
之前一篇写了关于 Redis 的性能,这篇就写写我认为比性能更重要的扩展性方面的主题。
如果再给我一次回到好几年前的机会,对于使用 Redis 我一开始就要好好考虑将来的扩展问题。就像我们做数据库分库分表,一旦决策了分库分表,通常一次就会分到位,比如搞上 8 或 16 个库,每个库再分 256 或 1024 个表。不管将来业务再怎么发展,基本这个量级的分片都足够应对,而且底层库可以做成逻辑的,扛不住时再换成物理的,对应用方完全透明,没有数据迁移的烦恼。
而 Redis 其实也提供了类似的逻辑库概念,每个 Redis 实例都有 0 到 15 号独立的逻辑库空间。当我们早期机器资源紧张而业务量又不大时,可以好好根据业务把不同的数据放在的单一实例的不同编号逻辑库上。这是一种垂直切分方式,也可以用水平方式,把 0 到 15 号逻辑库当成 16 个分片来用,只是这种用法可能对 Client 库有些要求。
总之好几年前我们都没有这样,当时物理机资源紧张,为了考虑不远将来的业务扩张,所以在有限的资源下决定尽可能的分片。但也没分太多,大约 10 片吧,多了运维成本也高。感觉按 Redis 的性能这一组分片最大承载几十万每秒的 OPS 估计能支撑很长时间的发展了。那 10 片怎么部署呢?由于每个 Reids 实例只能利用一个核,当时的服务器大概是 16 核,全放一台机也可以。当时我们正好有 10 台物理机,所以很自然的每台放了一个实例,但 Redis 只能用一个核,太浪费了。所以每台物理机上除了部署 Reids 还要部署应用服务,后来领悟到这又是一个错误的部署方式(背景音乐:多么痛的领悟)。
一台 PC Server 的硬件可靠性大约是 99.9%,Redis 作为一个应用全局共享的关键服务分成 10 片放在十台 PC Server 上。实际上导致整体系统可靠性还降低了一个量级,变成了两个 9。因为任何一台 PC Server 挂了都可能导致全局系统故障。然而当初没有多余的机器资源,为了提高可靠性,必须对 Redis 做主备,唯一的办法就是交叉主备,所以部署结构大概类似下面这样。

后来,随着业务发展流量变得越来越大,Redis 内存占用越来越多,而且开始出现一些诡异的故障现象。比如出现瞬时 Redis 大量连接和处理超时,应用业务线程被阻塞,导致服务拒绝,过一段时间可能又自动恢复了。这种瞬时故障非常难抓现场,一天来上几发就会给人业务不稳定的感受,而一般基础机器指标的监控周期在分钟级。瞬时故障可能发生在监控的采集间隙,所以只好上脚本在秒级监控日志,发现瞬时出现大量 Redis 超时错误,就收集当时应用的 JVM 堆栈、内存和机器 CPU Load 等各项指标。终于发现瞬时故障时刻 Redis 机器 CPU Load 出现瞬间飙升几百的现象,应用和 Redis 混合部署时应用可能瞬间抢占了全部 CPU 导致 Redis 没有 CPU 资源可用。而应用处理业务的逻辑又可能需要访问 Redis,而 Redis 又没有 CPU 资源可用导致超时,这不就像一个死锁么。搞清楚了原因其实解决方法也简单,就是分离应用和 Redis 的部署,各自资源隔离,自此我们的 Redis 集群发展开始走上一条合纵与连横的道路。
合纵
分离应用和 Redis 的部署后,关于物理机资源的有一个尴尬点就是 Redis 单线程机制带来的。当时一台 PC Server 16 核,内存 16 G,你想多利用核就要多部署实例,但每个实例分到的内存又不多。最终我们一台物理机只部署 2 个实例,因为业务发展对内存的需求强过对 CPU 的利用,所以调整后的部署模型变成下面这样。

这样每个 Redis 实例能分到的内存是小于 8G 的(还要给系统留一点不是)。随着业务发展,一开始是 2G,很快 4G 然后 6G 就到了单机内存瓶颈,下一步只能分一个实例出去,每个实例独享单机内存。纵向扩容在操作性上是最简单的,在另外一台机器上先挂一个从分片,同步复制完成后,通知 Client 端切换连接而分片 Hash 规则还是不变。这个过程会有短暂的(下图 2-5 步这个过程程序执行的时间窗口)写丢失,在业务上是可接受的。

独享了更大内存,我们就可以继续纵向扩内存,但扩到了 12G 后就基本到顶了,即便还有更大内存的物理机也不宜再扩大单分片的内存了。主要原因是因为 Redis 的主从复制导致的服务中断,当初 Redis 版本是 2.4,直到 2.8 才有增量的主从复制。即使 2.8 主从复制依然可能在断链长时间后导致全量复制,虽然官方文档号称主从复制不中断服务,但实际每次全量复制 dump 内存时是阻断了主线程执行。这个阻断时间在 12G 内存时大概有一分多钟, 继续纵向扩大内存会导致更长时间的阻断,在业务上不可接受,合纵之路也走到头了。
连横
为了对业务做到无缝透明的扩容,只能走横向发展的道路。而 Redis 官方的 Cluster 方案一直跳票,迟迟出不来,大家的业务都在快速发展,等不及啊。所以在横向扩展上演变出了两种方案,一种是代理模式,利用引入中间 Proxy 来向应用层屏蔽后端的集群分布。业界最早是 Twitter 开源的 Twemproxy 采用了这种模式,后来豌豆荚开源的 Codis 进一步在运维可操作性上完善了这种模式。主要是在扩容方面尽可能的做到业务无感知,思路就是前端引入 Proxy 隔离应用层,后端改造 Redis 引入 Slot(有些也叫 Buket)来分组 key。应用层访问时基于算法将 key 先映射到 Slot 再映射到具体分片实例,大概如下面这样。
F(key) -> Slot -> Instance
Redis 中的 key 按 Slot 来组织,平滑扩容时比如加分片后,按 Slot 为单位迁移,这通常需要改造 Redis 源码来支持。这个模式的架构示意图如下所示。

引入 Proxy 是牺牲了少量性能来换取了对应用的透明和更好的扩展性。另一种方案是基于 Smart Client 免代理,但对应用有一定的侵入性,本质上就是把 Proxy 的功能放到了 Client。
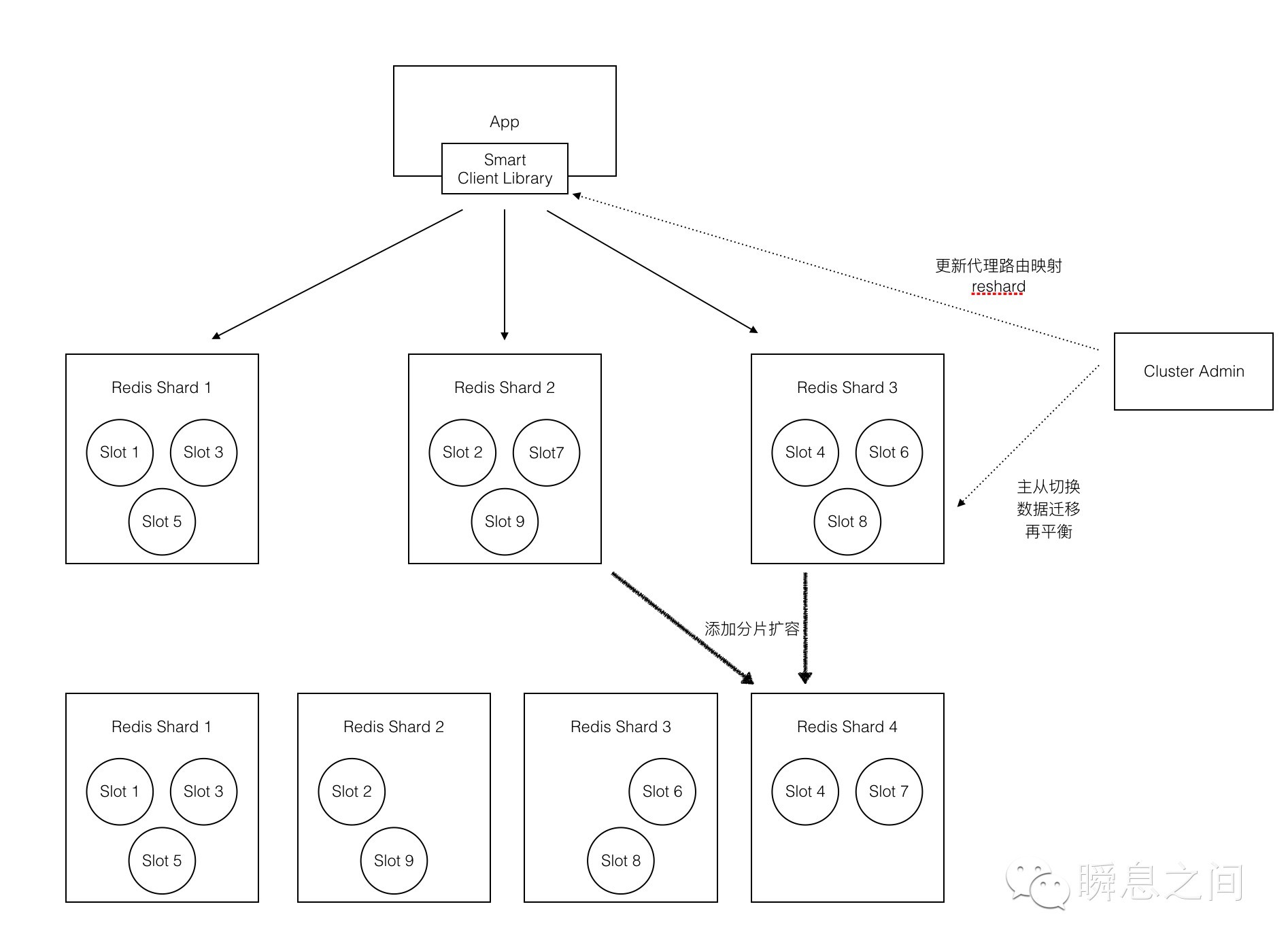
至于采用哪种方案就是仁者见仁、智者见智了,需要根据实际情况去考虑。不过个人认为基于代理的方案更灵活些,而且可在 Proxy 层能做的事情比 Client 要多,但对 Proxy 的实现要求也更高。不管上面哪种方案都采用了中心化的控制方式,中心化对简化运维操作是有好处的,而且能方便做到集群全局的管理。
Redis Cluster 终于迟迟推出后,采用了与中心化不同的思路,而且设计目标更追求性能,所以是依赖 Smart Client 的方式。而 Redis Server 的实现还是使用了 Slot 方式默认最大 16 * 1024 = 16384 个 Slot,所以理论集群最大就是这么多个实例,实际不大可能需要这么大。采用 Gossip 消息来同步集群配置,基于投票机制来进行主从 Failover 发现和自动切换。从目前已经推出的版本和功能来看,作者是在往一个纯 Smart Cluster 方向发展,但显然目前的版本还不成熟。比如自动发现、集群智能再平衡等功能都没有,还依赖人工操作。而且非中心化的集群相比中心化集群的可预测性和操作性都要差不少,其在真实的应用案例,除了在网易有道有人分享了一个非关键类场景,还没见过比较有份量的成熟案例。所以 Redis Cluster 的道路恐怕还在路漫漫其修远兮,吾将上下而求索的阶段。

总结
前面回顾了 Redis 集群发展的历程,从合纵到连横实际是一个从业务垂直切分到平台服务化的过程。至于到底应该采用什么样的集群模式,可能需要好好结合自身的业务发展阶段、团队能力和企业环境去分析取舍了。没有最好的,只有合适的。
参考
[1] antirez. Redis Cluster Specification
[2] 黄东旭. 分布式 Redis 架构设计和踩过的那些坑们
[3] 西代零零发. 全面剖析 Redis Cluster 原理和应用
[4] 西代零零发. Redis Cluster 架构优化
[5] 杨肉. Redis Cluster 使用经验
你还可以看
