一、做爬虫所需要的基础
要做一只爬虫,首先就得知道他会干些什么,是怎样工作的。所以得有一些关于HTML的前置知识,这一点做过网页的应该最清楚了。
HTML(超文本标记语言),是一种标记性语言,本身就是一长串字符串,利用各种类似 < a >,< /a>这样的标签来识别内容,然后通过浏览器的实现标准来翻译成精彩的页面。当然,一个好看的网页并不仅仅只有HTML,毕竟字符串是静态的,只能实现静态效果,要作出漂亮的网页还需要能美化样式的CSS和实现动态效果的JavaScipt,只要是浏览器都是支持这些玩意儿的。
嗯,我们做爬虫不需要了解太多,只需要了解HTML是基于文档对象模型(DOM)的,以树的结构,存储各种标记,就像这样:
之后会用到这种思想来在一大堆HTML字符串中找出我们想要的东西。

了解了这个然后还得了解网页和服务器之间是怎么通信的,这就得稍微了解点HTTP协议,基于TCP/IP的应用层协议,规定了浏览器和服务器之间的通信规则,简单粗暴的介绍几点和爬虫相关的就是:
浏览器和服务器之间有如下几种通信方式:
GET:向服务器请求资源,请求以明文的方式传输,一般就在URL上能看到请求的参数
POST:从网页上提交表单,以报文的形式传输,请求资源
还有几种比较少见就不介绍了。
了解了这两点就可以准备工具了,当然,对爬虫有兴趣还可以了解一下爬虫的发展史。
二、介绍几款优秀制作爬虫的辅助工具
由于我是采用python3.6开发的,然后从上文的介绍中,也该知道了一只爬虫是需要从HTML中提取内容,以及需要和网页做交互等。
如果不采用爬虫框架的话,我建议采用:
BeautifulSoup 库 ,一款优秀的HTML/XML解析库,采用来做爬虫,
不用考虑编码,还有中日韩文的文档,其社区活跃度之高,可见一斑。
[注] 这个在解析的时候需要一个解析器,在文档中可以看到,推荐lxml
Requests 库,一款比较好用的HTTP库,当然python自带有urllib以及urllib2等库,
但用起来是绝对没有这款舒服的,哈哈
Fiddler. 工具,这是一个HTTP抓包软件,能够截获所有的HTTP通讯。
如果爬虫运行不了,可以从这里寻找答案,官方链接可能进不去,可以直接百度下载
爬虫的辅助开发工具还有很多,比如Postman等,这里只用到了这三个,相信有了这些能减少不少开发阻碍。
三、最简单的爬虫试例
最简单的爬虫莫过于单线程的静态页面了,这甚至都不能叫爬虫,单单一句正则表达式即可匹配出所有内容,比如各种榜单:豆瓣电影排行榜,这类网站爬取规则变化比较少,用浏览器自带的F12的审查很容易找到需要爬取信息的特征:
见到花花绿绿的HTML代码不要害怕,一个一个点,直到找到需要的信息就行了,可以看到所有电影名都是在这样
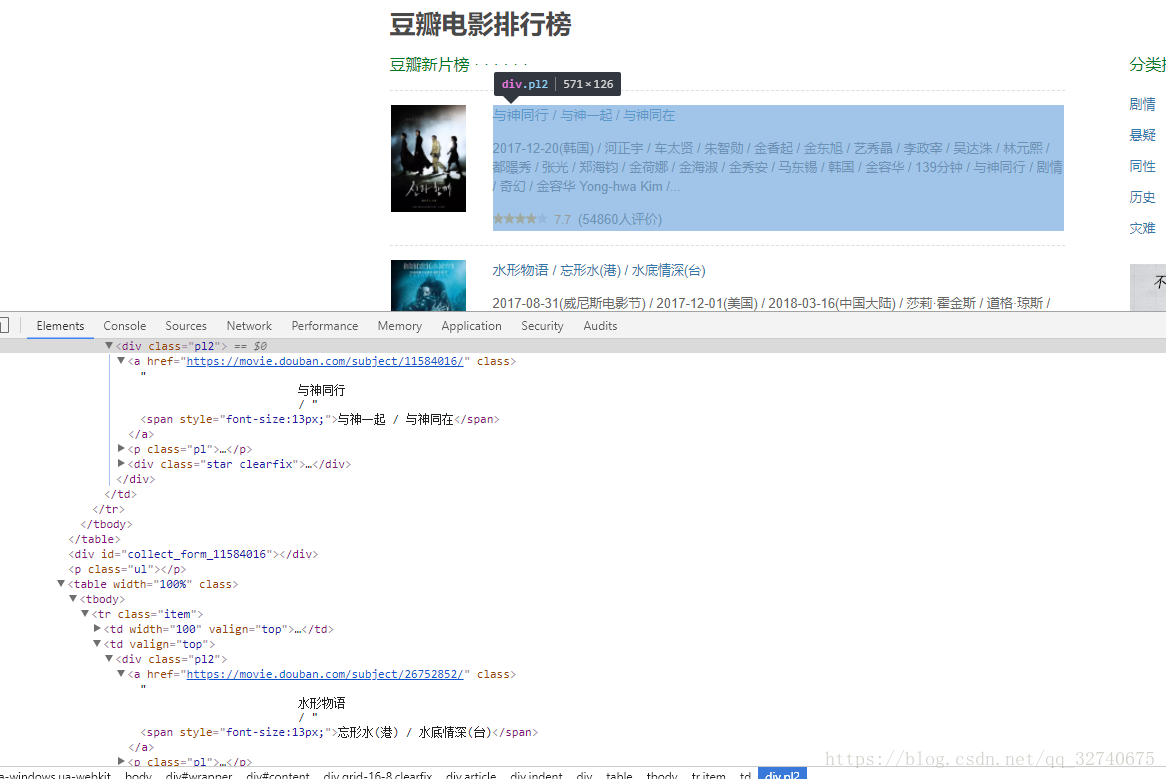
<div class = "pl2">
- 1
之下的,每有一个这样的标签就代表一个电影,从他的孩子< span >中即可抓取到电影名。
代码如下:
from bs4 import BeautifulSoup
from lxml import html
import xml
import requests
url = "https://movie.douban.com/chart"
#f = requests.get(url) #Get该网页从而获取该html内容
f = requests.get(url,headers = {'user-agent': 'anything'})
soup = BeautifulSoup(f.content, "lxml") #用lxml解析器解析该网页的内容, 好像f.text也是返回的html
#print(f.content.decode()) #尝试打印出网页内容,看是否获取成功
#content = soup.find_all('div',class_="p12" ) #尝试获取节点,因为calss和关键字冲突,所以改名class_
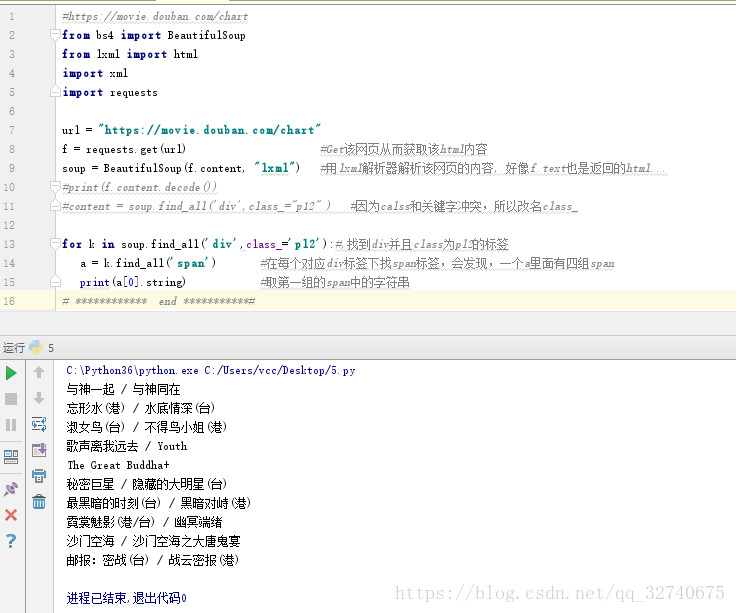
for k in soup.find_all('div',class_='pl2'):#,找到div并且class为pl2的标签
a = k.find_all('span') #在每个对应div标签下找span标签,会发现,一个a里面有四组span
print(a[0].string) #取第一组的span中的字符串
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
抓取结果如下:
乍一看,就这么个玩意儿,这些电影名还不如直接自己去网页看,这有什么用呢?但是,你想想,只要你掌握了这种方法,如果有翻页你可以按照规则爬完了一页就解析另外一页HTML(通常翻页的时候URL会规律变化,也就是GET请求实现的翻页),也就是说,只要掌握的爬取方法,无论工作量有多么大都可以按你的心思去收集想要的数据了。
四、需要模拟登录后再爬取的爬虫所需要的信息
4.1.登录分析
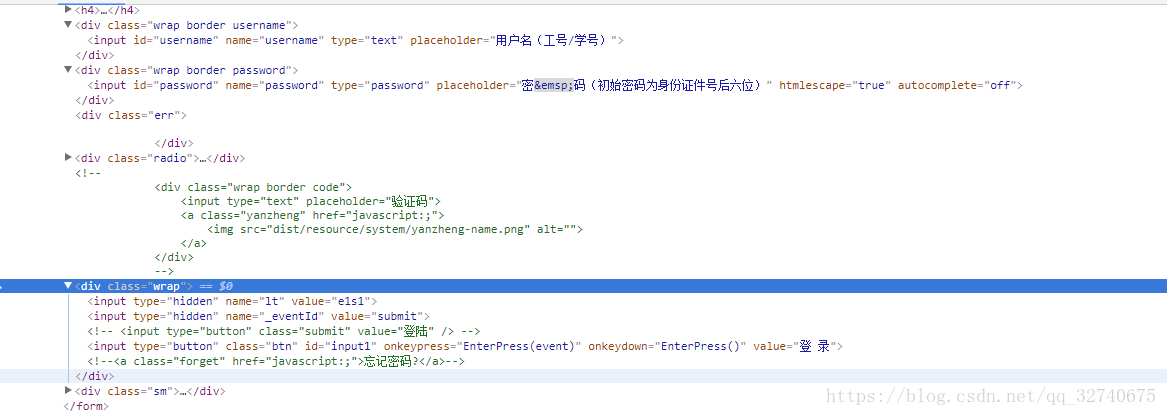
刚才的爬虫未免太简单,一般也不会涉及到反爬虫方面,这一次分析需要登录的页面信息的爬取,按照往例,首先打开一个网页:
我选择了我学校信息服务的网站,登录地方的代码如下:
可以看到验证码都没有,就只有账号密码以及提交。光靠猜的当然是不行的,一般输入密码的地方都是POST请求。
POST请求的响应流程就是 客户在网页上填上服务器准备好的表单并且提交,然后服务器处理表单做出回应。一般就是用户填写帐号、密码、验证码然后把这份表单提交给服务器,服务器从数据库进行验证,然后作出不同的反应。在这份POST表单中可能还有一些不需要用户填写的用脚本生成的隐藏属性作为反爬虫的手段。
要知道表单格式可以先试着随便登录一次,然后在F12中的network中查看登录结果,如图:
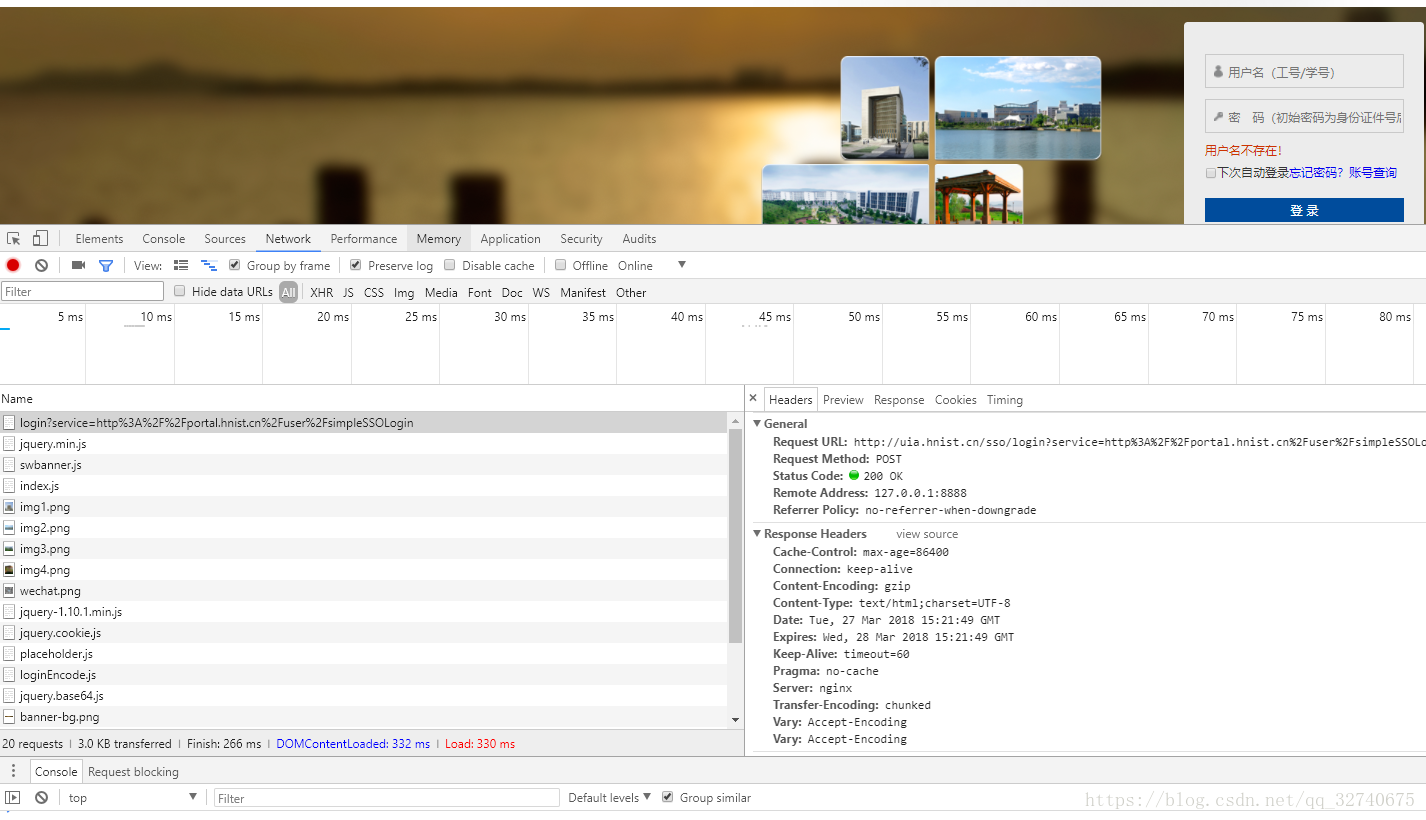
【注】如果用真正的账号密码登录,要记住勾选上面的Preserve log,这样即使网页发生了跳转之前的信息也还在。
从上面的两张图中很容易发现其中的一个POST请求, login?serv…就是登录请求了
可以看到这个登录请求所携带的信息有:
General: 记录了请求方式,请求地址,以及服务器返回的状态号 200等
Response Headers: 响应头,HTTP响应后传输的头部消息
Request Headers: 请求头,重点!!,向服务器发送请求时,发出的头部消息,之中很多参数都是爬虫需要模拟出来传送给服务器的。
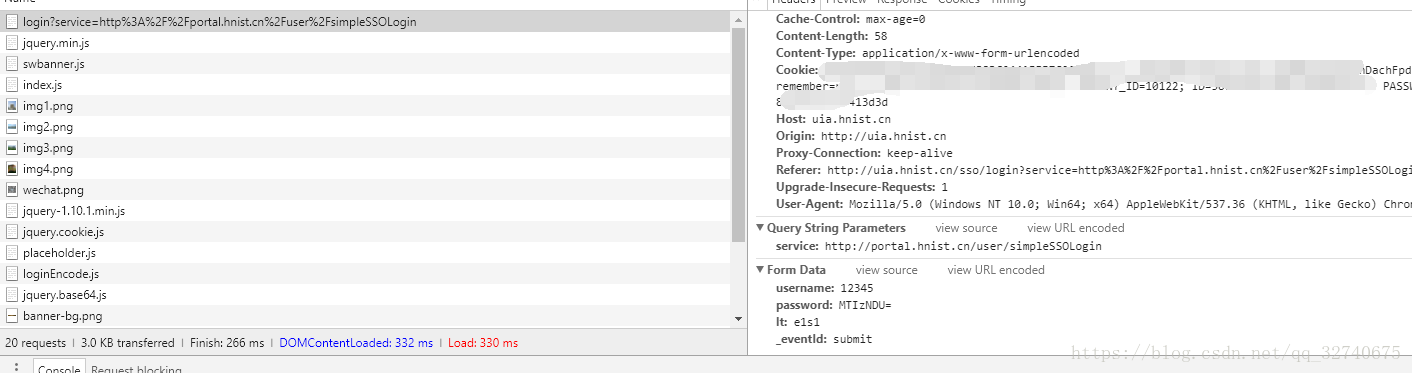
From Data:表单,重点!!,在这里表单中有:
username: 12345
password: MTIzNDU=
lt: e1s1
_eventId: submit
- 1
- 2
- 3
- 4
我明明都填的12345,为什么密码变了呢?可以看出这密码不是原始值,应该是编码后的产物,网站常用的几种编码/加密方法就几种,这里是采用的base64编码,如果对密码编码的方式没有头绪可以仔细看看登录前后页面的前端脚本。运气好可以看到encode函数什么的。
4.2信息提取
如果了解过Resquests库的文档就知道,发送一个一般的POST请求所需要的参数构造是这样的:
r = requests.post(url,[data],[header],[json],[**kwargs])
/*
url -- URL for the new Request object.
data -- (optional) Dictionary, bytes, or file-like object to send in the body of the Request.
json -- (optional) json to send in the body of the Request.
**kwargs -- Optional arguments that request takes.
*/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
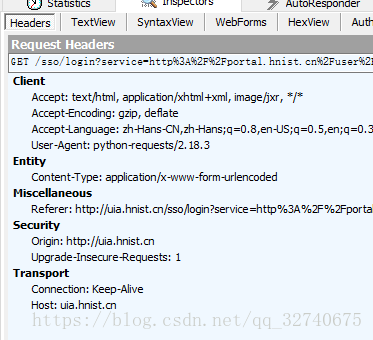
从上面的两张图片中即可找到发送一个正确的请求所需要的参数,即 url 和 data :
url 即上面的 Request URL:
Request URL: http://uia.hnist.cn/sso/login?service=http%3A%2F%2Fportal.hnist.cn%2Fuser%2FsimpleSSOLogin
data 即上面的From data:
username: 12345
password: MTIzNDU=
lt: e1s1
_eventId: submit
- 1
- 2
- 3
- 4
收集到了必要的信息还得了解三点:
一、登录后的网页和服务器建立了联系,所以能和服务器进行通信,但即使你从这个网页点击里面的超链接跳转到另外一个子网页,在新网页中还是保持登录状态的在不断的跳转中是怎么识别用户的呢?
在这里,服务器端一般是采用的Cookie技术,登陆后给你一个Cookie,以后你发出跳转网页的请求就携带该Cookie,服务器就能知道是你在哪以什么状态点击的该页面,也就解决了HTTP传输的无状态问题。
很明显,在模拟登录以后保持登录状态需要用得着这个Cookie,当然Cookie在请求头中是可见的,为了自己的账号安全,请不要轻易暴露/泄漏自己的Cookie
二、先了解一下,用python程序访问网页的请求头的User-Agent是什么样的呢?没错,如下图所示,很容易分辨这是程序的访问,也就是服务器知道这个请求是爬虫访问的结果,如果服务器做了反爬虫措施程序就会访问失败,所以需要程序模拟浏览器头,让对方服务器认为你是使用某种浏览器去访问他们的。
三、查找表单隐藏参数的获取方式,在上文表单列表中有个lt参数,虽然我也不知道他是干嘛的,但通过POST传输过去的表单肯定是会经过服务器验证的,所以需要弄到这份参数,而这份参数一般都会在HTML页面中由JS脚本自动生成,可以由Beautifulsoup自动解析抓取。
关于Fiddler的使用和请求信息相关信息可以查看链接:https://zhuanlan.zhihu.com/p/21530833?refer=xmucpp
嗯,最重要的几样东西已经收集完毕,对Cookie和请求头的作用也有了个大概的了解,然后开始发送请求试试吧~
五、开始编码爬虫
如果用urllib库发送请求,则需要自己编码Cookie这一块(虽然也只要几行代码),但用Requests库就不需要这样,在目前最新版本中,requests.Session提供了自己管理Cookie的持久性以及一系列配置,可以省事不少。
先以面对过程的方式实验地去编码:
from bs4 import BeautifulSoup
from lxml import html
import requests
####################################################################################
# 在这先准备好请求头,需要爬的URL,表单参数生成函数,以及建立会话
############################# 1 #################################################
header={
"Accept": "text/html, application/xhtml+xml, image/jxr, */*",
"Referer": "http://uia.hnist.cn/sso/login?service=http%3A%2F%2Fportal.hnist.
cn%2Fuser%2FsimpleSSOLogin",
"Accept-Language": "zh-Hans-CN,zh-Hans;q=0.8,en-US;q=0.5,en;q=0.3",
"Content-Type": "application/x-www-form-urlencoded",
"Accept-Encoding": "gzip, deflate",
"Connection": "Keep-Alive",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36",
"Accept-Encoding": "gzip, deflate",
"Origin": "http://uia.hnist.cn",
"Upgrade-Insecure-Requests": "1",
#Cookie由Session管理,这里不用传递过去,千万不要乱改头,我因为改了头的HOST坑了我两天
}
School_login_url = 'http://uia.hnist.cn/sso/login?
service=http%3A%2F%2Fportal.hnist.cn%2Fuser%2FsimpleSSOLogin'#学校登录的URL
page = requests.Session() #用Session发出请求能自动处理Cookie等问题
page.headers = header #为所有请求设置头
page.get(School_login_url) #Get该地址建立连接(通常GET该网址后,服务器会发送一些用于
验证的参数用于识别用户,这些参数在这就全由requests.Session处理了)
def Get_lt(): #获取参数 lt 的函数
f = requests.get(School_login_url,headers = header)
soup = BeautifulSoup(f.content, "lxml")
once = soup.find('input', {'name': 'lt'})['value']
return once
lt = Get_lt() #获取lt
From_Data = { #表单
'username': 'your username',
'password': 'Base64 encoded password',
#之前说过密码是通过base64加密过的,这里得输入加密后的值,或者像lt一样写个函数
'lt': lt,
'_eventId': 'submit',
}
############################# 1 end #############################
################################################################
# 在这一段向登录网站发送POST请求,并判断是否成功返回正确的内容
############################# 2 #################################
q = page.post(School_login_url,data=From_Data,headers=header)
#发送登陆请求
#######查看POST请求状态##############
#print(q.url) #这句可以查看请求的URL
#print(q.status_code) #这句可以查看请求状态
#for (i,j) in q.headers.items():
# print(i,':',j) #这里可以查看响应头
#print('
')
#for (i,j) in q.request.headers.items():
# print(i,':',j) #这里可以查看请求头
####上面的内容用于判断爬取情况,也可以用fiddle抓包查看 ####
f = page.get('http://uia.hnist.cn') #GET需要登录后(携带cookie)才能查看的网站
print("body:",f.text)
######## 进入查成绩网站,找到地址,请求并接收内容 #############
proxies = { #代理地址,这里代理被注释了,对后面没影响,这里也不需要使用代理....
#"http": "http://x.x.x.x:x",
#"https": "http://x.x.x.x:x",
}
######## 查成绩网站的text格式表单,其中我省略了很多...######
str = """callCount=1
httpSessionId=DA0080E0317A1AD0FDD3E09E095CB4B7.portal254
scriptSessionId=4383521D7E8882CB2F7AB18F62EED380
page=/web/guest/788
"""
#### 这是由于该服务器关于表单提交部分设计比较垃圾,所以不用去在意表单内容含义 ###
f = page.post('http://portal.hnist.cn/portal_bg_ext/dwr/plainjs/
ShowTableAction.showContent.dwr',data=str,proxies=proxies)
#查成绩的地址,表单参数为上面的str
###### 查看地址,返回状态,以及原始内容#######"""
print("f:",f.url)
print(f.status_code)
text = f.content.decode('unicode_escape')
print(text.encode().decode()) #因为原始内容中有uxxx形式的编码,所以使用这句解码
###########################################"""
################################### 2 end #########################
###################################################################
# 解析获得的内容,并清洗数据,格式化输出...
############################# 3 ####################################
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
[注] 如果使用了Fiddler,他会自动为Web的访问设置一个代理,这时候如果你关闭了Fiddler可能爬虫会无法正常工作,这时候你选择浏览器直连,或者设置爬虫的代理为Fiddler即可。
[注2]爬虫不要频率太快,不要影响到别人服务器的正常运行,如果不小心IP被封了可以使用代理(重要数据不要使用不安全的代理),网上有很多收费/免费的代理,可以去试下。
过程中获得的经验:
- 在上面第一部分,不知道作用的参数不要乱填,只需要填几个最重要的就够了,比如UA,有时候填了不该填的请求将会返回错误状态.,尽量把可分离的逻辑写成函数来调用,比如生成的表单参数,加密方法等.
- 在上面第二部分如果请求失败可以配合抓包软件查看程序和浏览器发送的请求有什么差别,遗漏了什么重要的地方,尽量让程序模仿浏览器的必要的行为。
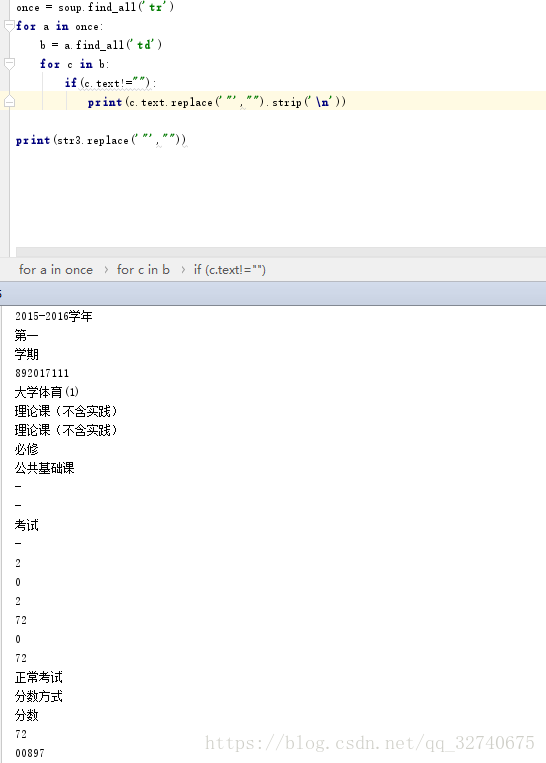
- 第三部分中,因为拿到的数据是如下图1这样的,所以需要最后输出后decode,然后再使用正则表达式提取出双引号中的内容连接诶成一个标记语言的形式,再使用Beautifulsoup解析获得需要的数据,如图2.
- 中途可能利用的工具有:
官方正则表达式学习网站
HTML格式美化
正则表达式测试
图1
图2

六、爬虫技术的拓展与提高
经历了困难重重,终于得到了想要的数据,对于异步请求,使用JS渲染页面后才展示数据的网页,又或是使用JS代码加密过的网页,如果花时间去分析JS代码来解密,简单的公有的加密方法倒是无所谓,但对于特别难的加密就有点费时费力了,在要保持抓取效率的情况下可以使用能使用Splash框架:
这是一个Javascript渲染服务,它是一个实现了HTTP API的轻量级浏览器,Splash是用Python实现的,同时使用Twisted和QT。Twisted(QT)用来让服务具有异步处理能力,以发挥webkit的并发能力。
就比如像上面返回成绩地址的表单参数,格式为text,并且无规律,有大几十行,如果要弄明白每个参数是什么意思,还不如加载浏览器的JS 或 使用浏览器自动化测试软件来获取HTML了,所以,遇到这种情况,在那么大一段字符串中,只能去猜哪些参数是必要的,哪些参数是不必要的,比如上面的,我就看出两个是有关于返回页面结果的,其余的有可能存在验证身份的,时间的什么的。
对于信息的获取源,如果另外的网站也有同样的数据并且抓取难度更低,那么换个网站爬可能是个更好的办法,以及有的网站根据请求头中的UA会产生不同的布局和处理,比如用手机的UA可能爬取会更加简单。
七、后记
几天后我发现了另一个格式较好的页面,于是去爬那个网站,结果他是.jsp的,采用之前的方法跳转几个302之后就没有后续了…后来才猜想了解到,最后一个302可能是由JS脚本跳转的,而我没有执行JS脚本的环境,也不清楚他执行的哪个脚本,传入了什么参数,于是各种尝试和对比,最后发现:正常请求时,每次都多2个Cookie,开始我想,Cookie不是由Session管理不用去插手的吗?然后我想以正常方式获得该Cookie,请求了N个地址,结果始终得不到想要的Cookie,于是我直接使用Session.cookies.set('COMPANY_ID','10122')添加了两个Cookie,还真成了…神奇…
当然,过了一段时间后,又不行了,于是仔细观察,发现每次就JSESSIONID这一个Cookie对结果有影响,传递不同的值到不同的页面还…虽然我不认同这种猜的,毫无逻辑效率的瞎试。但经历长时间的测试和猜测,对结果进行总结和整理也是能发现其中规律的。
关于判断某动作是不是JS,可以在Internet选项中设置禁止使用JS
关于失败了验证的方法,我强烈建议下载fiddler,利用新建视图,把登录过程中所有的图片,CSS等文件去掉以后放到新视图中,然后利用程序登录的过程也放一个视图当中,如果没有在响应中找到需要的Cookie,还可以在视图中方便的查看各个JS文件,比浏览器自带的F12好用太多了。 如下图:

总之,经过这段时间的尝试,我对爬虫也有了个初步的了解,在这方面,也有了自己做法:
抓包请求 —> 模仿请求头和表单—>如果请求失败,则仔细对比正常访问和程序访问的数据包 —>成功则根据内容结构进行解析—>清清洗数据并展示
原文链接:https://blog.csdn.net/qq_32740675/article/details/79720367?utm_medium=distribute.pc_relevant.none-task-blog-OPENSEARCH-5.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-OPENSEARCH-5.control