中软国际华南区技术总监曾老师还会来上两次课,同学们希望曾老师讲些什么内容?(认真想一想回答)
Python有什么用,能应用在生活中的哪些方面
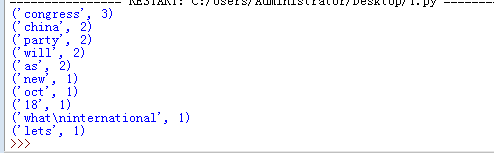
fo=open('test.txt','w') fo.write('''The 19th Communist Party of China National Congress will convene in Beijing on Oct 18. The Congress will review the Party's work over the past five years, discuss and set the future direction for the Party and the nation, as well as elect a new central leadership. As all eyes are on the upcoming Congress, let's take a look at what international media said about the developments and achievements of China.''') fo.close() fo=open('test.txt','r') news=fo.read() news=news.lower() for i in ",.'": news=news.replace(i,'') words=news.split(' ') dic={} exp={'','the','and','to','on','of','s','a','is'} keys=set(words)-exp #print(keys) for i in keys: dic[i]=words.count(i) #print(dic) a=list(dic.items()) a.sort(key=lambda x:x[1],reverse=True) #print(a) for i in range(10): print(a[i]) fo.close()
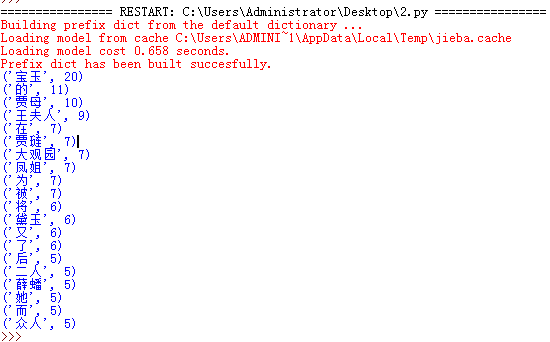
使用jieba库,进行中文词频统计,输出TOP20的词及出现次数。
import jieba aa=open('liangtao.txt','r').read() bb=jieba.cut(aa) news=list(bb) dic={} exp={'','。','“','”','、',',',' ','》','《'} keys=set(news)-exp for i in keys: dic[i]=news.count(i) a=list(dic.items()) a.sort(key=lambda x:x[1],reverse=True) for i in range(20): print(a[i])
>>> import jieba >>> word = jieba.cut('刘姥姥二进荣国府贾母在大观园摆宴把她作女清客取笑刘姥姥便以此逗贾母开心') >>> word <generator object Tokenizer.cut at 0x0000000003220620> >>> w=list(word) Building prefix dict from the default dictionary ... Dumping model to file cache C:UsersADMINI~1AppDataLocalTempjieba.cache Loading model cost 0.799 seconds. Prefix dict has been built succesfully. >>> w ['刘姥姥', '二进', '荣国府', '贾母', '在', '大观园', '摆宴', '把', '她', '作女', '清客', '取笑', '刘姥姥', '便', '以此', '逗', '贾母', '开心'] >>> wa=list(jieba.cut('刘姥姥二进荣国府贾母在大观园摆宴把她作女清客取笑刘姥姥便以此逗贾母开心',cut_all=True)) >>> wa ['刘姥姥', '姥姥', '二', '进', '荣国府', '国府', '贾', '母', '在', '大观', '大观园', '摆', '宴', '把', '她', '作', '女', '清客', '取笑', '刘姥姥', '姥姥', '便', '以此', '逗', '贾', '母', '开心'] >>> ws=list(jieba.cut_for_search('刘姥姥二进荣国府贾母在大观园摆宴把她作女清客取笑刘姥姥便以此逗贾母开心')) >>> ws ['姥姥', '刘姥姥', '二进', '国府', '荣国府', '贾母', '在', '大观', '大观园', '摆宴', '把', '她', '作女', '清客', '取笑', '姥姥', '刘姥姥', '便', '以此', '逗', '贾母', '开心']
**排除一些无意义词、合并同一词。
import jieba aa=open('liangtao.txt','r').read() bb=jieba.cut(aa) news=list(bb) dic={} exp={'','。','“','”','、',',',' ','》','《','宝玉','黛玉'} keys=set(news)-exp print(keys) for i in keys: dic[i]=news.count(i) a=list(dic.items()) a.sort(key=lambda x:x[1],reverse=True) for i in range(20): print(a[i])


**使用wordcloud库绘制一个词云。