| 这个作业属于哪个班级 | 数据结构--网络2011/2012 |
|---|---|
| 这个作业的地址 | DS博客作业04--图 |
| 这个作业的目标 | 学习图结构设计及相关算法 |
| 姓名 | 廖浩轩 |
0.PTA得分截图

1.本周学习总结
1.1图的存储结构
简简单单造个图
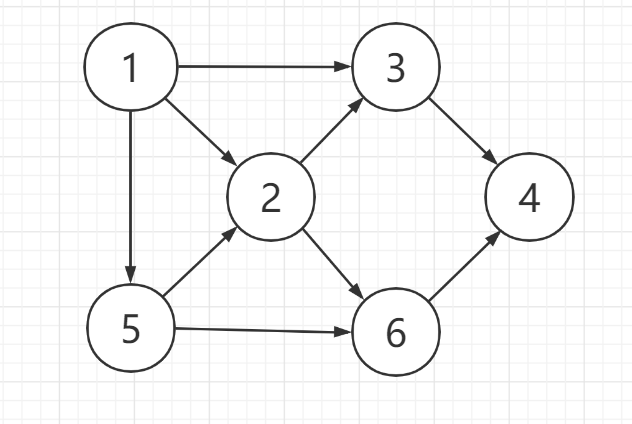
1.1.1 邻接矩阵
邻接矩阵
邻接矩阵的结构体定义
typedef struct //图的定义
{ int edges[MAXV][MAXV]; //邻接矩阵
int n,e; //顶点数,弧数
} MGraph; //图的邻接矩阵表示类型
建图函数
void CreateMGraph(MGraph& g, int n, int e)
{
int i, j, a, b;
for (i = 1; i <= n; i++) //矩阵初始化
for (j = 1; j <= n; j++)
g.edges[i][j] = 0; //无权图矩阵赋值0或1,有权图赋值0,∞,权
for (i = 0; i < e; i++) //输入边
{
cin >> a >> b;
g.edges[a][b] = 1;
g.edges[b][a] = 1; //无向图需要对称赋值
}
g.e = e;
g.n = n;
}
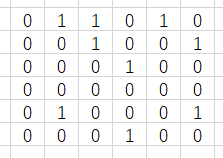
1.1.2 邻接表
邻接矩阵
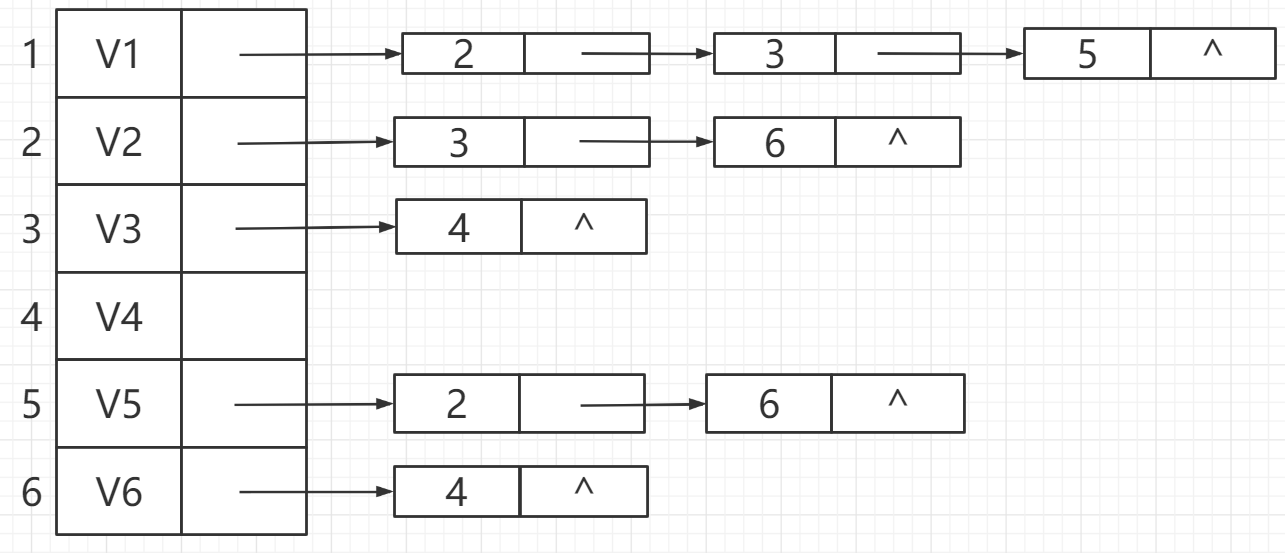
邻接矩阵的结构体定义
typedef struct ANode
{ int adjvex; //该边的终点编号
struct ANode *nextarc; //指向下一条边的指针
int info; //该边的相关信息,如权重
} ArcNode; //边表节点类型
typedef int Vertex;
typedef struct Vnode
{ Vertex data; //顶点信息
ArcNode *firstarc; //指向第一条边
} VNode; //邻接表头节点类型
typedef VNode AdjList[MAXV];
typedef struct
{ AdjList adjlist; //邻接表
int n,e; //图中顶点数n和边数e
} AdjGraph;
建图函数
void CreateAdj(AdjGraph*& G, int n, int e)
{
ArcNode* p, * q;
int i,a,b;
G = new AdjGraph;
for (i = 1; i <= n; i++)
{
G->adjlist[i].firstarc = NULL; //头结点初始化
}
for (i = 1; i <= e; i++)
{
cin >> a >> b; //输入边
/*无向图需要双向赋值*/
p = new ArcNode;
q = new ArcNode;
p->adjvex = b;
q->adjvex = a;
p->nextarc = G->adjlist[a].firstarc;
G->adjlist[a].firstarc = p;
q->nextarc = G->adjlist[b].firstarc;
G->adjlist[b].firstarc = q;
}
G->n = n;
G->e = e;
}
1.1.3 邻接矩阵和邻接表表示图的区别
邻接矩阵优缺点:
- 占用了太多的空间。试想,如果一个图有1000个顶点,其中只有10个顶点之间有关联(这种情况叫做稀疏图),却不得不建立一个1000X1000的二维数组,实在太浪费了。
- 简单直观,可以快速查到一个顶点和另一顶点之间的关联关系。
邻接表优缺点:
- 这种邻接表的存储方式,占用的空间比邻接矩阵要小得多。
- 在有向图中求顶点的度采用邻接矩阵比采用邻接表表示更方便
时间复杂度:
- 若采用邻接矩阵存储,时间复杂度为O(n^2);
- 若采用邻接链表存储,建立邻接表或逆邻接表时,
若输入的顶点信息即为顶点的编号,则时间复杂度为O(n+e);
若输入的顶点信息不是顶点的编号,需要通过查找才能得到顶点在图中的位置,则时间复杂度为O(n*e);
1.2 图遍历
1.2.1 深度优先遍历
深度优先遍历结果:1 2 3 4 6 5
深度遍历代码
邻接矩阵
void DFS(MGraph g, int v)//深度遍历
{
static int n = 0;
int j;
if (visited[v] == 0)
{
if (n == 0)
{
cout << v;
n++;
}
else
{
cout << " " << v;
n++;
}
visited[v] = 1;
}
for (j = 1; j <= g.n; j++)
{
if(g.edges[v][j]&&visited[j]==0)
DFS(g, j);
}
}
邻接表
void DFS(AdjGraph* G, int v)//v节点开始深度遍历
{
static int n = 0;
ArcNode* p;
visited[v] = 1;
if (!n)
{
cout << v;
n++;
}
else
{
cout << " " << v;
n++;
}
p = G->adjlist[v].firstarc;
while (p != NULL&&n<G->n)
{
if (visited[p->adjvex] == 0)DFS(G, p->adjvex);
p = p->nextarc;
}
}
深度遍历适用哪些问题的求解
- 全排列问题
- ABC+DEF=GHI问题
- 二维数组寻找点到点的最短路径
- 求岛屿的面积
- 求岛屿的个数
1.2.2 广度优先遍历
广度优先遍历结果: 1 2 3 5 6 4
广度遍历代码
邻接矩阵
void BFS(MGraph g, int v)
{
queue<int>q; //定义队列q
int i, j;
cout << v; //输出起始顶点
visited[v] = 1; //已访问顶点
q.push(v); //顶点加入队列
while (!q.empty()) //队列不空时循环
{
i = q.front(); //出队顶点i
q.pop();
for (j = 1; j <= g.n; j++)
{
if (g.edges[i][j] && !visited[j]) //顶点i的邻接点入队并输出
{
cout << " " << j;
visited[j] = 1;
q.push(j);
}
}
}
}
邻接表
void BFS(AdjGraph* G, int v)
{
queue<int>q; //定义队列q
ArcNode* p;
int d;
cout << v; //输出起始顶点
visited[v] = 1; //已访问顶点
q.push(v); //顶点加入队列
while (!q.empty()) //队列不空时循环
{
d = q.front(); //出队顶点d
q.pop();
p = G->adjlist[d].firstarc; //顶点d的边结点
while (p)
{
if (visited[p->adjvex] == 0) //每个边结点入队并输出
{
cout << " " << p->adjvex;
visited[p->adjvex] = 1;
q.push(p->adjvex);
}
p = p->nextarc;
}
}
}
广度遍历适用哪些问题的求解
- 最短路径
- 最远顶点
- 组成整数的最小平方数数量
- 最短单词路径
1.3 最小生成树
- 对于带权连通图,n个顶点,n-1条边
- 根据DFS或BFS生成的树
- 其中权值之和最小的生成树称为最小生成树,生成的树可能不一样,但权值相同
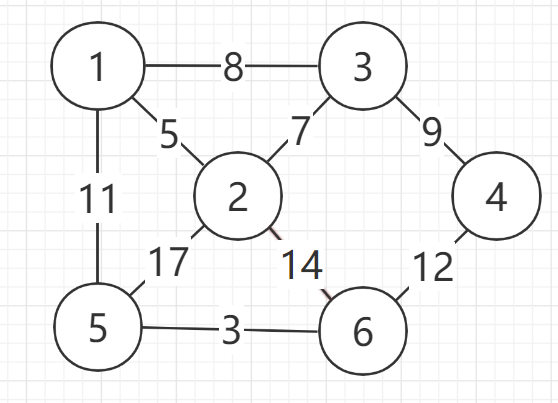
1.3.1 Prim算法求最小生成树
Prim算法得最小生成树

Prim算法代码
void prim(MGraph g, int v)
{
int lowcost[MAXV], min, i, j, k = 0;
int closest[MAXV];
int sum = 0;
for(i = 1; i <= g.n; i++) //给数组lowcost[]和closest[]置初值
{
lowcost[i] = g.edges[v][i];
closest[i] = v;
}
lowcost[v] = 0; //顶点v已经加入树中
for (i = 1; i < g.n; i++) //找出(n-1)个顶点
{
min = 10000;
k = 0;
for (j = 1; j <= g.n; j++) //找出离树中节点最近的顶点k
{
if (lowcost[j] != 0 && lowcost[j] < min)
{
min = lowcost[j];
k = j; //k记录最近顶点的编号
}
}
if (k == 0) //不是连通图
{
cout << "-1" << endl;
return;
}
sum += min; //变量sum存储最小生成树中边的权值
lowcost[k] = 0; //顶点k已经加入树中
for (j = 1; j <= g.n; j++)
{
if (lowcost[j] != 0 && g.edges[k][j] < lowcost[j])
{
lowcost[j] = g.edges[k][j];
closest[j] = k;
}
}
}
cout << sum << endl;
}
- 普里姆算法:构造的生成树不一定唯一,但最小生成树的权值之和一定相同。普里姆算法的时间复杂度为O(n2)。由于它只与顶点的个数n有关,所以普里姆算法适合于稠密图,图的存储结构为邻接矩阵
1.3.2 Kruskal算法求解最小生成树
Kruskal算法得最小生成树
Kruskal算法代码
typedef struct {
int u; //边的起始顶点
int v; //边的终止顶点
int w; //边的权值
}Edge;
//改进的克鲁斯卡尔算法(使用了堆排序,并查集)
void Kruskal(AdjGraph* g)
{
int i,j,k,u1,v1,sn1,sn2;
UFSTree t[MAXSize]; //并查集,树结构
ArcNode* p;
Edge E[MAXSize];
k=1; // E数组的下标从1开始计
for(i = 0; i < g.n; i++)
{
p=g->adjlist[i].firstarc;
while(p!=NULL)
{
E[k].u=i;
E[k].v=p->adjvex;
E[k].w=p->weight;
k++;
p=p->nextarc;
}
}
HeapSort(E,g.e); //采用堆排序对E数组按权值递增排序
MAKE_SET(t,g.n); //初始化并查集树t
k=1; //k表示当前构造生成树的第几条边,初值为1
j=1; //E中边的下标,初值为1
while(k<g.n) //生成的边数为n-1
{
u1=E[j].u;
v1=E[j].v; //取一条边的头尾顶点编号u1和v1
sn1=FIND_SET(t,u1);
sn2=FIND_SET(t,v1); //分别得到两个顶点所属的集合编号
if(sn1!=sn2) //两顶点属不同集合
{
k++; //生成边数增1
UNION(t, u1, v1); //将u1和v1两个顶点合并
}
j++; //下一条边
}
}
- 克鲁斯卡尔算法:按权值的递增顺序选择合适的边来构造最小生成树,选取的边不能使生成树形成回路。克鲁斯卡尔算法的时间复杂度为O(elog2e)。由于它只与边的条数e有关,所以克鲁斯卡尔算法适合于稀疏图,图的存储结构为邻接表
1.4 最短路径
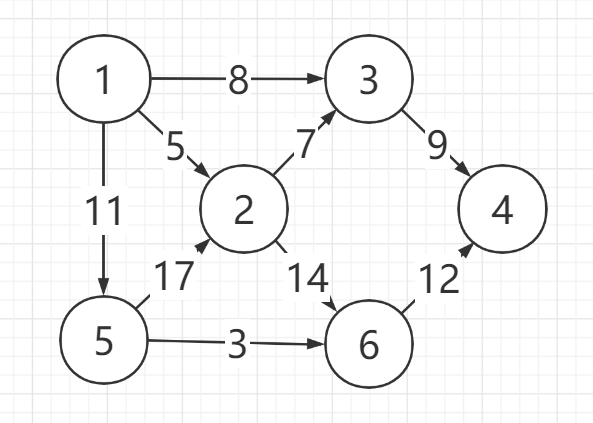
1.4.1 Dijkstra算法求解最短路径
Dijkstra算法代码
#define INF 32767
void Dijkstra(MatGraph g, int v)
{
int dist[MAXV], path[MAXV];
int s[MAXV];
int mindis ,i,j,u;
for(i=0; i<g.n; i++)
{
dist[i] = g.edges[v][i]; //距离初始化
s[i] = 0; //s[]置空
if(g.edges[v][i] < INF) //路径初始化
{
path[i] = v; //顶点v到i有边时
}
else
{
path[i] = -1; //顶点v到i没边时
}
}
s[v] = 1;
for(i=0;i<g.n;i++)
{
mindis = INF;
for(j=0;j<g.n;j++) //找最小路径长度顶点u
{
if(s[j] == 0&&dist[j] < mindis)
{
u=j;
mindis=dist[j];
}
}
s[u]=1;
for(j = 0;j < g.n;j++)
{
if(s[j]==0)
{
if(g.edges[u][j] < INF&&dist[u] + g.edges[u][j] < dist[j])
{
dist[j] = dist[u] + g.edges[u][j];
path[j]=u;
}
}
}
}
}
- 迪杰斯特拉算法:用于求一顶点到其余各顶点的最短路径,其中最短路径中的所有顶点都是最短路径。迪杰斯特拉算法的时间复杂度为O(n2)。由于它只与顶点的个数n有关,所以普里姆算法适合于稠密图,图的存储结构为邻接矩阵
1.4.2 Floyd算法求解最短路径
算法过程:
从任意一条单边路径开始。所有两点之间的距离是边的权,如果两点之间没有边相连,则权为无穷大。
对于每一对顶点 u 和 v,看看是否存在一个顶点 w 使得从 u 到 w 再到 v 比已知的路径更短。如果是更新它。
把图用邻接矩阵G表示出来,如果从Vi到Vj有路可达,则G[i][j]=d,d表示该路的长度;否则G[i][j]=无穷大。定义一个矩阵D用来记录所插入点的信息,D[i][j]表示从Vi到Vj需要经过的点,初始化D[i][j]=j。把各个顶点插入图中,比较插点后的距离与原来的距离,G[i][j] = min( G[i][j], G[i][k]+G[k][j] ),如果G[i][j]的值变小,则D[i][j]=k。在G中包含有两点之间最短道路的信息,而在D中则包含了最短通路径的信息。
比如,要寻找从V5到V1的路径。根据D,假如D(5,1)=3则说明从V5到V1经过V3,路径为{V5,V3,V1},如果D(5,3)=3,说明V5与V3直接相连,如果D(3,1)=1,说明V3与V1直接相连。 [4]
算法优缺点:
优点:容易理解,可以算出任意两个节点之间的最短距离,代码编写简单。
缺点:时间复杂度比较高,不适合计算大量数据。
算法代码
#include<stdio.h>
#include<stdlib.h>
#define max 1000000000
int d[1000][1000],path[1000][1000];
int main()
{
int i,j,k,m,n;
int x,y,z;
scanf("%d%d",&n,&m);
for(i=1;i<=n;i++)
for(j=1;j<=n;j++){
d[i][j]=max;
path[i][j]=j;
}
for(i=1;i<=m;i++) {
scanf("%d%d%d",&x,&y,&z);
d[x][y]=z;
d[y][x]=z;
}
for(k=1;k<=n;k++)
for(i=1;i<=n;i++)
for(j=1;j<=n;j++) {
if(d[i][k]+d[k][j]<d[i][j]) {
d[i][j]=d[i][k]+d[k][j];
path[i][j]=path[i][k];
}
}
for(i=1;i<=n;i++)
for(j=1;j<=i;j++)
if (i!=j) printf("%d->%d:%d
",i,j,d[i][j]);
int f, en;
scanf("%d%d",&f,&en);
while (f!=en) {
printf("%d->",f);
f=path[f][en];
}
printf("%d
",en);
return 0;
}
求最短路径的其他算法
- 深度或广度优先搜索算法:从起点开始访问所有深度遍历路径或广度优先路径,则到达终点节点的路径有多条,取其中路径权值最短的一条则为最短路径。
#include<bits/stdc++.h>
using namespace std;
#define nmax 110
#define inf 999999999
int minpath,n,m,en,edge[nmax][nmax],mark[nmax];//最短路径,节点数,边数,终点,邻接矩阵,节点访问标记
void dfs(int cur,int dst){
if(minpath<dst) return;//当前走过的路径大雨之前的最短路径,没有必要再走下去了
if(cur==en){//临界条件,当走到终点n
if(minpath>dst){
minpath=dst;
return;
}
}
for(int i=1;i<=n;i++){
if(mark[i]==0&&edge[cur][i]!=inf&&edge[cur][i]!=0){
mark[i]=1;
dfs(i,dst+edge[cur][i]);
mark[i]=0;//需要在深度遍历返回时将访问标志置0
}
}
return;
}
int main ()
{
while(cin>>n>>m&&n!=0){
//初始化邻接矩阵
for(int i=1;i<=n;i++){
for(int j=1;j<=n;j++){
edge[i][j]=inf;
}
edge[i][i]=0;
}
int a,b;
while(m--){
cin>>a>>b;
cin>>edge[a][b];
}
minpath=inf;
memset(mark,0,sizeof(mark));
mark[1]=1;
en=n;
dfs(1,0);
cout<<minpath<<endl;
}
}
- Bellman-Ford算法:所有的边进行n-1轮松弛,因为在一个含有n个顶点的图中,任意两点之间的最短路径最多包含n-1条边。
#include<bits/stdc++.h>
using namespace std;
#define nmax 1001
#define inf 999999999
int n,m,s[nmax],e[nmax],w[nmax],dst[nmax];
int main ()
{
while(cin>>n>>m&&n!=0&&m!=0){
for(int i=1;i<=m;i++){
cin>>s[i]>>e[i]>>w[i];
}
for(int i=1;i<=n;i++)
dst[i]=inf;
dst[1]=0;
for(int i=1;i<=n-1;i++){
for(int j=1;j<=m;j++){
if(dst[e[j]]>dst[s[j]]+w[j]){
dst[e[j]]=dst[s[j]]+w[j];
}
}
}
int flag=0;
for(int i=1;i<=m;i++){
if(dst[e[i]]>dst[s[i]]+w[i]){
flag=1;
}
}
if(flag) cout<<"此图有负权回路"<<endl;
else{
for(int i=1;i<=n;i++){
if(i==1) cout<<dst[i];
else cout<<' '<<dst[i];
}
cout<<endl;
}
}
}
- SPFA(Shortest Path Faster Algorithm)算法:建立一个队列,初始时队列里只有起始点s,在建立一个数组记录起始点s到所有点的最短路径(初始值都要赋为极大值,该点到他本身的路径赋为0)。
#include<bits/stdc++.h>
using namespace std;
int n,m,len;
struct egde{
int to,val,next;
}e[200100];
int head[200100],vis[200100],dis[200100];
void add(int from,int to,int val){
e[len].to=to;
e[len].val=val;
e[len].next=head[from];
head[from]=len;
len++;
}
void spfa()
{
queue<int>q;
q.push(1);
vis[1]=1;
while(!q.empty())
{
int t=q.front();
q.pop();
vis[t]=0;
for(int i=head[t];i!=-1;i=e[i].next){
int s=e[i].to;
if(dis[s]>dis[t]+e[i].val){
dis[s]=dis[t]+e[i].val;
if(vis[s]==0){
q.push(s);
vis[s]=1;
}
}
}
}
}
int main(){
int from,to,val;
while(cin>>n>>m){
memset(head,-1,sizeof(head));
memset(vis,0,sizeof(vis));
/* for(int i=1;i<=n;i++){
dis[i]=99999999;
}*/
memset(dis,0x3f,sizeof(dis));
dis[1]=0;len=1;
for(int i=0;i<m;i++){
cin>>from>>to>>val;
add(from,to,val);
}
spfa();
for(int i=1;i<=n;i++){
cout<<dis[i]<<" ";
}
cout<<endl;
}
}
1.5 拓扑排序
拓扑排序:在一个有向无环图中找一个拓扑序列的过程称为拓扑排序,有向无环图(DAG)才有拓扑排序,所以拓扑排序可以用来检测图中是否有回路
条件:每个顶点出现且只出现一次;若存在一条从顶点A到顶点B的路径,那么在序列中顶点A出现在顶点B的前面
过程:1.从有向图中选取一个没有前驱的顶点,并输出;2.从有向图中删去此顶点以及所有以它为尾的弧;3.重复上述两步,直至图为空,或者图不空但找不到无前驱的顶点为止
示例
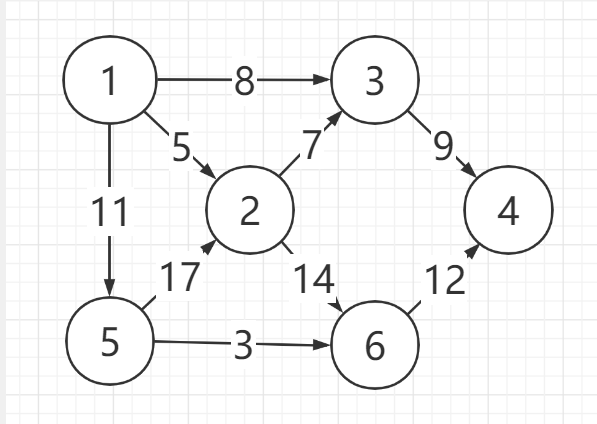
所得拓扑序列:152364,152634
算法代码
#define MAXV 20
typedef struct { //表头节点类型
int data; //顶点信息
int count; //存放顶点入度
ArcNode* firstarc; //指向第一条弧
}VNode;
void TopSort(AdjGraph* G) //拓扑排序算法
{
int i, j;
int St[MAXV], top = -1; //栈St的指针为top
ArcNode* p;
for (i = 0; i < G.n; i++) //入度置初值为0
{
G->adjlist[i].count = 0;
}
for (i = 0; i < G.n; i++) //求所有顶点的入度
{
p = G->adjlist[i].firstarc;
while (p != NULL)
{
G->adjlist[p->adjvex].count++;
p = p->nextarc;
}
}
for (i = 0; i < G.n; i++) //将入度为0的顶点进栈
{
if (G->adjlist[i].count == 0)
{
top++;
St[top] = i;
}
}
while (top > -1) //栈不空循环
{
i = St[top]; //出栈一个顶点i
top--;
printf("%d ", i);
p = G->adjlist[i].firstarc; //找第一个邻接点
while (p != NULL) //将顶点i的出边邻接点的入度减1
{
j = p->adjvex;
G->adjlist[j].count--;
if (G->adjlist[j].count == 0) //入度为0的邻接点进栈
{
top++;
St[top] = j;
}
p = p->nextarc;
}
}
}
1.6 关键路径
AOE网:在现代化管理中,人们常用有向图来描述和分析一项工程的计划和实施过程,一个工程常被分为多个小的子工程,这些子工程被称为活动(Activity),在带权有向图中若以顶点表示事件,有向边表示活动,边上的权值表示该活动持续的时间,这样的图简称为AOE网。
关键路径:从有向图的源点到汇点的最长路径,关键路径中的边称为关键活动,顶点称为事件
- 求关键路径步骤
1.对有向图拓扑排序
2.根据拓扑序列计算事件(顶点)的ve,vl数组。注意:ve和vl相同,只能找出关键路径上的点,而仅通过一个点的集合无法获得组成关键路径的边的集合
3.计算关键活动的e[],l[]。即边的最早、最迟时间
4.找e=l边即为关键活动
5.关键活动连接起来就是关键路径
2.PTA实验作业
2.1 图着色问题
2.1.1 伪代码
定义全局变量,n,e,colornum分别代表顶点,边数,和颜色数量
定义int型的set容器变量s,二维数组型的vector变量vec,定义数组book,为存放颜色方案的数组
输入n,e,colornum
输入两个端点,放进vec数组中
输入N,代表N个方案
while(N--) do
s.clear();//对每个方案的s里的数据都清除
初始化book数组为0
for i=1 to n do
输入num
book[i]=num//book数组存放每个颜色
将num放入set容器s中
end for
if(s.size()!=colornum)//即输入的颜色数量与一开始输入的所给的颜色数量不一样
输出No,继续判断下一个颜色方案
for i=1 to n do
for j=0 to vec[i].size()-1
如果book[i]与book[vec[i][j]]相等//即相邻的端点颜色一样
输出No,继续判断下一个颜色方案
end for
输出Yes//即没有上面的情况
end while
2.1.2 提交列表
2.1.3 本题知识点
因为颜色的数目是固定并且可能有重复的的,所以可以使用set容器,去掉相同的数
用vector容器的二维数组将每个顶点连接的顶点储存起来
用book数组存放颜色方案里的每个顶点所对应的颜色,用for循环遍历对比和该顶点相邻的顶点颜色是否一样
Q1:这题疯狂试探,总是部分正确,一开始是最小图错误,不是很理解最小图是指什么
A1:然后将数组的下标改了从0开始,就出现了其它的错误
A2:后来又去回顾代码,发现我的judge函数里没有写返回true,只有返回false
2.2 村村通
2.2.1 伪代码
定义count=0,输入城镇数量citynum,以及道路数量roads
初始化辅助数组f
输入两个端点x,y和所需的费用cost
用sort对结构体进行排序
for i=0 to roads
如果x,y不是同一个集合
把最小边加到总花费sum里面
count++
end for
如果 count==citynum-1
输出sum
否则输出-1
2.2.2 提交列表
2.2.3 本题知识点
这题相当于求最小生成树
用的是克鲁斯卡尔算法,并且采用了并查集直接进行通量的合并,以及库函数sort根据道路的价格cost进行排序
判断是否能通路,可以根据最小树的特点,边数为端点数-1
Q1:这题上机考的题集里也有出现,就是求最小生成树,考试时并没有写出来,老师提示用最短路径的代码然后加上prim算法就可以了
A1:但是我连prim算法都不会敲(那会还不会),于是就没写了
A2:后来看书写代码,用的是克鲁斯卡尔算法基本上是看书的,然后并查集不是很懂就上百度了
A3:最后还是没有完全正确,调试几次应该就可以全对,为了赶博客就先这样了