Auto-batching是Cocos2d-x3.0新增的特性,目的是为了代替SpriteBatchNode,完毕渲染的批处理,提高绘制效率。
至于它有什么特点,能够看看官方文档,这里主要想探讨Auto-batching一些条件限制,简单地从源代码方面去分析。
主要想分析的问题就是:为什么不连续创建的精灵(同样纹理、同样混合函数、没有对shader做什么处理)不能满足Auto-batching的要求?
=========== 以下是回顾,是我对Auto-batching产生疑惑的过程,能够忽略不看=========
这得从前几天说起(小若:我们不是来听故事的!),我在更改之前SpriteBatchNode的教程,由于Cocos2d-x3.0新增了Auto-batching,于是就不得不把它也加进去。
这一加,不正确劲,越写越发现自己对Auto-batching的理解有误,在我的脑海中,仅仅要精灵是使用同一个纹理、没有更改blendFunc、没有更改shader,那么就满足Auto-batching,会自己主动将这些精灵加入到同一个渲染批次里,优化渲染速度。
可我才刚准备写一个样例,却发现,不正确!没有自己主动批处理。我当时做了这样一个实验,代码例如以下:
我创建了两组精灵,分别使用sprite0.png和sprite1.png图片,每组14100个(小若:为什么非得是14100,为什么不能是14000?你让我们这些强迫症的人怎么办?!)。
依照我对Auto-batching的误解,这两组精灵应该各自都能满足,都能分别作为一组批处理进行渲染。然而,执行结果例如以下:

GL calls(渲染批次)居然是16425次?这和想象中的全然不一样,不是应该是个位数么?
这颠覆了我对Auto-batching的理解,于是,我又做了一些实验,发现了一些谬论,但结果是好的,由于我知道,我对Auto-batching的理解一直都是错的。
关于我做的那几个实现,大家能够看看这个帖子:Cocos2d-x3.0 Auto-batching 三个小实验
由于是使用Windows平台做測试的,然后我的电脑配置比較高(小若:这是在炫耀的意思么?敢亮出你的配置吗?),所以帧率不能作为參考。
总之,那个帖子得出的疑问是:为什么不连续创建的精灵(同样纹理、同样混合函数、没有对shader做什么处理)不能满足Auto-batching的要求?
一定是我对Auto-batching产生了误解,它应该另一些我不知道的限制。
好,既然知道我对Auto-batching产生了误解了,我当然就要再一次去看官方文档了,首先是中文文档:
https://github.com/chukong/cocos-docs/blob/master/manual/framework/native/v3/auto-batching/zh.md
重复看了好几次,不行,全然找不到能对这个问题有帮助的内容,可是我找不到英文文档。
终于还是找到了,它并非真正的文档,仅仅是一些计划路线,可是对这个问题也非常有帮助,标题是《Cocos2d (v.3.0) rendering pipeline roadmap》:
对着这份文档看,以及调试源代码,总算弄明确这个问题了。
简单地说,要绘制的精灵(应该说是Node)先存放到队列里,然后由专门的渲染逻辑来渲染。对于队列中的精灵,一个个取出来(事实上存取的不是精灵,这里先简单这么理解),发现材质一样的话(同样纹理、同样混合函数、同样shader),就放到一个批次里,假设发现不同的材质,则開始绘制之前连续的那些精灵(都在一个批次里)。然后继续取,继续推断材质。
假设同样材质的精灵,中间间隔了不同材质的精灵,那也没法在同一个批次里渲染。
这就是那个问题的答案:为什么不连续创建的精灵(同样纹理、同样混合函数、同样shader)不能满足Auto-batching的要求,由于仅仅要中间有不同材质的渲染对象,就会中断,会先把之前连续的同样材质的对象进行批渲染。
======================== 以上是回顾,回顾结束========================
好了,上面是回顾的过程,并且已经有了大致的结论,如今正式来用代码解释。
笨木头花心贡献,啥?花心?不呢,是用心~
转载请注明,原文地址: http://www.benmutou.com/blog/archives/1006
文章来源:笨木头与游戏开发
渲染流程
如今,一个渲染流程是这种:
(1)drawScene開始绘制场景
(2)遍历场景的子节点,调用visit函数,递归遍历子节点的子节点,以及子节点的子节点的子节点,以及…
(小若:够了!给我停!)
(3)对每个子节点调用draw函数
(4)初始化QuadCommand对象,这就是渲染命令,会丢到渲染队列里
(5)丢完QuadCommand就完事了,接着就交给渲染逻辑处理了。
(7)是时候轮到渲染逻辑干活干活,遍历渲染命令队列,这时候会有一个变量,用来保存渲染命令里的材质ID,遍历过程中就拿当前渲染命令的材质ID和上一个的材质ID对照,假设发现是一样的,那就不进行渲染,保存一下所需的信息,继续下一个遍历。好,假设这时候发现当前材质ID和上一个材质ID不一样,那就開始渲染,这就算是一个渲染批次了。
看官方的一张图就全然明确了:
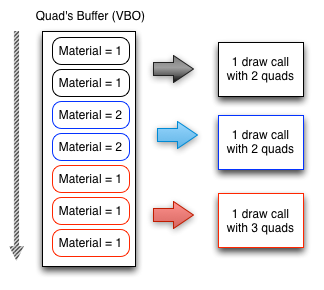
(8) 因此,假设我们创建了10个材质同样的对象,可是中间夹杂了一个不同材质的对象,假设它们的渲染命令在队列里的顺序是这种:2个A,3个A,1个B,1个A,2个A,2个A。那么前面5个同样材质的对象A会进行一次渲染,中间的一个不同材质对象B进行一次渲染,后面的5个同样材质的对象A又进行一次渲染。一共会进行三次批渲染。
(小若:突然发现,第6条哪去了啊?被你吃了吗)
这么一说,太含糊了,我们再来一次,用代码来罗列。
1. drawScene開始绘制场景
首先是開始,简单点,看代码:
调用drawScene函数,開始绘制场景
2.遍历场景的子节点
接下来,drawScene函数里有一小段代码(我就不贴全部了,多吓人):
没错,调用visit函数遍历场景的全部子节点(包含子节点的子节点,一直递归),然后做一些操作。
3.对每个子节点调用draw函数
当然,我们终于关心的是,调用这些子节点的draw函数。
我删掉了一些吓人的代码。
4.初始化QuadCommand对象,这就是渲染命令
上面的代码就是重点了,初始化_quadCommand对象,这就是QuadCommand,渲染命令。
事实上渲染命令不仅仅仅仅有QuadCommand,还有其它的,比方CustomCommand,自己定义渲染命令,顾名思义,就是我们用户自己定制的命令,由于我没有使用过,就不介绍了。
然后,接着就调用addCommand函数将渲染命令加入队列。
这里有一点,也非常重要,由于渲染命令有好几种,所以addCommand的时候,事实上是会依据不同的命令类型把渲染命令加入到不同的队列。本文仅仅想针对QuadCommand,所以就忽略这一点,假设我们的全部命令都是QuadCommand。
5.丢完QuadCommand就完事了
draw函数执行完,就轮到渲染逻辑干活了。
6.開始渲染
轮到渲染逻辑干活了,之前介绍了,渲染命令有好几种,假设我没有理解错误的话,仅仅有QuadCommand才干參与自己主动批处理,因此,这里会对渲染命令进行筛选,发现是QuadCommand类型的命令就保存到一个队列里。如代码:
为了避免大家睡着了,我把非常多重要的代码删了,我们仅仅要关注_batchedQuadCommands.push_back(cmd);。_batchedQuadCommands就是QuadCommand命令队列了。
接着,调用drawBatchedQuads函数遍历QuadCommand命令队列:
又为了避免大家睡着了,我删了非常多重要的代码。(小若:我说,重要的代码随便删除真的好吗?)
大家睁大耳朵鼻子什么的看看,_lastMaterialID是重点,当发现当前遍历的渲染命令的材质ID和_lastMaterialID不一样时,就会開始进行渲染,然后记录新的材质ID,继续遍历。
这就是我们所说的,仅仅有连续的同样材质ID的对象才会被放到同一个批次里进行渲染,假设不连续,那么材质ID再怎么同样也没有办法了。
对了,_drawnBatches变量就是我们左下角常常看到的GL calls的数字了~
7. 为什么必须要同样纹理、同样混合函数、同样shader?
要满足Auto-batching,就必须有这三个条件,这是为什么呢?
我们回到之前的代码,在调用节点的draw函数时,调用了QuadCommand的init函数:
这个init函数就是关键:
init函数里最后调用了generateMaterialID函数,这个函数就是关键。(小若:够了你,什么都是关键,关键个毛线啊)
看到没?~我们的材质ID(_materialID)终于是要由shader(_shader->getProgram())、混合函数ID(blendID)、纹理ID(_textureID)组成的啊喂!所以这三样东西假设有谁不一样的话,那就无法生成同样的材质ID,也就无法在同一个批次里进行渲染了。
当然,至于为什么要这样生成材质ID,我就没有去深究了,我仅仅是个写游戏的,引擎底层,还是交给Cocos2d-x团队的人吧(邪恶)。
8. 如何才干让同样材质的对象的渲染命令连续排列?
不连续的渲染命令,即使材质ID同样也没实用,那,我们应该怎么让这些家伙连续起来呢?
这个问题好办,还记得场景绘制的时候会遍历全部子节点吧?
在遍历子节点之前,事实上还偷偷做了一件事情,那就是,调用sortAllChildren();函数对子节点进行排序,对照的规则是:
好吧,我们不要管代码了(小若:那你还贴个毛线啊,非常吓人的好不好)。
总之,排序的规则是依照子节点的localZOrder和orderOfArrival进行的,orderOfArrival是用于localZOrder同样的情况下,进一步区分渲染顺序的(就是谁在上面谁在以下,额,请不要想歪)。
那么,我们仅仅要调整节点的zOrder就能改变节点的遍历顺序,于是,节点的QuadCommand加入顺序也就被改变了。
可是,注意,可是来了,除了场景子节点会进行排序之外,在渲染逻辑里,渲染命令队列也会进行一次排序:
当然,我删了非常多重要的代码renderqueue是RenderQueue对象,就是用于保存渲染命令的队列,它的sort函数是这种:
总之,结论就是,假设没有对节点的globalOrder进行设置,那就仅仅须要调整节点的localZOrder,便能够实现对渲染命令的排序顺序进行控制。
来看以下的代码,一開始贴过的:
这样创建的精灵肯定就没法连续了,由于sprite0.png的精灵和sprite1.png的精灵是不断间隔着创建的,没有连续。并且它们默认的localZOrder都是0,所以排序不起效。
那么,略微改改就好了,例如以下:
仅仅是给精灵分别指定了localZOrder值,这样在排序的时候sprite0.png的精灵就会在一起,同样,sprite1.png的精灵也会在一起。
执行结果,来一个非常壮观的截图:

渲染批次是5,等等!为什么是5?为什么不是2?
9. 渲染队列存储上限
继续回答刚刚的问题,图中的渲染批次是5,为什么是5?为什么不是2?
首先,即使我一个精灵也不创建,渲染批次也至少是1。
那么,我创建了两组材质ID同样的精灵,理论上GL calls应该是3,为什么是5?
这个也非常easy,由于渲染队列最大仅仅存放10922个渲染命令,注意,是“仅仅存放”而不是“仅仅能存放”,这个仅仅是在代码里做的限制。
当渲染队列(指的是Render类的成员变量:std::vector<QuadCommand*> _batchedQuadCommands; ,之前有讲到)存放的渲染命令大于10922时,就会自己主动进行一次渲染操作,
把队列里的渲染命令处理掉。
因此,我创建了2组精灵,每组14100个,已经超过了10922的范围,所以,即使这2组精灵各自都是同样的材质,但也不得不被分成2次进行渲染,于是,这2组精灵共进行了4次渲染操作。
再加上GL calls默认就有1(为什么默认会有一次,我就没有去研究了),那么,就是5次了。
话又说回来了,谁家的游戏那么夸张,要创建28200个精灵啊!这样那些跑分8000左右的手机怎么办啊,我在自己手机里试过了,帧率是60!没错,是60,已经太慢了无法正确计算了。由于每一帧的渲染消耗的时间是2秒多!
一帧就消耗2秒多,太刺激了。
嗯,跑题了。
结束语
好了,关于Auto-batching的探索之旅总算是结束了。
我对OpenGL的东西还真不太懂,所以,有可能在研究代码的时候有一些东西被我忽略了,或者误解了,假设文章有错误的地方,那…你来打我啊(别,开玩笑的)。
PS(2014.06.18):
今天偶然发现我这篇文章的部分内容被放到官方文档里了,有种受宠若惊的感觉~
但非常奇怪的是,文档里居然没有注明出处,这个...就没关系了。
为了避免以后大家反过来,以为我这篇文章是摘录了官方文档,特此说明。
文档地址:
https://github.com/chukong/cocos-docs/blob/master/manual/framework/native/v3/auto-batching/zh.md#rd
http://cn.cocos2d-x.org/tutorial/show?id=784