OOV问题及其常用解决方法
什么是oov问题?
在encoder-decoder结构中,需要通过固定的词典对平行语料进行表示,词典大小一般控制在30k-60k;因此希望减少词表的大小,从而提高时间和空间效率。
同时还希望文本长度尽可能的短,因为文本长度的增加会降低效率并增加神经模型传递信息所需的距离(LSTM),文本越长信息丢失的可能性越大。这就导致了很多未登录词(OOV)和罕见词(Rare Words)。 另外,新词每时每刻都可能被创造出来,这些新词显然也不在词汇表中,也是属于未登录词的一种。
传统解决方案
传统方法在解决oov问题时,主要有:
- 增加词典长度(enlarge vocabulary)
- 直接忽略(Ingore)
- UNK替代

该方法在一定程度上能够消除oov的影响,但是作用非常的有限。尤其是在一些NLP任务中,OOV词可能具有极重要的意义。例如,在情感分类问题中,OOV词汇中可能包含表达positive或者negative的情感词。 - 字符表示(Individual Characters)


- 特征哈希(Feature Hashing)
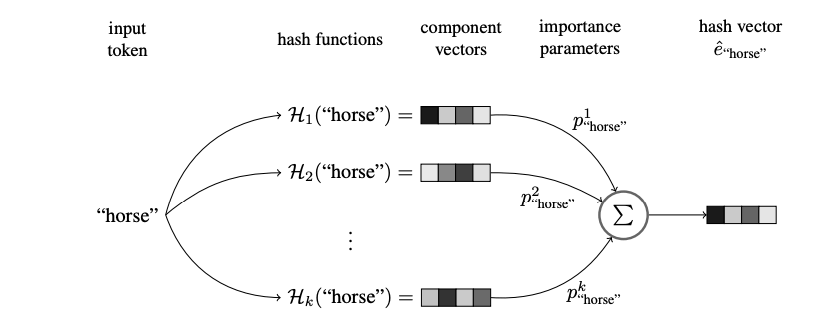
哈希表示并不是特地为解决oov问题而设计的算法。该方法引入到nlp解决oov问题,只是盲目的认为哈希碰撞(hash collision)能在有些时候让模型work。当前,很多时候,该方法能够起到一定的作用。 - 拼写检查(spell check)
基于sub-word的解决方案
上述解决方案是一些比较古老的、传统的解决方案;而随着研究的加深,提出了一些基于子词(sub word)的解决方案(当然,也已经不怎么用)。
- 字词生成(sub word generation)
对于一个词来说,采取它长度为3-6的n-gram词组来表示该词汇。


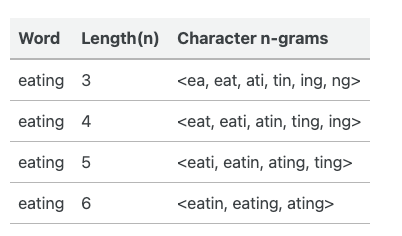
经过该处理后,可能得到大量(且唯一)的n-grams表示,因此进一步应用哈希的方式,将其进行转换
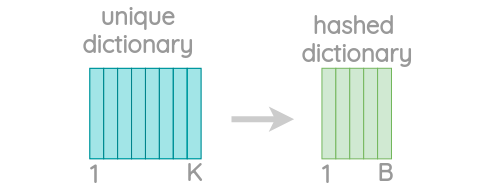
经过hash后的词汇表,能将每一个n-gram表示为1-B之间的整数。

- BPE方法(Byte Pair Encoding)
step1.准备⾜够⼤的训练语料
step2.确定期望的subword词表⼤⼩
step3.将单词拆分为字符序列并在末尾添加后缀“ </ w>”,统计单词频率。本阶段的subword的粒度是字符。 例如,“ low”的频率为5,那么我们将其改写为“ l o w </ w>”:5
step4.统计每⼀个连续字节对的出现频率,选择最⾼频者合并成新的subword
step5. 重复第4步直到达到第2步设定的subword词表⼤⼩或下⼀个最⾼频的字节对出现频率为1 - WordPiece
step1.准备⾜够⼤的训练语料
step2.确定期望的subword词表⼤⼩
step3.将单词拆分成字符序列
step4.基于第3步数据训练语⾔模型
step5.从所有可能的subword单元中选择加⼊语⾔模型后能最⼤程度地
增加训练数据概率的单元作为新的单元
step6.重复第5步直到达到第2步设定的subword词表⼤⼩或概率增量低
于某⼀阈值 - Unigram Language Model
step1.准备⾜够⼤的训练语料
step2.确定期望的subword词表⼤⼩
step3.给定词序列优化下⼀个词出现的概率
step4.计算每个subword的损失
step5.基于损失对subword排序并保留前X%。为了避免OOV,建议保留字符级的单元
step6.重复第3⾄第5步直到达到第2步设定的subword词表⼤⼩或第5步的结果不再变化
基于指针生成网络的解决方案
当前较为主流解决oov问题的方法是基于指针生成的方法。因此,本位重点介绍该方法。
指针生成网络(Pointer Network Generate, PGN)是基于注意力机制和Pointer Network改进的产物。
注意力机制下的seq2seq模型
注意力机制及其在seq2seq模型发挥的作用,此处不再重述,在seq2seq模型中,已做更具体说明。大体流程图如下:
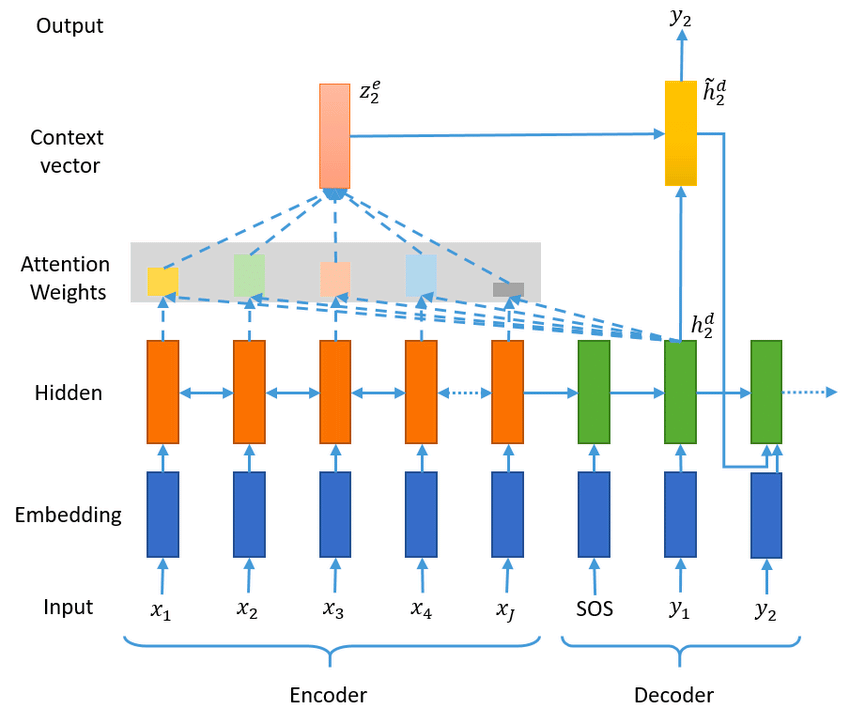
注意力机制下的seq2seq模型可以关注原文本中的相关单词,并依据概率分布生成新单词。
Pointer Network
Pointer network 实际上是Seq2Seq模型中encoder 和decoder的扩展,主要解决的问题是输出的字典长度不固定问题(输出序列的词长度会随着输入序列长度的改变而改变的问题的)。
因此,引出了Pointer Network模型。这种网络结构和seq2seq模型相似,其不同点主要在于:1. 在序列到序列模型中,每一步的预测目标的种类是固定的,但是在 Ptr-Net 中是可变的;2. 在 Ptr-Net 中,通过注意机制来选择(指向)输入序列中的一个来作为输出。即:它不预测输出是什么,而是预测输出(decoder)应该对应输入(encoder)所在的位置。
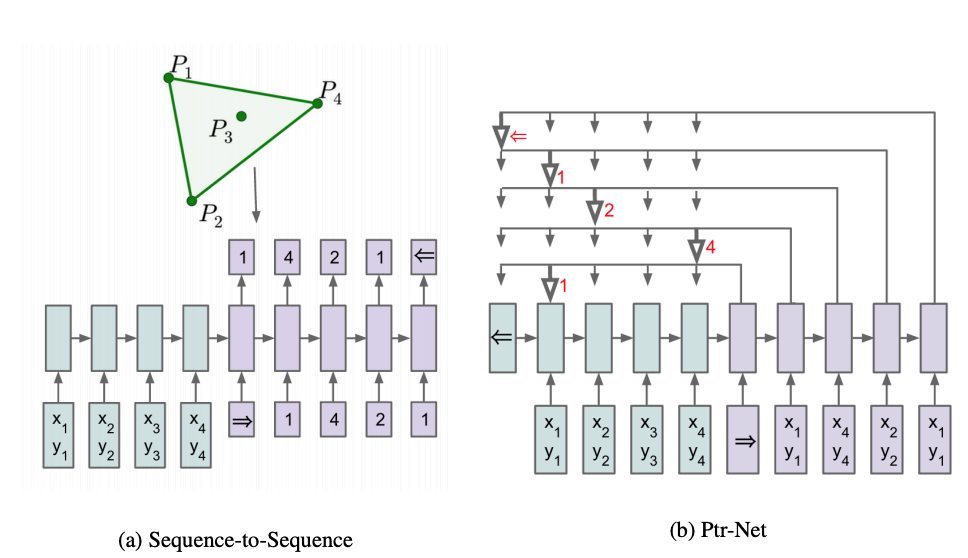
Pointer Network Generator
pointer network预测结果完全来在输入,即encoder部分;而seq2seq模型的输出,完全来自依据decoder的概率分布,生成的内容。因此,Pointer Network Generator结合了两个模型的长处,既具备seq2seq模型的生成能力,又具备Pointer Network的复制能力(复制原文词汇)。其整体流程如下:

从流程图中可以看出,该模型最终得到的概率分布由两部分构成:Attention分布和词汇表分布,并做了加权平均。
如何权衡一个词应该是生成的还是复制的?即由其权重\(P_{gen}\)和\(1 - P_{gen}\)共同决定。其中\(P_{gen}\)计算方法如下:
\(p_{gen} = \sigma(w_{h^*}^T h_t^* + w_s^Ts_t + w_x^Tx_t + b_{ptr})\)。其中,\(h^*\) \(s_t\)来自seq2seq模型的输出。最终概率分布表示如下:
\(P(w) = p_{gen}P_{vocab}(w) + (1 - p_{gen}) \sum_{i:w_i=w} a_i^t\)
其中 \(a_i^t\) 表示的是原文档中的词。我们可以看到解码器一个词的输出概率有其是否拷贝是否生成的概率和决定。当一个词不出现在常规的单词表上时 \(P_{vocab}(w)\) 为0,当该词不出现在文档中\(\sum_{i:w_i=w} a_i^t\)为0。
repetition问题及解决方法
指针生成网络(Pointer-Generator-Network)的创新点主要由两个方面:
- 该通过指向(pointer)从源文本中复制单词,有助于准确地复制信息,同时保留通过生成器产生新单词的能力;
- 使用coverage机制来跟踪已总结的内容,防止重复。
Coverage Mechanism
Coverage Mechanism是将先前时间步的注意力权重加到一起,得到所谓的覆盖向量\(c_t\)(coverage vector)。用先前的注意力权重,来影响当前注意力权重的决策,这样就避免在同一位置重复,从而避免重复生成文本。计算方法如下:
\(c^t = \sum_{t'=0}^{t-1}a^{t'}\)
最终得到的注意力权重计算方式如下:
\(e_i^t = v^T tanh(W_{h}h_i + W_{s}s_t + w_{c}c_i^t + b_{attn})\)
为coverage vector添加损失coverage loss,其计算方式为:
\(covloss_{t} = \sum_{i}min(a_i^t, c_i^t)\)
因此,最终的损失函数为:
\(loss_t = -logP(w_t^*) + \lambda \sum_{i}min(a_i^t, c_i^t)\)
文本摘要在工业中的应用案例
Multi-Source Pointer-Generator Network
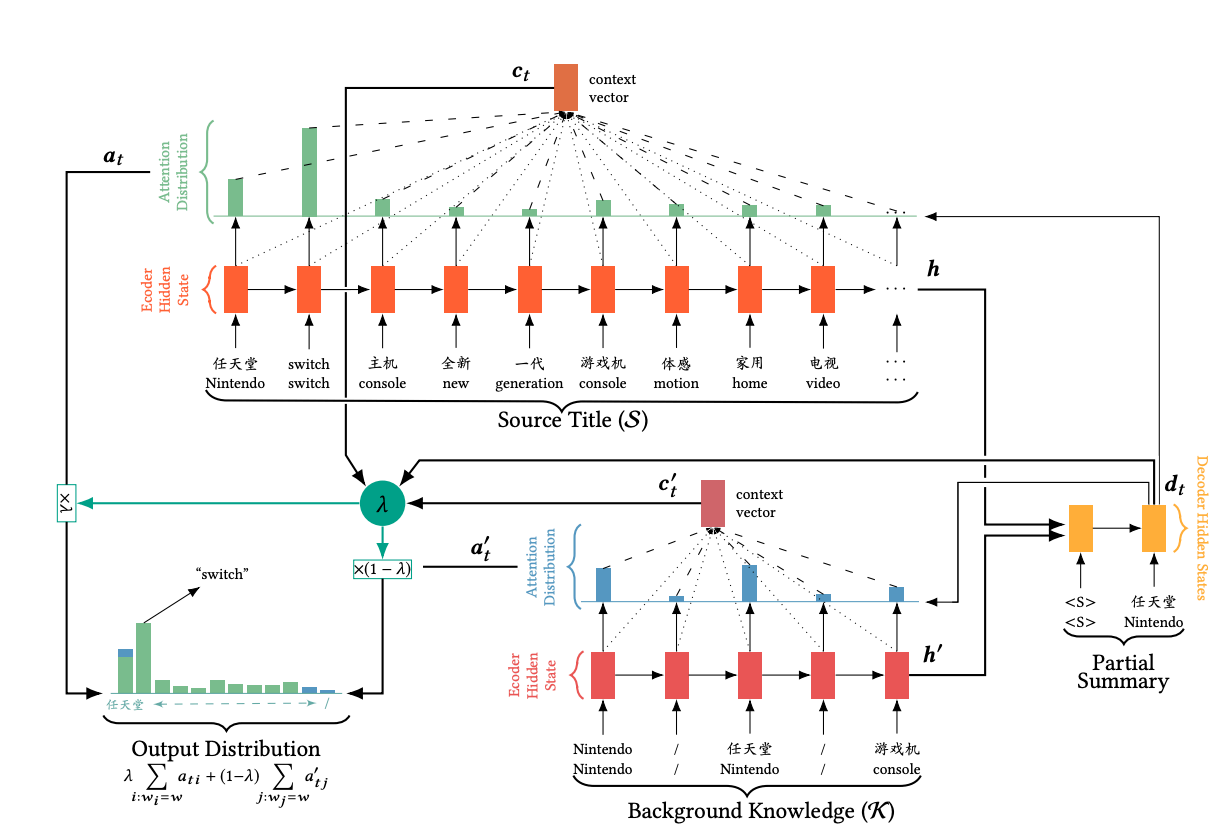
该文主要关注电商平台上的商品摘要的生成。这种摘要与传统的句子摘要有一定的区别和局限,即商品摘要无法容忍事实细节的错误或关键信息的丢失。因此本文提出了商品摘要的两个限制:
- 不介绍无关信息
- 保留关键信息(如品牌和商品名称)
因此,作者在原PGN的基础上,提出了带新知识编码器的多源指针网络来解决这个问题。
超参数调参及常用编码经验等问题
手动调参总结
编码
• 将各个参数的设置部分集中在⼀起。如果参数的设置分布在代码的各个地⽅,
那么修改的过程想必会⾮常痛苦。
• 可以输出模型的损失函数值以及训练集和验证集上的准确率
• 可以考虑设计⼀个⼦程序,可以根据给定的参数,启动训练并监控和周期性保存评估结果。再由⼀个主程序,分配参数以及并⾏启动⼀系列⼦程序。
复现
• 建议先参考相关论⽂,以论⽂中给出的参数作为初始参数。⾄少论⽂中的参数,是个不差的结果。
• 如果找不到参考,那么只能⾃⼰尝试了。可以先从⽐较重要,对实验结果影响⽐较⼤的参数开始,同时固定其他参数,得到⼀个差不多的结果以后,在这个结果的基础上,再调其他参数。例如学习率⼀般就⽐正则值,dropout值重要的话,学习率设置的不合适,不仅结果可能变差,模型甚⾄会⽆法收敛。
• 如果实在找不到⼀组参数让模型收敛。那么就需要检查,是不是其他地⽅出了问题,例如模型实现,数据等等。
实验加速
• 对训练数据进⾏采样。例如原来100W条数据,先采样成1W,进⾏实验看看。
• 减少训练类别。例如⼿写数字识别任务,原来是10个类别,那么我们可以先在2个类别上训练,看看结果如何。
HP Range
• 建议优先在对数尺度上进⾏超参数搜索。
⽐较典型的是学习率和正则化项,我们可以从诸如0.001 0.01 0.1 1 10,以10为阶数进⾏尝试。因为他们对训练的影响是相乘的效果。不过有些参数,还是建议在原始尺度上进⾏搜索,例如dropout值: 0.3 0.5 0.7)。
实验次数
• learning rate: 1 0.1 0.01 0.001, ⼀般从1开始尝试。很少见learning rate⼤于10的。学习率⼀般要随着训练进⾏衰减。衰减系数⼀般是0.5。衰减时机,可以是验证集准确率不再上升时,或固定训练多少个周期以后。不过更建议使⽤⾃适应梯度的办法,例如adam,adadelta,rmsprop等,这些⼀般使⽤相关论⽂提供的默认值即可,可以避免再费劲调节学习率。对RNN来说,有个经验,如果RNN要处理的序列⽐较长,或者RNN层数⽐较多,那么learning rate⼀般⼩⼀些⽐较好,否则有可能出现结果不收敛,甚⾄Nan等问题。
• ⽹络层数: 先从1层开始。
• 每层结点数: 16 32 128,超过1000的情况⽐较少见。超过1W的从来没有见过。
• batch size: 128上下开始。batch size值增加,的确能提⾼训练速度。但是有可能收敛结果变差。如果显存⼤⼩允许,可以考虑从⼀个⽐较⼤的值开始尝试。因为batch size太⼤,⼀般不会对结果有太⼤的影响,⽽batch size太⼩的话,结果有可能很差。
• clip c(梯度裁剪): 限制最⼤梯度,其实是value = sqrt(w12+w22….),如果value超过了阈值,就算⼀个衰减系系数,让value的值等于阈值: 5,10,15
• dropout: 0.5
• L2正则:1.0,超过10的很少见。
• 词向量embedding⼤⼩:128,256
• 正负样本⽐例: 这个是⾮常忽视,但是在很多分类问题上,又⾮常重要的参数。很多⼈往往习惯使⽤训练数据中默认的正负类别⽐例,当训练数据⾮常不平衡的时候,模型很有可能会偏向数⽬较⼤的类别,从⽽影响最终训练结果。除了尝试训练数据默认的正负类别⽐例之外,建议对数⽬较⼩的样本做过采样,例如进⾏复制。提⾼他们的⽐例,看看效果如何,这个对多分类问题同样适⽤。
• 在使⽤mini-batch⽅法进⾏训练的时候,尽量让⼀个batch内,各类别的⽐例平衡,这个在图像识别等多分类任务上⾮常重要。
loss不下降问题
• train loss 不断下降,test loss不断下降,说明⽹络仍在学习;
• train loss 不断下降,test loss趋于不变,说明⽹络过拟合;
• train loss 趋于不变,test loss不断下降,说明数据集100%有问题;
• train loss 趋于不变,test loss趋于不变,说明学习遇到瓶颈,需要减⼩学习率或批量数⽬;
• train loss 不断上升,test loss不断上升,说明⽹络结构设计不当,训练超参数设置不当,数据集经过清洗等问题
自动调参
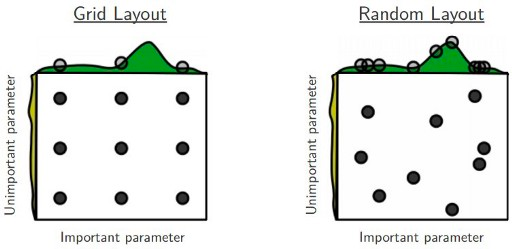
穷举搜索
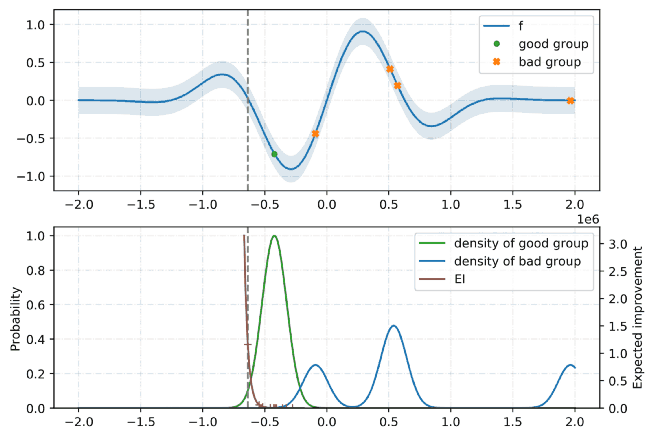
代理模型(surrogate model)
工具
tensorflow自动调参参考
pytorch自动调参参考
autoML 平台
https://github.com/tensorflow/adanet
https://github.com/h2oai/h2o-3