实验九 简单文本入门
一、常用的文本处理命令
二、文本处理命令
1.tr 命令
tr 命令可以用来删除一段文本信息中的某些文字。或者将其进行转换。
使用方式:
tr [option]...SET1 [SET2]
常用的选项有:
| 选项 | 说明 |
|---|---|
-d |
删除和set1匹配的字符,注意不是全词匹配也不是按字符顺序匹配 |
-s |
去除set1指定的在输入文本中连续并重复的字符 |
操作举例:
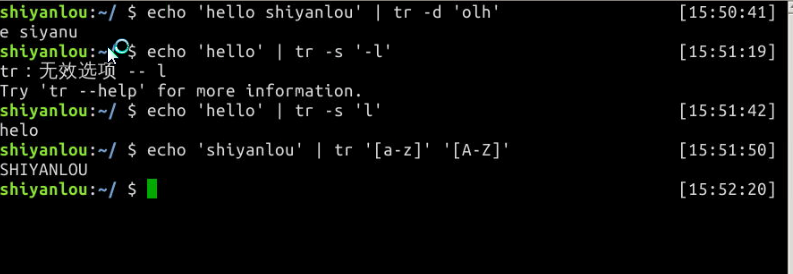
# 删除 "hello shiyanlou" 中所有的'o','l','h'
$ echo 'hello shiyanlou' | tr -d 'olh'
# 将"hello" 中的ll,去重为一个l
$ echo 'hello' | tr -s 'l'
# 将输入文本,全部转换为大写或小写输出
$ cat /etc/passwd | tr '[:lower:]' '[:upper:]'
# 上面的'[:lower:]' '[:upper:]'你也可以简单的写作'[a-z]' '[A-Z]',当然反过来将大写变小写也是可以的
2.col 命令
col 命令可以将Tab换成对等数量的空格建,或反转这个操作。
使用方式:
col [option]
常用的选项有:
| 选项 | 说明 |
|---|---|
-x |
将Tab转换为空格 |
-h |
将空格转换为Tab(默认选项) |
操作举例:
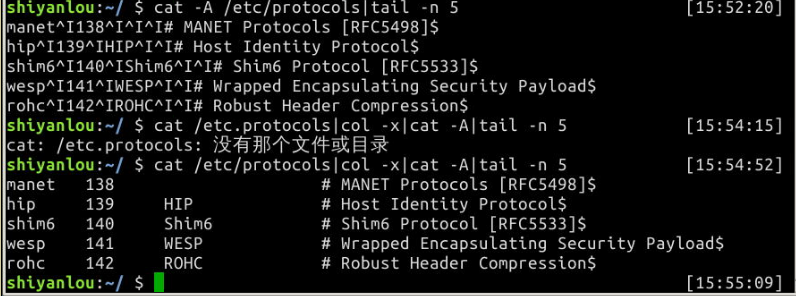
# 查看 /etc/protocols 中的不可见字符,可以看到很多 ^I ,这其实就是 Tab 转义成可见字符的符号
$ cat -A /etc/protocols
# 使用 col -x 将 /etc/protocols 中的 Tab 转换为空格,然后再使用 cat 查看,你发现 ^I 不见了
$ cat /etc/protocols | col -x | cat -A
3.join命令
学过数据库的用户对这个应该不会陌生,这个命令就是用于将两个文件中包含相同内容的那一行合并在一起。
使用方式: join [option]... file1 file2
常用的选项有:
| 选项 | 说明 |
|---|---|
-t |
指定分隔符,默认为空格 |
-i |
忽略大小写的差异 |
-1 |
指明第一个文件要用哪个字段来对比,,默认对比第一个字段 |
-2 |
指明第二个文件要用哪个字段来对比,,默认对比第一个字段 |
操作举例:
# 创建两个文件
$ echo '1 hello' > file1
$ echo '1 shiyanlou' > file2
$ join file1 file2
# 将/etc/passwd与/etc/shadow两个文件合并,指定以':'作为分隔符
$ sudo join -t':' /etc/passwd /etc/shadow
# 将/etc/passwd与/etc/group两个文件合并,指定以':'作为分隔符, 分别比对第4和第3个字段
$ sudo join -t':' -1 4 /etc/passwd -2 3 /etc/group

4.paste命令
paste这个命令与join 命令类似,它是在不对比数据的情况下,简单地将多个文件合并一起,以Tab隔开。
使用方式: paste [option] file...
常用的选项有:
| 选项 | 说明 |
|---|---|
-d |
指定合并的分隔符,默认为Tab |
-s |
不合并到一行,每个文件为一行 |
操作举例:
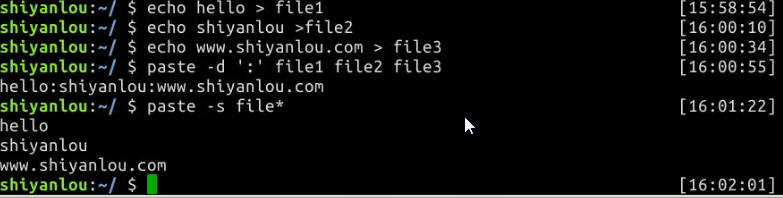
$ echo hello > file1
$ echo shiyanlou > file2
$ echo www.shiyanlou.com > file3
$ paste -d ':' file1 file2 file3
$ paste -s file1 file2 file3
作业:
小霸王!

实验十 数据流重定向
1.简单的重定向
文件描述符 设备文件 说明
0 /dev/stdin 标准输入
1 /dev/stdout 标准输出
2 /dev/stderr 标准错误
| 文件描述符 | 设备文件 | 说明 |
|---|---|---|
0 |
/dev/stdin |
标准输入 |
1 |
/dev/stdout |
标准输出 |
2 |
/dev/stderr |
标准错误 |
文件描述符:文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开。但是文件描述符这一概念往往只适用于 UNIX、Linux 这样的操作系统。
使用这些文件描述符:
默认使用终端的标准输入作为命令的输入和标准输出作为命令的输出
$ cat
(按Ctrl+C退出)
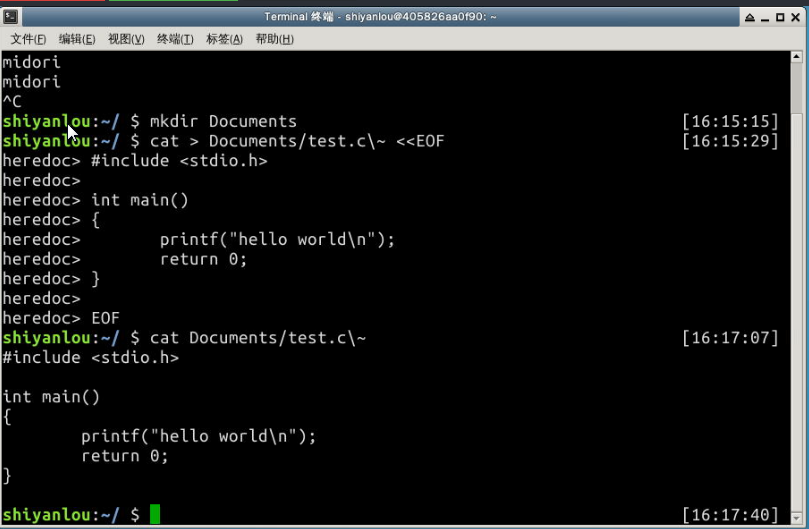
将cat的连续输出(heredoc方式)重定向到一个文件
$ mkdir Documents
$ cat > Documents/test.c~ <<EOF
#include <stdio.h>
int main()
{
printf("hello world
");
return 0;
}
EOF
将一个文件作为命令的输入,标准输出作为命令的输出
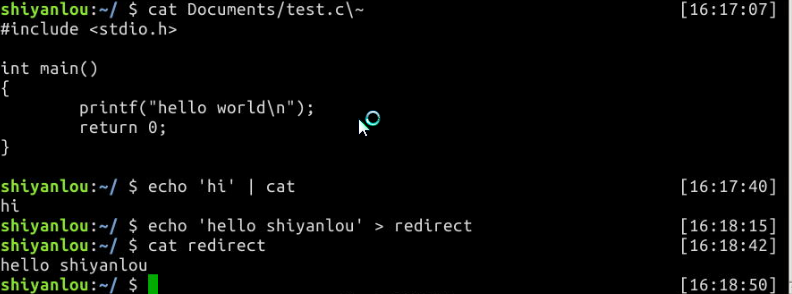
$ cat Documents/test.c~
将echo命令通过管道传过来的数据作为cat命令的输入,将标准输出作为命令的输出
$ echo 'hi' | cat
将echo命令的输出从默认的标准输出重定向到一个普通文件
$ echo 'hello shiyanlou' > redirect
$ cat redirect
管道默认是连接前一个命令的输出到下一个命令的输入,而重定向通常是需要一个文件来建立两个命令的连接
2.标准错误重定向
标准输出和标准错误都被指向伪终端的屏幕显示,所以我们经常看到的一个命令的输出通常是同时包含了标准输出和标准错误的结果的。比如下面的操作:# 使用cat 命令同时读取两个文件,其中一个存在,另一个不存在
$ cat Documents/test.c~ hello.c
# 你可以看到除了正确输出了前一个文件的内容,还在末尾出现了一条错误信息
# 下面我们将输出重定向到一个文件,根据我们前面的经验,这里将在看不到任何输出了
$ cat Documents/test.c~ hello.c > somefile

藏某些错误或者警告:
# 将标准错误重定向到标准输出,再将标准输出重定向到文件,注意要将重定向到文件写到前面
$ cat Documents/test.c~ hello.c >somefile 2>&1
# 或者只用bash提供的特殊的重定向符号"&"将标准错误和标准输出同时重定向到文件
$ cat Documents/test.c~ hello.c &>somefilehell

3.使用tee命令同时重定向到多个文件
经常你可能还有这样的需求,除了将需要将输出重定向到文件之外也需要将信息打印在终端,那么你可以使用tee命令来实现:
$ echo 'hello shiyanlou' | tee hello

4.永久重定向
exec命令的作用是使用指定的命令替换当前的 Shell,及使用一个进程替换当前进程,或者指定新的重定向:
# 先开启一个子 Shell
$ zsh
# 使用exec替换当前进程的重定向,将标准输出重定向到一个文件
$ exec 1>somefile
# 后面你执行的命令的输出都将被重定向到文件中,直到你退出当前子shell,或取消exec的重定向(后面将告诉你怎么做)
$ ls
$ exit
$ cat somefile

5.创建输出文件描述符
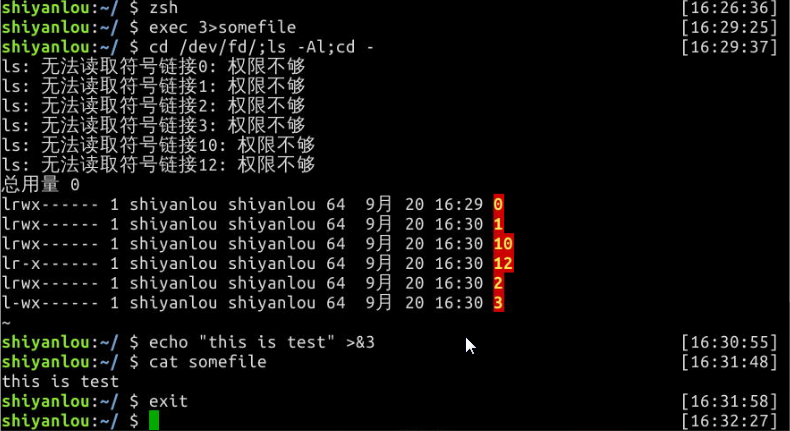
使用下面命令查看当前 Shell 进程中打开的文件描述符:
$ cd /dev/fd/;ls -Al
同样使用exec命令可以创建新的文件描述符:
$ zsh
$ exec 3>somefile
# 先进入目录,再查看,否则你可能不能得到正确的结果,然后再回到上一次的目录
$ cd /dev/fd/;ls -Al;cd -
# 注意下面的命令>与&之间不应该有空格,如果有空格则会出错
$ echo "this is test" >&3
$ cat somefile
$ exit
6.关闭文件描述符
如上面我们打开的3号文件描述符,可以使用如下操作将它关闭:
$ exec 3>&-
$ cd /dev/fd;ls -Al;cd -
7.完全屏蔽命令的输出
在类 UNIX 系统中,/dev/null,或称空设备,是一个特殊的设备文件,它通常被用于丢弃不需要的输出流,或作为用于输入流的空文件,这些操作通常由重定向完成。读取它则会立即得到一个EOF。
我们可以利用设个/dev/null屏蔽命令的输出:
$ cat Documents/test.c~ nefile 1>/dev/null 2>&1
向上面这样的操作将使你得不到任何输出结果。
8.使用 xargs 分割参数列表
xargs 是一条 UNIX 和类 UNIX 操作系统的常用命令。它的作用是将参数列表转换成小块分段传递给其他命令,以避免参数列表过长的问题。
这个命令在有些时候十分有用,特别是当用来处理产生大量输出结果的命令如 find,locate 和 grep 的结果,详细用法请参看 man 文档。
$ cut -d: -f1 < /etc/passwd | sort | xargs echo
上面这个命令用于将/etc/passwd文件按:分割取第一个字段排序后,使用echo命令生成一个列表。
作业:彩色动图君

实验十一正则表达式基础
一、正则表达式
正则表达式,又称正规表示式、正规表示法、正规表达式、规则表达式、常规表示法(英语:Regular Expression,在代码中常简写为 regex、regexp 或 RE),计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些符合某个模式的文本。
基本语法
一个正则表达式通常被称为一个模式(pattern),为用来描述或者匹配一系列符合某个句法规则的字符串。数量限定
数量限定除了我们举例用的*,还有+加号,?问号,.点号,如果在一个模式中不加数量限定符则表示出现一次且仅出现一次:
+表示前面的字符必须出现至少一次(1次或多次),例如,"goo+gle",可以匹配"gooogle","goooogle"等;?表示前面的字符最多出现一次(0次或1次),例如,"colou?r",可以匹配"color"或者"colour";*星号代表前面的字符可以不出现,也可以出现一次或者多次(0次、或1次、或多次),例如,“0*42”可以匹配42、042、0042、00042等。
范围和优先级
()圆括号可以用来定义模式字符串的范围和优先级,这可以简单的理解为是否将括号内的模式串作为一个整体
语法(部分)
| 字符 | 描述 |
|---|---|
| 将下一个字符标记为一个特殊字符、或一个原义字符。例如,“n”匹配字符“n”。“ ”匹配一个换行符。序列“\”匹配“”而“(”则匹配“(”。 | |
| ^ | 匹配输入字符串的开始位置。 |
| $ | 匹配输入字符串的结束位置。 |
| {n} | n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。 |
| {n,} | n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。 |
| {n,m} | m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”将匹配“fooooood”中的前三个o。“o{0,1}”等价于“o?”。请注意在逗号和两个数之间不能有空格。 |
| * | 匹配前面的子表达式零次或多次。例如,zo*能匹配“z”、“zo”以及“zoo”。*等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”或“does”中的“do”。?等价于{0,1}。 |
| ? | 当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串“oooo”,“o+?”将匹配单个“o”,而“o+”将匹配所有“o”。 |
| . | 匹配除“ ”之外的任何单个字符。要匹配包括“ ”在内的任何字符,请使用像“(.| )”的模式。 |
| (pattern) | 匹配pattern并获取这一匹配的子字符串。该子字符串用于向后引用。要匹配圆括号字符,请使用“(”或“)”。 |
| x|y | 匹配x或y。例如,“z|food”能匹配“z”或“food”。“(z|f)ood”则匹配“zood”或“food”。 |
| [xyz] | 字符集合(character class)。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”。其中特殊字符仅有反斜线保持特殊含义,用于转义字符。其它特殊字符如星号、加号、各种括号等均作为普通字符。脱字符^如果出现在首位则表示负值字符集合;如果出现在字符串中间就仅作为普通字符。连字符 - 如果出现在字符串中间表示字符范围描述;如果如果出现在首位则仅作为普通字符。 |
| [^xyz] | 排除型(negate)字符集合。匹配未列出的任意字符。例如,“[^abc]”可以匹配“plain”中的“plin”。 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。 |
| [^a-z] | 排除型的字符范围。匹配任何不在指定范围内的任意字符。例如,“[^a-z]”可以匹配任何不在“a”到“z”范围内的任意字符。 |
优先级
优先级为从上到下从左到右,依次降低:
| 运算符 | 说明 |
|---|---|
| 转义符 | |
| (), (?:), (?=), [] | 括号和中括号 |
| *、+、?、{n}、{n,}、{n,m} | 限定符 |
| ^、$、任何元字符 | 定位点和序列 |
| | | 选择 |
二、grep模式匹配命令
1.基本操作
grep命令用于打印输出文本中匹配的模式串,它使用正则表达式作为模式匹配的条件。grep支持三种正则表达式引擎,分别用三个参数指定:
| 参数 | 说明 |
|---|---|
-E |
POSIX扩展正则表达式,ERE |
-G |
POSIX基本正则表达式,BRE |
-P |
Perl正则表达式,PCRE |
grep命令的常用参数:
| 参数 | 说明 |
|---|---|
-b |
将二进制文件作为文本来进行匹配 |
-c |
统计以模式匹配的数目 |
-i |
忽略大小写 |
-n |
显示匹配文本所在行的行号 |
-v |
反选,输出不匹配行的内容 |
-r |
递归匹配查找 |
-A n |
n为正整数,表示after的意思,除了列出匹配行之外,还列出后面的n行 |
-B n |
n为正整数,表示before的意思,除了列出匹配行之外,还列出前面的n行 |
--color=auto |
将输出中的匹配项设置为自动颜色显示 |
使用正则表达式
使用基本正则表达式,BRE
位置
查找/etc/group文件中以"shiyanlou"为开头的行
$ grep 'shiyanlou' /etc/group
$ grep '^shiyanlou' /etc/group
数量
# 将匹配以'z'开头以'o'结尾的所有字符串
$ echo 'zero
zo
zoo' | grep 'z.*o'
# 将匹配以'z'开头以'o'结尾,中间包含一个任意字符的字符串
$ echo 'zero
zo
zoo' | grep 'z.o'
# 将匹配以'z'开头,以任意多个'o'结尾的字符串
$ echo 'zero
zo
zoo' | grep 'zo*'

选择
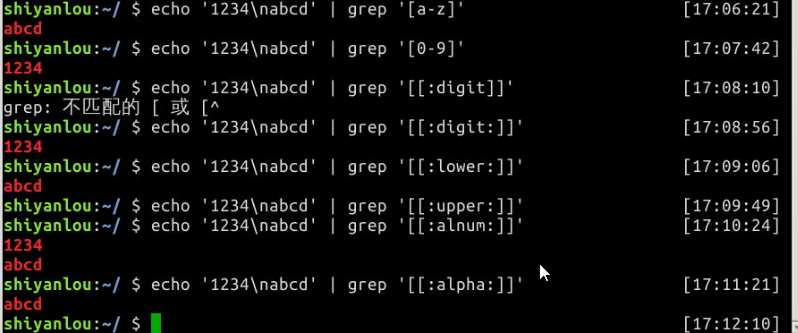
# grep默认是区分大小写的,这里将匹配所有的小写字母
$ echo '1234
abcd' | grep '[a-z]'
# 将匹配所有的数字
$ echo '1234
abcd' | grep '[0-9]'
# 将匹配所有的数字
$ echo '1234
abcd' | grep '[[:digit:]]'
# 将匹配所有的小写字母
$ echo '1234
abcd' | grep '[[:lower:]]'
# 将匹配所有的大写字母
$ echo '1234
abcd' | grep '[[:upper:]]'
# 将匹配所有的字母和数字,包括0-9,a-z,A-Z
$ echo '1234
abcd' | grep '[[:alnum:]]'
# 将匹配所有的字母
$ echo '1234
abcd' | grep '[[:alpha:]]'
下面包含完整的特殊符号及说明:
特殊符号 说明
| 特殊符号 | 说明 |
|---|---|
[:alnum:] |
代表英文大小写字节及数字,亦即 0-9, A-Z, a-z |
[:alpha:] |
代表任何英文大小写字节,亦即 A-Z, a-z |
[:blank:] |
代表空白键与 [Tab] 按键两者 |
[:cntrl:] |
代表键盘上面的控制按键,亦即包括 CR, LF, Tab, Del.. 等等 |
[:digit:] |
代表数字而已,亦即 0-9 |
[:graph:] |
除了空白字节 (空白键与 [Tab] 按键) 外的其他所有按键 |
[:lower:] |
代表小写字节,亦即 a-z |
[:print:] |
代表任何可以被列印出来的字节 |
[:punct:] |
代表标点符号 (punctuation symbol),亦即:" ' ? ! ; : # $... |
[:upper:] |
代表大写字节,亦即 A-Z |
[:space:] |
任何会产生空白的字节,包括空白键, [Tab], CR 等等 |
[:xdigit:] |
代表 16 进位的数字类型,因此包括: 0-9, A-F, a-f 的数字与字节 |
注意:之所以要使用特殊符号,是因为上面的[a-z]不是在所有情况下都管用,这还与主机当前的语系有关,即设置在LANG环境变量的值,zh_CN.UTF-8的话[a-z],即为所有小写字母,其它语系可能是大小写交替的如,"a A b B...z Z",[a-z]中就可能包含大写字母。所以在使用[a-z]时请确保当前语系的影响,使用[:lower:]则不会有这个问题。
# 排除字符
$ echo 'geek|good' | grep '[^o]'
注意:当^放到中括号内为排除字符,否则表示行首

使用扩展正则表达式,ERE
要通过grep使用扩展正则表达式需要加上-E参数,或使用egrep。
数量
# 只匹配"zo"
$ echo 'zero
zo
zoo' | grep -E 'zo{1}'
# 匹配以"zo"开头的所有单词
$ echo 'zero
zo
zoo' | grep -E 'zo{1,}'
注意:推荐掌握{n,m}即可,+,?,*,这几个不太直观,且容易弄混淆。
选择
# 匹配"www.shiyanlou.com"和"www.google.com"
$ echo 'www.shiyanlou.com
www.baidu.com
www.google.com' | grep -E 'www.(shiyanlou|google).com'
# 或者匹配不包含"baidu"的内容
$ echo 'www.shiyanlou.com
www.baidu.com
www.google.com' | grep -Ev 'www.baidu.com'
注意:因为.号有特殊含义,所以需要转义。
三、sed 流编辑器
sed常用参数介绍sed 命令基本格式:
sed [参数]... [执行命令] [输入文件]...
# 形如:
$ sed -i '1s/sad/happy/' test # 表示将test文件中第一行的"sad"替换为"happy"
| 参数 | 说明 |
|---|---|
-n |
安静模式,只打印受影响的行,默认打印输入数据的全部内容 |
-e |
用于在脚本中添加多个执行命令一次执行,在命令行中执行多个命令通常不需要加该参数 |
-f filename |
指定执行filename文件中的命令 |
-r |
使用扩展正则表达式,默认为标准正则表达式 |
-i |
将直接修改输入文件内容,而不是打印到标准输出设备 |
sed编辑器的执行命令(这里”执行“解释为名词)
sed执行命令格式:
[n1][,n2]command
[n1][~step]command
# 其中一些命令可以在后面加上作用范围,形如:
$ sed -i 's/sad/happy/g' test # g表示全局范围
$ sed -i 's/sad/happy/4' test # 4表示指定行中的第四个匹配字符串
其中n1,n2表示输入内容的行号,它们之间为,逗号则表示从n1到n2行,如果为~波浪号则表示从n1开始以step为步进的所有行;command为执行动作,下面为一些常用动作指令:
| 命令 | 说明 |
|---|---|
s |
行内替换 |
c |
整行替换 |
a |
插入到指定行的后面 |
i |
插入到指定行的前面 |
p |
打印指定行,通常与-n参数配合使用 |
d |
删除指定行 |
sed操作举例
我们先找一个用于练习的文本文件: $ cp /etc/passwd ~
打印指定行
# 打印2-5行
$ nl passwd | sed -n '2,5p'
# 打印奇数行
$ nl passwd | sed -n '1~2p'

行内替换
# 将输入文本中"shiyanlou" 全局替换为"hehe",并只打印替换的那一行,注意这里不能省略最后的"p"命令
$ sed -n 's/shiyanlou/hehe/gp' passwd
注意: 行内替换可以结合正则表达式使用。
行间替换
$ nl passwd | grep "shiyanlou"
# 删除第21行
$ sed -n '21cwww.shiyanlou.com' passwd
四、awk文本处理语言
1.awk介绍AWK是一种优良的文本处理工具,Linux及Unix环境中现有的功能最强大的数据处理引擎之一

2.awk的一些基础概念
awk所有的操作都是基于pattern(模式)—action(动作)对来完成的,如下面的形式:
$ pattern {action}
它将所有的动作操作用一对
{}花括号包围起来。其中pattern通常是是表示用于匹配输入的文本的“关系式”或“正则表达式”,action则是表示匹配后将执行的动作3.awk命令基本格式
awk [-F fs] [-v var=value] [-f prog-file | 'program text'] [file...]
其中-F参数用于预先指定前面提到的字段分隔符(还有其他指定字段的方式) ,-v用于预先为awk程序指定变量,-f参数用于指定awk命令要执行的程序文件,或者在不加-f参数的情况下直接将程序语句放在这里,最后为awk需要处理的文本输入,且可以同时输入多个文本文件。
4.awk操作体验
先用vim新建一个文本文档 $ vim test
包含如下内容: I like linux
www.shiyanlou.com
使用awk将文本内容打印到终端
# "quote>" 不用输入
$ awk '{
> print
> }' test
# 或者写到一行
$ awk '{print}' test

$ awk '{
> if(NR==1){
> print $1 "
" $2 "
" $3
> } else {
> print}
> }' test
# 或者
$ awk '{
> if(NR==1){
> OFS="
"
> print $1, $2, $3
> } else {
> print}
> }' test

将test的第二行的以点为分段的字段换成以空格为分隔
$ awk -F'.' '{
> if(NR==2){
> print $1 " " $2 " " $3
> }}' test
# 或者
$ awk '
> BEGIN{
> FS="."
> OFS=" " # 如果写为一行,两个动作语句之间应该以";"号分开
> }{
> if(NR==2){
> print $1, $2, $3
> }}' test

6.awk常用的内置变量
| 变量名 | 说明 |
|---|---|
FILENAME |
当前输入文件名,若有多个文件,则只表示第一个。如果输入是来自标准输入,则为空字符串 |
$0 |
当前记录的内容 |
$N |
N表示字段号,最大值为NF变量的值 |
FS |
字段分隔符,由正则表达式表示,默认为" "空格 |
RS |
输入记录分隔符,默认为" ",即一行为一个记录 |
NF |
当前记录字段数 |
NR |
已经读入的记录数 |
FNR |
当前输入文件的记录数,请注意它与NR的区别 |
OFS |
输出字段分隔符,默认为" "空格 |
ORS |
输出记录分隔符,默认为" " |
作业:
实验十二Linux 下软件安装
一、Linux 上的软件安装
通常 Linux 上的软件安装主要有四种方式:
在线安装
从磁盘安装deb软件包
从二进制软件包安装
从源代码编译安装
叫做 w3m(w3m是一个命令行的简易网页浏览器),那么输入如下命令:
$ sudo apt-get install w3m

注意:如果你在安装一个软件之后,无法立即使用Tab键补全这可命令,你可以尝试先执行source ~/.zshrc,然后你就可以使用补全操作。
. apt 包管理工具介绍
APT是Advance Packaging Tool(高级包装工具)的缩写,是Debian及其派生发行版的软件包管理器,APT可以自动下载,配置,安装二进制或者源代码格式的软件包,因此简化了Unix系统上管理软件的过程。APT最早被设计成dpkg的前端,用来处理deb格式的软件包。现在经过APT-RPM组织修改,APT已经可以安装在支持RPM的系统管理RPM包。这个包管理器包含以 apt- 开头的的多个工具,如 apt-get apt-cache apt-cdrom 等,在Debian系列的发行版中使用。
3.apt-get
apt-get使用各用于处理apt包的公用程序集,我们可以用它来在线安装、卸载和升级软件包等,下面列出一些apt-get包含的常用的一些工具:
| 工具 | 说明 |
|---|---|
install |
其后加上软件包名,用于安装一个软件包 |
update |
从软件源镜像服务器上下载/更新用于更新本地软件源的软件包列表 |
upgrade |
升级本地可更新的全部软件包,但存在依赖问题时将不会升级,通常会在更新之前执行一次update |
dist-upgrade |
解决依赖关系并升级(存在一定危险性) |
remove |
移除已安装的软件包,包括与被移除软件包有依赖关系的软件包,但不包含软件包的配置文件 |
autoremove |
移除之前被其他软件包依赖,但现在不再被使用的软件包 |
purge |
与remove相同,但会完全移除软件包,包含其配置文件 |
clean |
移除下载到本地的已经安装的软件包,默认保存在/var/cache/apt/archives/ |
autoclean |
移除已安装的软件的旧版本软件包 |
下面是一些apt-get常用的参数:
| 参数 | 说明 |
|---|---|
-y |
自动回应是否安装软件包的选项,在一些自动化安装脚本中使用这个参数将十分有用 |
-s |
模拟安装 |
-q |
静默安装方式,指定多个q或者-q=#,#表示数字,用于设定静默级别,这在你不想要在安装软件包时屏幕输出过多时很有用 |
-f |
修复损坏的依赖关系 |
-d |
只下载不安装 |
--reinstall |
重新安装已经安装但可能存在问题的软件包 |
--install-suggests |
同时安装APT给出的建议安装的软件包 |
4.安装软件包
你可以使用如下方式重新安装: $ sudo apt-get --reinstall install w3m5.软件升级
# 更新软件源
$ sudo apt-get update
# 升级没有依赖问题的软件包
$ sudo apt-get upgrade
# 升级并解决依赖关系
$ sudo apt-get dist-upgrade
6.卸载软件
同样是一个命令加回车 sudo apt-get remove w3m ,系统会有一个确认的操作,之后这个软件便“滚蛋了”。

或者,你可以执行
# 不保留配置文件的移除
$ sudo apt-get purge w3m
# 或者 sudo apt-get --purge remove
# 移除不再需要的被依赖的软件包
$ sudo apt-get autoremove
三、使用 dpkg 从本地磁盘安装 deb 软件包
我们经常可以在网络上简单以deb形式打包的软件包,就需要使用dpkg命令来安装。
dpkg常用参数介绍:
| 参数 | 说明 |
|---|---|
-i |
安装指定deb包 |
-R |
后面加上目录名,用于安装该目录下的所有deb安装包 |
-r |
remove,移除某个已安装的软件包 |
-I |
显示deb包文件的信息 |
-s |
显示已安装软件的信息 |
-S |
搜索已安装的软件包 |
-L |
显示已安装软件包的目录信息 |
2.使用dpkg安装deb软件包
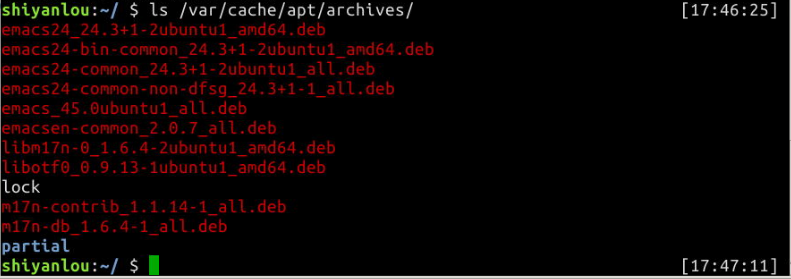
先使用apt-get加上-d参数只下载不安装,下载emacs编辑器的deb包我们可以查看/var/cache/apt/archives/目录下的内容,
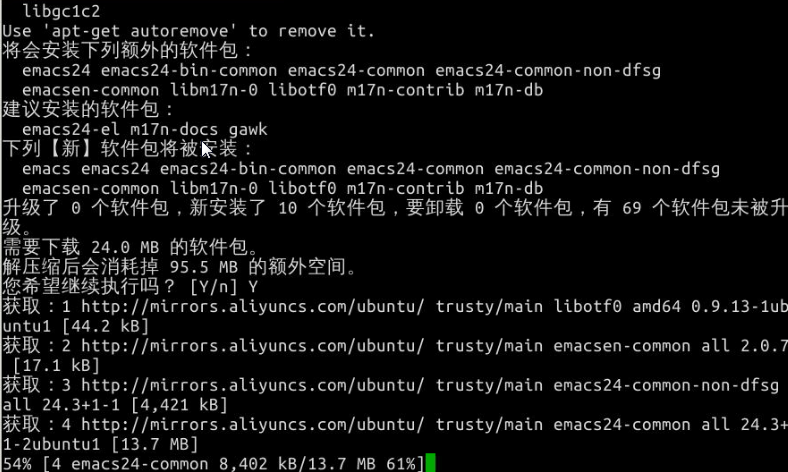
然后我们将第一个deb拷贝到home目录下,并使用dpkg安装
$ cp /var/cache/apt/archives/emacs24_24.3+1-4ubuntu1_amd64.deb ~
# 安装之前参看deb包的信息
$ sudo dpkg -I emacs24_24.3+1-4ubuntu1_amd64.deb
修复依赖关系的安装
$ sudo apt-get -f install
3.查看已安装软件包的安装目录
使用dpkg -L查看deb包目录信息 $ sudo dpkg -L emacs
四、从二进制包安装
二进制包的安装比较简单,我们需要做的只是将从网络上下载的二进制包解压后放到合适的目录,然后将包含可执行的主程序文件的目录添加进PATH环境变量即可,
作业: