一:学习内容
- 字符串运算
- 字符串函数-strip()
- 字符串函数-大小写互换
- 字符串函数-字符串对齐
- 字符串函数-搜索
- 字符串函数-替换
- 字符串函数-split切割
- 字符串函数-连接join
- 字符串函数-统计count
- 字符串函数-字符串映射
- 字符串函数-测试字符串
二:字符串运算
1. +加,拼接
a='a'
b='b'
print a+b

2. *星号,重复输出字符串
print '*'*20

3. [],通过索引输出字符串
a='dsafdsaf'
a[3]

4. [:],截取字符串
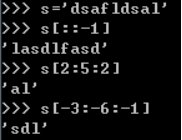
s='dsafldsal'
s[::-1] #逆序输出
s[2:5:2] #输出索引位置为2到索引位置为5的数据,不包括位置3,且步长为2,即输出索引位置为2,4的数据即s[2],s[4]
s[-3:-6:-1] #输出索引位置为-3到索引位置为-6的数据,不包括位置-6,步长为-1,s字符串最右边的位置索引为-1,往右为-2,-3..,即输出字符串从右往左位置第3位到第5位的数据
s='abcdefghijk'
s[::2] #偶数
s[1::2] #奇数
s[::-1] #逆序输出
s[:] #全部输出
s[::3] #步长为3
s[-1:-6:-1] #取倒数第一个到第5个

5. in、not in,成员运费符包括、不包括
'a' in 'dsalla'
'c' in 'dlsaa'
'c' not in 'dsalla'

6. r、R-原始字符串
print r'\'
print R'\'

7. %-格式化字符串
%s为字符串
%d为数字
%c为char,只能为一个字符
%f为float,为浮点型
print 'i am %s' % 'yml'
print 'i am %s,my age is %d' % ('yml',25)

print 'i have %.2f apple' % 7.9 #保留两位小数
print 'it is %c' % '0'

print 'i have %x apple' % 16
print 'i have %o apple' % 16

print 'i have %c apple' % '1' #%c格式化字符及其ASCII码
print 'i have %5s apple' % 45 #%s格式化字符串
print 'i have %2d apple' % 3 #%d格式化整数
print 'i have %u apple' % 3 #%u格式化无符号整型
print 'i have %o apple' % 15 #%o格式化无符号八进制数
print 'i have %x apple' % 15 #%x格式化无符号十六进制数
print 'i have %.2f apple' % 15 #%f格式化浮点数,可指定小数点后的位数默认6位
print 'i have %e apple' % 15 #%e用科学技术法格式化浮点数
print 'i have %E apple' % 15 #%E用科学技术法格式化浮点数
print 'i have %g apple' % 15 #%f和%e的简写

三:字符串函数-strip()函数
1. strip()-去掉首尾不可见字符
将前后包含的空格和不可见字符去掉
可以看到不仅去掉了空格还去掉了tab、 、 、 等不可见字符


data=raw_input('请输入一个字符串:')
data
print data
print data.strip()

输入: fda das ,输出的效果就是去不掉 等不可见字符
后来发现,raw_input输入进来的 等不可见字符存在内存中会自动加上来避免转义,我之前用print所以看不见那个多出来的

这点需要注意。
2. lstrip()-去掉左侧不可见字符
' a b '.lstrip()

3. rstrip()-去掉右侧不可见字符
' a b '.rstrip()

3. strip('')-去掉首尾中指定字符
'*badsafd5'.strip('*')

四:字符串函数-大小写互换
1. lower()-将字符串大写转小写
'ABdd'.lower()

2. upper()-将字符串小写转大写
'ABdd'.upper()

3. swapcase()-将字符串小写转大写,大写转小写
'ABdd'.swapcase()

4. capitalize()-将字符串第一个字母变大写
'abcded'.capitalize()
'i am girl'.capitalize()

5. capwords()-将字符串每个单词的首字母变大写
import string
string.capwords('i am a girl')

6. title()-将字符串每个单词的首字母变大写,类似上面的capwords
'i am girl'.title()
'I am girl'.title()

五:字符串函数-字符串对齐
1. ljust(length,[s])-左对齐补齐字符串达到length的长度,不写s默认用空补充,如果字符串本身的长度比length要长,则默认全部输出字符串
'abc'.ljust(10)
'abc'.ljust(10,'*')

'abcsalfdsafdsfdsa'.ljust(3)

2. rjust(length,[s])-右对齐补齐字符串达到length的长度,不写s默认用空补充,如果字符串本身的长度比length要长,则默认全部输出字符串
'abc'.rjust(5)
'abc'.rjust(5,'#')

'abcsalfdsafdsfdsa'.rjust(3)

3. center(length,[s])- 居中对齐补齐字符串达到length的长度,不写s默认用空补充,如果字符串本身的长度比length要长,则默认全部输出字符串
'abc'.center(10)
'abc'.center(10,'*')
'abcedfds'.center(5,'*')
'abcedfds'.center(5)

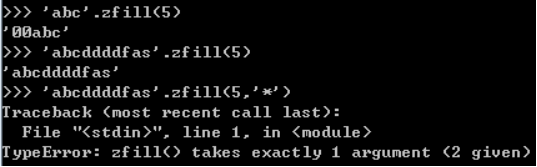
4. zfill(length)-只能填充0,参数只有一个,而且是前面补0,如果字符串本身长度比length长,则默认输出全部字符串
'abc'.zfill(5)
'abcddddfas'.zfill(5)
'abcddddfas'.zfill(5,'*') #此法不可取,zfill只能补0不能指定字符进行补充
六:字符串函数-搜索
1. find(s,[start,end])-从字符串中找s的索引位置,start和end代表寻找区间,为闭开区间,找到则返回索引位置,找不到返回-1
a='test learn'
a.find('learn')
a.find('ea',5)
a.find('ea',5,10)
a.find('te',0,15)
a.find('xx',0,15)

* 小练习-在字符串找到所有满足的字符串
lis=[]
def find_str(s,f):
temp =0
while f in s:
index = s.find(f)
lis.append(index+temp)
s = s[:index] + s[index+len(f):]
temp+=2
return lis
s='iamymlamtezamamamster'
f='am'
print find_str(s,f)
运行结果:在s中找到f字符串的位置

2. index(s,[start,end])-可在指定字符串范围内查找字符串出现的位置,找不到返回错误
a='abcdefsg'
a.index('de')
a.index('de',1,45)

3. rfind(s,[start,end])-可在指定字符串范围内从右边开始查找字符串出现的位置,找不到返回-1,如果查找的字符串有多个,则会找到从右边开始第一出现的位置
a='abcdefsg'
a.rfind('g')
a.rfind('j',0)
a.rfind('e',1,6)

a=’iamymlamlearning’
a.find(‘am’)
a.rfind(‘am’)


find是从左边开始找发现am的位置为1,而rfind是从右边开始找,位置为6
七:字符串函数-替换
1. replace(old,new,count)-从字符串中old替换成new,count为替换次数,不写默认全部替换
a='iamymlamleanring'
a.replace('am','*') #全部替换
a.replace('am','*',1) #指定替换次数
import string
string.replace(a,'am','*') #string中的replace方法

2. expandtabs([tabsize])-将字符串中每个tab替换成指定tabsize的空格数量,tabsize不写默认为8个-此函数一般不用很少用,了解即可
s='a bc'
s.expandtabs()
s.expandtabs(1)
s.expandtabs(3)
s.expandtabs(2)

八:字符串函数-split切割
1. split (s,count)-将字符串以s进行切割,count为切割次数,不写默认全部切割
a.split('am')
a.split('am',1)
a.split('am',2)

* 输出一个字符串的单词个数
#encoding=utf-8
def count_string(s):
s=s.replace(","," ").replace('!',' ')
b=s.split()
return len(b)
s='I am a boy,and handsome!'
print count_string(s)

法二:
len("i am a boy,and handsom !".replace(","," ").replace("!","").split())

2. rsplit (s,count)-将字符串从右边以s进行切割,count为切割次数,不写默认全部切割
a='iamymliamlearing'
a.rsplit('am',1)
a.rsplit('am')

3. splitlines ([bool])-按照分隔符分隔字符串bool默认为false
a='1 2 '
print a.splitlines()
print a.splitlines(False)
print a.splitlines(True)
print a.splitlines(1)

* 统计文件有多少行内容,多少字符
#encoding=utf-8
with open("C:\Users\yumeiling\Desktop\a.txt") as fp:
content=fp.read()
print u'行数:',len(content.splitlines()) #文件有多少行
print u'个数:',len("".join(content.splitlines())) #文件有多少个字母

九:字符串函数-连接join()、统计count()
1. rule.join(list):按rule来连接list ,要求list中每项要为字符串
a=['4','s','ds']
''.join(a)
'','.join(a)
'+'.join(a)

2. count(s):统计字符串中s出现的次数
'abcab'.count('a')
'abcab'.count('ab')
'abcab'.count('abc')

九:字符串函数-字符串映射
1. translate (rule,[delstr]):将字符串按rule规则进行映射,并且可用删除delstr字符串,默认delstr为空即不删除,先删除后rule
import string
s=string.maketrans('abc','def')
'iamabcgh'.translate(s)
'abcabcabc'.translate(s)

将a映射成d,将b映射成e,将c映射成f
import string
rule=string.maketrans('abc','def')
'iamymliamlearingabc'.translate(s,'am') #删除字符串中的所有‘am’字符

2. str和string的区别
str是类型,string是模块,python3以后就没有string了,因为3中都是unicode了。
十:字符串函数-字符串解码和编码
1. encode()编码,decode()解码
str = "this is string example....wow!!!";
str = str.encode('base64','strict');
print "Encoded String: " + str;
print "Decoded String: " + str.decode('base64','strict')

十一:字符串函数-测试字符串
1. startswith(s):判断字符串是否以s开头
a='iamymliamlearing'
a.startswith('i')
a.startswith('b')

2. endswith(s):判断字符串是否以s结尾
a='iamymliamlearing'
a.endswith('b')
a.endswith('g')

3. isalnum ():判断是否为字母或数字,是返回True,否返回False,且至少有一个字符
'abc2'.isalnum()
'abcd'.isalnum()

4. isalpha (s):判断s是否为字母,是返回True,否返回False,且至少有一个字母
'abcd'.isalpha()
'abc3'.isalpha()

5. isdigit ():判断s是否为数字,是返回True,否返回False
'abc2'.isdigit()
'442'.isdigit()

6. isspace ():判断是否为空格,是返回True,否返回False,不可见字符也会返回True
'abc3 '.isspace()
' '.isspace()
' '.isspace()
' '.isspace()

7. islower ():判断是否为小写,是返回True,否返回False,字符串中有数字不影响结果
'abc'.islower()
'abC'.islower()

8. isupper ():判断是否为大写,是返回True,否返回False,字符串中有数字不影响结果
'abC'.isupper()
'ABC'.isupper()
'ABC1234'.isupper()

9. istitle ():判断每个单次的首字母是否为大写,是返回True,否返回False
'I Am Is Yml23'.istitle()
'I Am Is yml23'.istitle()
