最近由于项目需要用到caffe,学习了下caffe的用法,在使用过程中也是遇到了些问题,通过上网搜索和问老师的方法解决了,在此记录下过程,方便以后查看,也希望能为和我一样的新手们提供帮助。
顺带附上老师写的教程
安装Caffe并运行Mnist例程
我主要参考了这篇教程: Mac极简安装Caffe并训练MNIST。然后进行了examples文件夹里的Mnist的训练,期间并没有碰到什么问题。
将图片转换为LMDB文件
Mnist中已经给出了现成的LMDB数据文件,在实际项目中,需要我们将图片文件转换为LMDB文件。可以参考下examples里的imagenet,里面的readme写了完整的过程,也可以参考上面贴的教程。在这里就不复述了,主要说下注意点:
转换文件只要参考imagenet的create_imagenet.sh并更改相应路径即可,如下:
set -e
#生成的lmdb文件夹位置
EXAMPLE=examples/myMnistTest
#train.txt和val.txt位置
DATA=examples/myMnistTest/MNIST_Dataset
#tools文件夹位置,写相对位置的话要在caffe根目录运行
TOOLS=build/tools
#train图片位置
TRAIN_DATA_ROOT=/Users/messier/caffe/examples/myMnistTest/MNIST_Dataset/train_images/
#val图片位置
VAL_DATA_ROOT=/Users/messier/caffe/examples/myMnistTest/MNIST_Dataset/train_images/
# Set RESIZE=true to resize the images to 256x256. Leave as false if images have
# already been resized using another tool.
#这边写成false,我写了true结果生成了10个多GB的lmdb...不过训练出来的模型还是能用的
RESIZE=true
if $RESIZE; then
RESIZE_HEIGHT=256
RESIZE_WIDTH=256
else
RESIZE_HEIGHT=0
RESIZE_WIDTH=0
开始训练
这一步之前可以选择进行计算图像均值的操作。然后去mnist文件夹中把之前用到过的prototxt拿过来,更改路径,按之前的操作进行即可。
要注意的是,没进行过均值操作的话,要把所有的mean_pixel注释掉。

在opencv中调用训练好的模型
opencv3.3中将dnn模块从contrib中提到了主仓库中,可以直接调用caffe训练好的模型,且不需要任意依赖。
这里我主要参考了opencv中一个用caffe模型识别航空飞机的sample。
稍加修改即可。
首先要把几个文件的路径改下,如下:
String modelTxt = "lenet_deploy.prototxt";
String modelBin = "_iter_6714.caffemodel";
String imageFile = (argc > 1) ? argv[1] : "3_00715.jpg";
需要注意的是,当时训练用的模型文件不能在这里直接用了,要把输入和输出改下,如下:
- 更改输入
原来:
name: "LeNet"
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
scale: 0.00390625
}
data_param {
source: "./train_lmdb"
batch_size: 64
backend: LMDB
}
}
更改为:
name: "LeNet"
input: "data"
input_dim: 1 #每次输入图片数
input_dim: 1 #channels
input_dim: 256 #width
input_dim: 256 #height
2.更改输出:
原来:
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip2"
bottom: "label"
top: "loss"
}
更改为:
layer {
name: "prob"
type: "Softmax"
bottom: "ip2"
top: "prob"
}
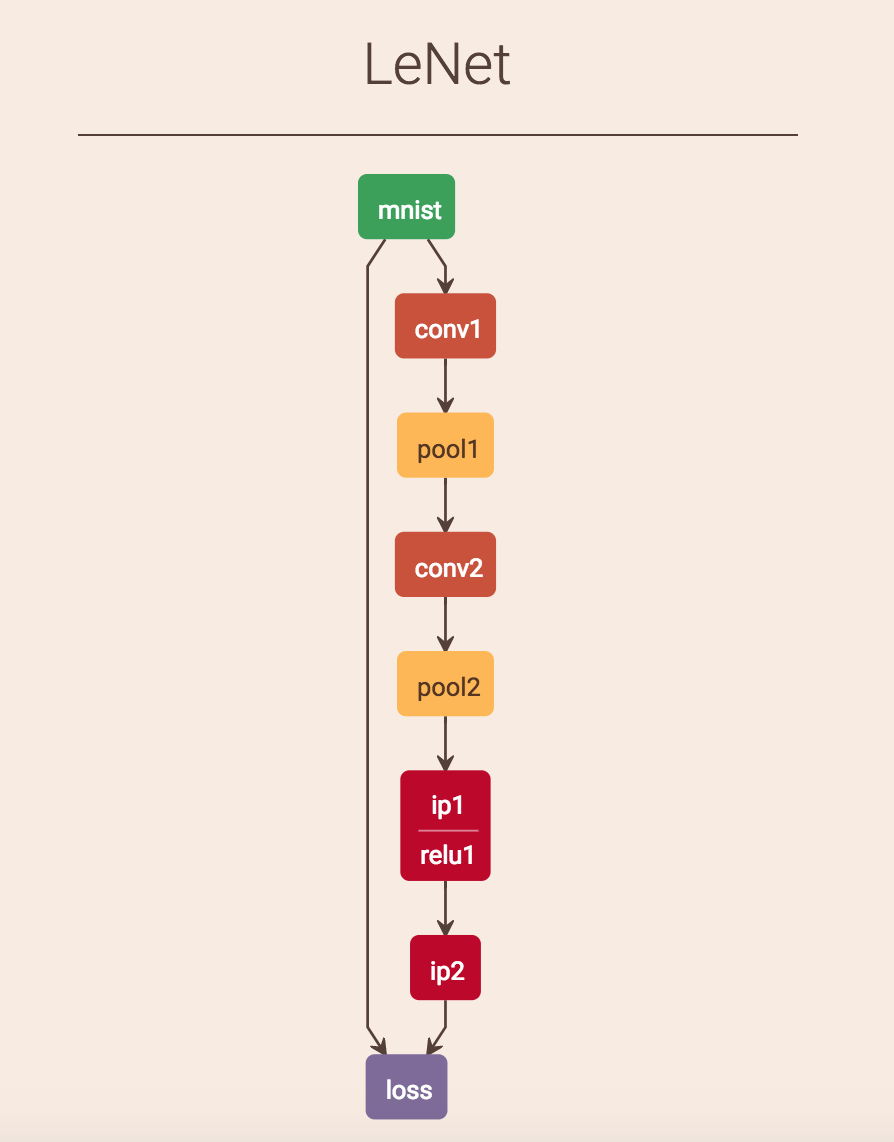
在这里推荐下老师告诉我的caffe网络可视化工具Netscope
看下更改前后的网络:

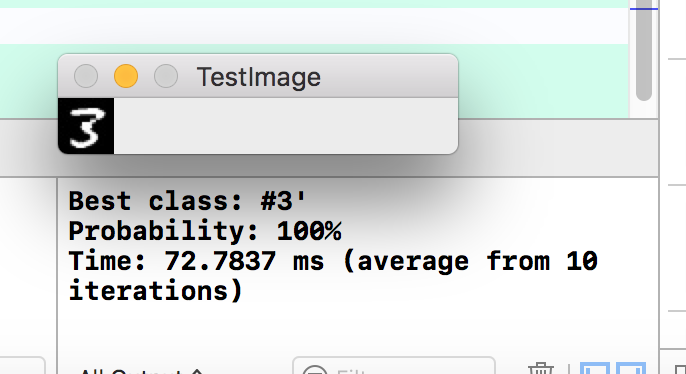
最后程序运行结果如下:
12.12更新:程序源码已经上传了,直接用cmake构建工程即可。
顺带再略微解析下程序的流程:
1、 载入模型文件
readNetFromCaffe(modelTxt, modelBin);
2、 读取图片,转换为blob的数据格式。
Mat inputBlob = blobFromImage(img, 0.00390625f, Size(256, 256), Scalar(), false); //Convert Mat to batch of images
看下这个函数,第一个参数是图片,第二个参数是训练时的特征缩放系数,这里是1/256,第三个参数是blob对应的图片大小,之前说过,我在训练时误把图像缩放到了256* 256,这里输入图像大小还是28 * 28的,但作为输入要缩放到256*256,第四个参数是各通道均值,我没作均值处理所以给默认值,第六个参数的意思是是否交换R B通道,这里是单通道图片所以不交换。
3、 前向传播,计算各个label的prob,结果用一个10维向量保存。
Mat prob;
cv::TickMeter t;
for (int i = 0; i < 10; i++)
{
CV_TRACE_REGION("forward");
net.setInput(inputBlob, "data"); //set the network input
t.start();
prob = net.forward("prob"); //compute output
t.stop();
}
4、 找出prob最大的label,输出结果。
getMaxClass(prob, &classId, &classProb);