前言:本人文学素养较差,且阅读来源为外文翻译书籍,所以本篇博客诸多解释和引用的内容在阅读上可能会造成不适和理解障碍,敬请谅解!博客中涉及到多处数学表达式,我是在本地使用word编辑的,内容是直接从本地粘过来的,所以这些数学公式在博客的网页上能否很好的显示我也不太清楚,就这样吧。。。~如果数学公式不能很好的显示的话,请从网盘自行提取链接: https://pan.baidu.com/s/1C2IBJi4lHE8aA6zWPVpGDw 提取码: n2kd
阅读来源:《机器学习》 Tom M.Mitchell 著 机械工业出版社
增强学习1
增强学习要解决的是如下的问题:一个能够感知环境的自治agent(可以简单的理解为具有学习能力的机器人),通过怎样的学习方式选择能达到其目的的最优动作。在agent在其环境中做出每个动作时,施教者会提供奖励或惩罚措施以表示结果状态的正确与否。典型场景可见在学习棋类对弈时,在训练agent进行棋类对弈时,施教者可在游戏胜利时给出正回报,而在游戏失败时给出负回报,其他时候给出零回报。agent需要在这样一个非直接的、有延迟的回报中学习,以便后续的动作产生最大的累积回报。
显然,我们关系的问题是,agent如何在其环境中做实验并成功学习到控制策略,假定agent的目标可被定义为一个回报函数,这个回报函数对agent在不同状态中选取不同的动作赋予一个数字值,即立即回报。这个回报函数可内嵌在agent中,或者只有外部施教者知道。agent执行一系列动作,观察其后果,再学习控制策略。我们希望的控制策略是能够从任何初始状态选择恰当的动作,使agent随时间的累积获得的回报达到最大。配图1展示了agent学习问题的一般框架。图中涉及到了状态s、状态集S、动作a、动作集A、目标函数。

上面提到的目标函数是控制策略π:S -> A。它在给定当前状态S集合中的s时,从动作集A中输出一个合适的动作a。
不过从图中给出的那个最大回报的求和公式∑_0^∞▒〖γ^i 〖 r〗_i 〗中可以看出,增强学习有几个特点:
延迟回报,agent的任务是学习一个目标函数π,它把当前状态s映射到最优动作a = π(s)。在增强学习中施教者只在agent执行序列动作时提供一个序列立即回报,而不提供显式的训练样本<s,π(s)>。可以理解为不会像训练一个简单的神经网络一样,我们在训练前就已经准备好了输出样例和对应的输出样例。增强学习可能会出现这样的情况,agent执行了一个动作,这个动作可能是很一般的动作,也可能是施教者可能没有想到过或者极少的情况,但是作为施教者必须在agent执行了这次动作后提供一个立即回报值。也就是说,我们在训练一个神经网络的流程是通过已知来预测未知,但是在增强学习的过程中可能在agent训练时就会出现需要“预测”的情况发生,不过在不同的环境和具体问题设立的条件下,有些增强学习过程是可以避免这种不确定因素发生的。在这种学习机制的条件下,agent面临一个时间信用分配的问题,它需要确定最终回报的生成应归功于序列中哪一个动作。
探索,增强学习的过程中,学习器面临权衡,agent既可以选择探索未知的状态和动作,也可以利用已经学会的可以产生高回报的状态和动作来使累积回报最大化。如何选择、如何决策才能产生最好的学习效果呢?
部分可观察状态,在实际的agent学习过程中,其传感器只能提供部分信息,只有前置摄像头的agent不能看到它背后的情况。在此情况下可能需要结合考虑其以前的观察以及当前的传感器数据来选择动作,而最优策略可能是选择特定动作改进环境可观察性,比如这个agent可以逆时针或者顺时针转90°,使原先观察的前后方位现在可以兼顾(变成左右,假设这个agent左右可以同时兼顾),然后再决定向左侧移动还是右侧移动(现在的左右侧是之前的前后侧)。
终生学习,agent可能被要求再相同环境中使用相同传感器完成多个学习任务,比如再狭小走廊中获取固定位置的物体。这使得有可能使用先前获得的经验或知识在学习新任务时减小样本复杂度。(这句话是我原封不动的从书上抄下来的,这句话只可意会,拿正规的语法是没法划分这个句子的成分的,正所谓成分杂糅。。。)
下面我们规范化这个学习任务,按照马尔可夫决策过程(MDP)来定义这个问题的一般描述。MDP中,agent感知到其环境的状态集S中的任意一个状态,并且可以执行动作集合A中的任意动作。在每个离散时间步t(可以简单理解为一个时间步长或时间单位),agent当前状态s_t,选择当前动作a_t并执行它。环境响应此agent给出回报r_t= r(s_t,a_t),产生一个后继状态s_(t+1)=δ(s_t,a_t)(从这个递推公式可以很明显的看出动态规划的内容,这个等式说白了就是个状态转移方程)。函数δ和r是环境的一部分,agent并不知道。一般情况下这两个函数是不确定的,但我们首先从确定性的情形开始。强调一次,agent的学习任务是学习一个策略π:S -> A,agent基于当前状态s_t,选择动作a_t,即π(s_t )=a_t。一个明显的指定学习策略的方式就是求解此策略对agent产生的最大累积回报。我们定义:通过遵循一个任意策略π从任意初始状态s_t获得的累积值为无穷级数V^π (s_t )=∑_(i=0)^∞▒γ^i r_(t+i)。其中,回报序列r_(t+i)的生成是通过由状态s_t开始并重复使用策略π来选择上述的动作,这里很明显又是个迭代递推状态转移的过程,π(s_t )=a_t,s_(t+1)=δ(s_t,a_t),π(s_(t+1) )=a_(t+1)。这里0≤γ<1,即一个小于1的非负数,它确定了延迟回报和立即汇报二者之间的相对比例,在未来的第i时间步收到的回报被因子γ^i以指数折算。当γ=0时,累积值只考虑立即回报;当γ接近1时,未来的回报会更有价值些。这个累积量称为由策略π从初始状态s_t获得的折算累积回报。现在进一步阐述agent的学习任务,我们要求agent学习一个策略π,使得对于所有状态s,V^π (s)最大。这个策略称为最优策略,并用π^*来表示。
π^*=〖argmax〗_π (V^π (s)) ,∀s
下面举一个例子,这个例子就是书上的例子,节约时间起见这里我直接贴图:
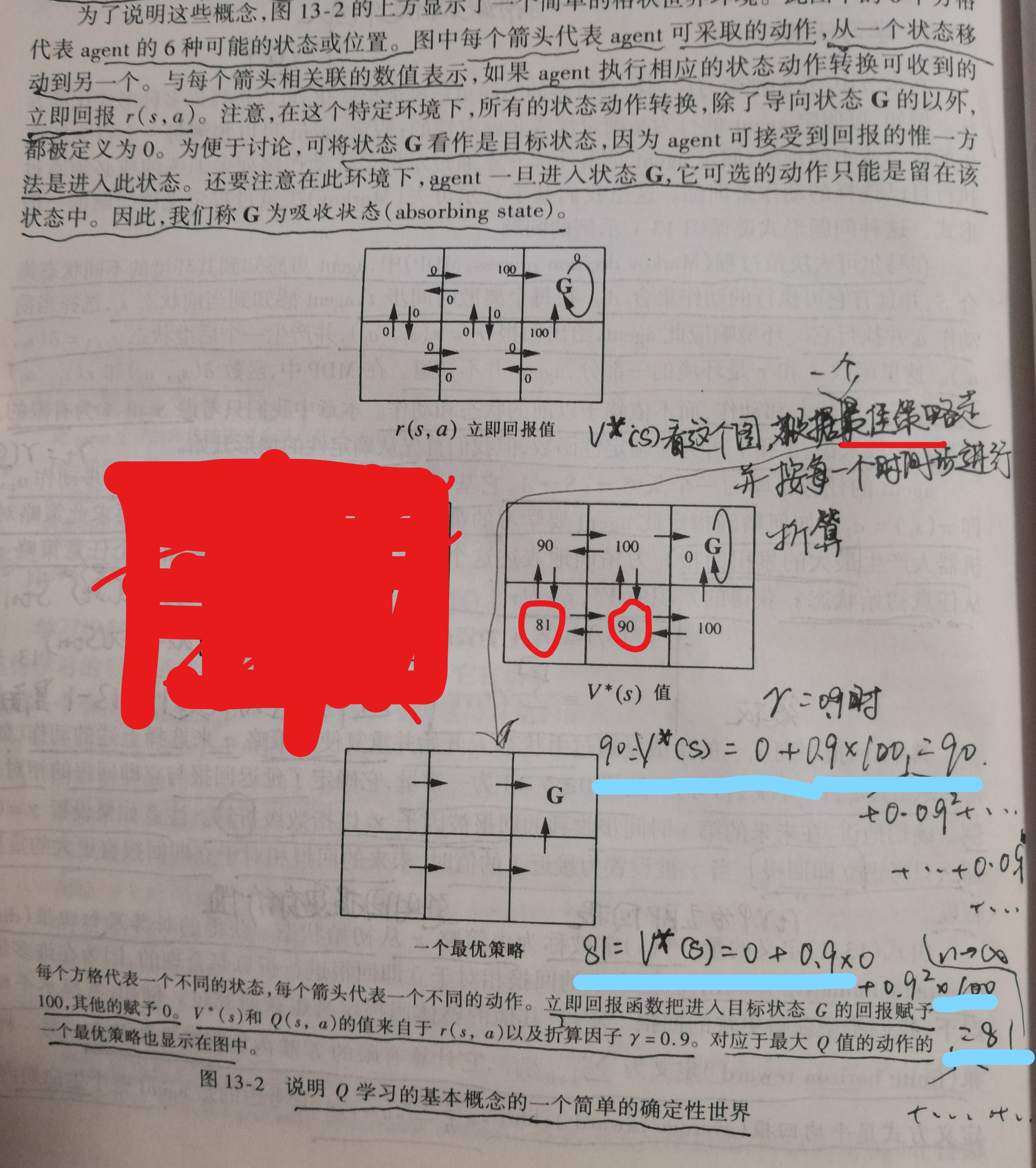
如果你很疑惑图中V^π (s_t )的值是怎么来的的话,我们选择γ=0.9,我写出了左下角81和中下90两个位置的计算,都是根据配图中给出的那个最优策略,根据那个无穷级数计算,由于进入了G后agent可选择动作只能是留在该状态中,所以两个算式中会有无穷多个0相加的部分,不过这些部分是实实在在的0相加,跟无穷小相加的概念不同,不需要额外的极限计算就可得到。
不过上述就是一个简单的案例,它已经给出了一个最优策略。然而一个agent直接学习函数π^*:S→A非常困难,因为训练数据中没有提供<s,π(s)>,这一点在上面我们提到了。作为替代,唯一可用的训练信息就是立即回报数列r(s_i,a_i),因此很容易学习一个定义在状态s和动作a上的数值评估函数,然后以此评估函数的形式来实现最优策略。很明显评估函数的一个选择是上面提到的V^*,只要V^* (s_1 )>V^* (s_2 )时,agent认为状态s1优于状态s2。当然agent的策略要选择的是动作而非状态,即我们需要得到a= π^* (s),而根据
π^*=〖argmax〗_π (V^π (s)) ,∀s
可知使用V^*也可以选择动作,即〖a= π〗^* (s)=〖argmax〗_a (V^π (s)) ,而前面提到的众多递推关系r_t= r(s_t,a_t),s_(t+1)=δ(s_t,a_t),π(s_(t+1) )=a_(t+1),V^π (s_t )=∑_(i=0)^∞▒γ^i r_(t+i),可知V^* (s_t )=r(s_t,a_t )+〖γV〗^* (s_(t+1) )(这里其实是数列题里面经常出现的一个变形技巧,不难看出),即书上那个公式〖 π〗^* (s)=〖argmax〗_a [〖r(s,a)+〖γV〗^π (δ(s,a))],这个最终的状态转移方程可以解释为,在状态s下的最优动作是使立即回报r(s,a)加上立即后续状态的V^*值(已经被γ折算过的)最大的动作a。当agent得知回报函数r和状态转移函数δ时,就可以通过上述表达式来计算任意状态下的最优动作a了。可是在一般状态下,当回报函数r或状态转移函数δ都未知时,学习V^*是无助于选择最优动作的,因为agent不能通过该式进行评估。这个时候agent使用什么样的评估函数呢?这个问题留给明天。
====================================================================================
今天就说这么多吧,寒假没怎么学习,考研结束后一直都是提不起劲的状态,毕设做来做去也就做不下去了,没什么乐趣。
倒是今天晚上写这篇博客燃起了我极大的热情,现在已经是凌晨0:31了,晚安!