前言
在日常工作中,经常要判断一个元素是否在一个集合中。假设你要向浏览器添加一项功能,该功能可以通知用户输入的网址是否是恶意网址,此时你手上有大约 1000 万个恶意 URL 的数据集,你该如何实现该功能。按我之前的思维,要判断一个元素在不在当前的数据集中,首先想到的就是使用 hash table,通过哈希函数运行所有的恶意网址以获取其哈希值,然后创建出一个哈希表(数组)。这个方案有个明显的缺点,就是需要存储原始元素本身,内存占用大,而我们其实主要是关注 当前输入的网址在不在我们的恶意 URL 数据集中,也就是之前的恶意 URL 数据集的具体值是什么并不重要,通过吴军老师的《数学之美》了解到,对于这种场景大数据领域有个用于在海量数据情况下判断某个元素是否已经存在的算法很适合,关键的一点是该算法并不存储元素本身,这个算法就是 — 布隆过滤器(Bloom filter)。
原理
布隆过滤器是由巴顿.布隆于一九七零年提出的,在 维基百科 中的描述如下:
A Bloom filter is a space-efficient probabilistic data structure, conceived by Burton Howard Bloom in 1970, that is used to test whether an element is a member of a set.
布隆过滤器是一个数据结构,它可以用来判断某个元素是否在集合内,具有运行快速,内存占用小的特点,它由一个很长的二进制向量和一系列随机映射函数组成。而高效插入和查询的代价就是,它是一个基于概率的数据结构,只能告诉我们一个元素绝对不在集合内,布隆过滤器的好处在于快速,省空间,但是有一定的误判率。布隆过滤器的基础数据结构是一个比特向量,假设有一个长度为 16 的比特向量,下面我们通过一个简单的示例来看看其工作原理,:

上图比特向量中的每一个空格表示一个比特, 空格下面的数字表示当前位置的索引。只需要简单的对输入进行多次哈希操作,并把对应于其结果的比特置为 1,就完成了向 Bloom filter 添加一个元素的操作。下图表示向布隆过滤器中添加元素 https://www.mghio.cn 和 https://www.abc.com 的过程,它使用了 func1 和 func2 两个简单的哈希函数。
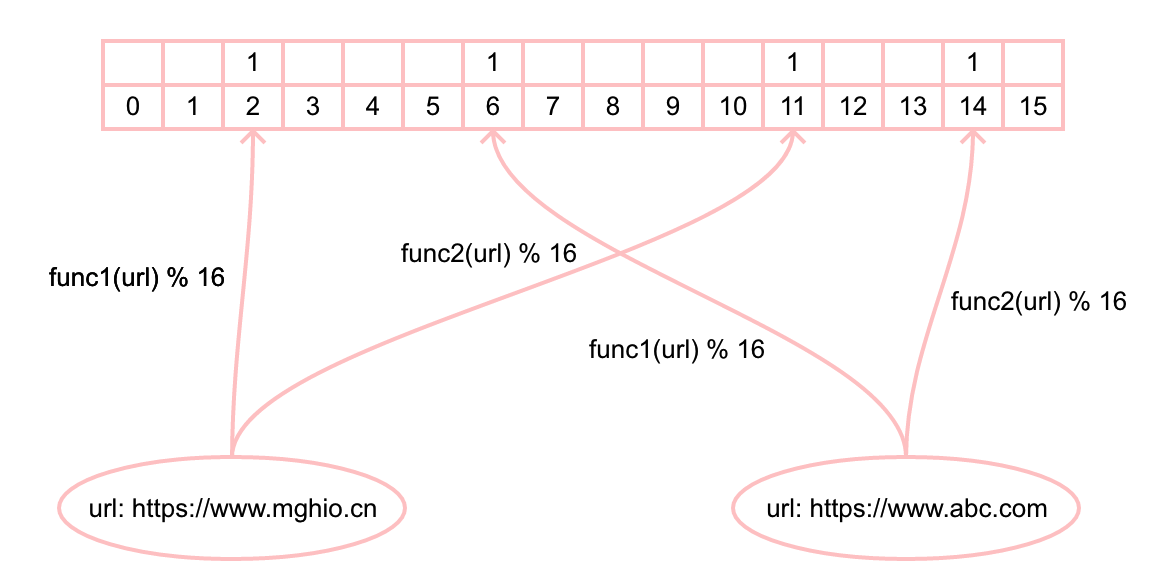
当我们往集合里添加一个元素的时候, 可以检查该元素在应用对应哈希函数后的哈希值对比特向量的长度取余后的位置是否为 1,图中用 1 表示最新添加的元素对应位置。然后当我们要判断添加元素是否存在集合中的话,只需要简单的通过对该元素应用同样的哈希函数,然后看比特向量里对应的位置是否为 1 的方式来判断一个元素是否在集合里。如果不是,则该元素一定不再集合中,但是需要注意的是,如果是,你只知道元素可能在里面, 因为这些对应位置有可能恰巧是由其它元素或者其它元素的组合所引起的。以上就是布隆过滤器的实现原理。
如何自己实现
布隆过滤器的思想比较简单,首先在构造方法中初始化了一个指定长度的 int 数组,在添加元素的时候通过哈希函数 func1 和 func2 计算出对应的哈希值,对数组长度取余后将对应位置置为 1,判断元素是否存在于集合中时,同样也是对元素用同样的哈希函数进行两次计算,取到对应位置的哈希值,只要存在位置的值为 0,则认为元素不存在。下面使用 Java 语言实现了上面示例中简单版的布隆过滤器:
public class BloomFilter {
/**
* 数组长度
*/
private int size;
/**
* 数组
*/
private int[] array;
public BloomFilter(int size) {
this.size = size;
this.array = new int[size];
}
/**
* 添加数据
*/
public void add(String item) {
int firstIndex = func1(item);
int secondIndex = func2(item);
array[firstIndex % size] = 1;
array[secondIndex % size] = 1;
}
/**
* 判断数据 item 是否存在集合中
*/
public boolean contains(String item) {
int firstIndex = func1(item);
int secondIndex = func2(item);
int firstValue = array[firstIndex % size];
int secondValue = array[secondIndex % size];
return firstValue != 0 && secondValue != 0;
}
/**
* hash 算法 func1
*/
private int func1(String key) {
int hash = 7;
hash += 61 * hash + key.hashCode();
hash ^= hash >> 15;
hash += hash << 3;
hash ^= hash >> 7;
hash += hash << 11;
return Math.abs(hash);
}
/**
* hash 算法 func2
*/
private int func2(String key) {
int hash = 7;
for (int i = 0, len = key.length(); i < len; i++) {
hash += key.charAt(i);
hash += (hash << 7);
hash ^= (hash >> 17);
hash += (hash << 5);
hash ^= (hash >> 13);
}
return Math.abs(hash);
}
}
自己实现虽然简单但是有一个问题就是检测的误判率比较高,通过其原理可以知道,可我们可以提高数组长度以及 hash 计算次数来降低误报率,但是相应的 CPU、内存的消耗也会相应的提高;这需要我们根据自己的业务需要去权衡选择。
扎心一问
哈希函数该如何设计?
布隆过滤器里的哈希函数最理想的情况就是需要尽量的彼此独立且均匀分布,同时,它们也需要尽可能的快 (虽然 sha1 之类的加密哈希算法被广泛应用,但是在这一点上考虑并不是一个很好的选择)。
布隆过滤器应该设计为多大?
个人认为布隆过滤器的一个比较好特性就是我们可以修改过滤器的错误率。一个大的过滤器会拥有比一个小的过滤器更低的错误率。假设在布隆过滤器里面有 k 个哈希函数,m 个比特位(也就是位数组长度),以及 n 个已插入元素,错误率会近似于 (1-ekn/m)k,所以你只需要先确定可能插入的数据集的容量大小 n,然后再调整 k 和 m 来为你的应用配置过滤器。
应该使用多少个哈希函数?
显然,布隆过滤器使用的哈希函数越多其运行速度就会越慢,但是如果哈希函数过少,又会遇到误判率高的问题。所以这个问题上需要认真考虑,在创建一个布隆过滤器的时候需要确定哈希函数的个数,也就是说你需要提前预估集合中元素的变动范围。然而你这样做了之后,你依然需要确定比特位个数和哈希函数的个数的值。看起来这似乎这是一个十分困难的优化问题,但幸运的是,对于给定的 m(比特位个数)和 n(集合元素个数),最优的 k(哈希函数个数)值为: (m/n)ln(2)(PS:需要了解具体的推导过程的朋友可以参考维基百科)。也就是我们可以通过以下步骤来确定布隆过滤器的哈希函数个数:
- 确定 n(集合元素个数)的变动范围。
- 选定 m(比特位个数)的值。
- 计算 k(哈希函数个数)的最优值
对于给定的 n、m 和 k 计算错误率,如果这个错误率不能接受的话,可以继续回到第二步。
布隆过滤器的时间复杂度和空间复杂度?
对于一个 m(比特位个数)和 k(哈希函数个数)值确定的布隆过滤器,添加和判断操作的时间复杂度都是 O(k),这意味着每次你想要插入一个元素或者查询一个元素是否在集合中,只需要使用 k 个哈希函数对该元素求值,然后将对应的比特位标记或者检查对应的比特位即可。
总结
布隆过滤器的实际应用很广泛,特别是那些要在大量数据中判断一个元素是否存在的场景。可以看到,布隆过滤器的算法原理比较简单,但要实际做一个生产级别的布隆过滤器还是很复杂的,谷歌的开源库 Guava 的 BloomFilter 提供了 Java 版的实现,用法很简单。最后留给大家一个问题:布隆过滤器支持元素删除吗?