Buffer:
1、innodb_change_buffer_max_size:
配置写缓冲的大小,占整个缓冲池的比例,默认值是25%,最大值是50%。
画外音:写多读少的业务,才需要调大这个值,读多写少的业务,25%其实也多了。
2、innodb_change_buffering:
介绍:配置哪些写操作启用写缓冲,可以设置成all/none/inserts/deletes等。
参考博客: