Python 正则表达式
下图列出了Python支持的正则表达式元字符和语法:
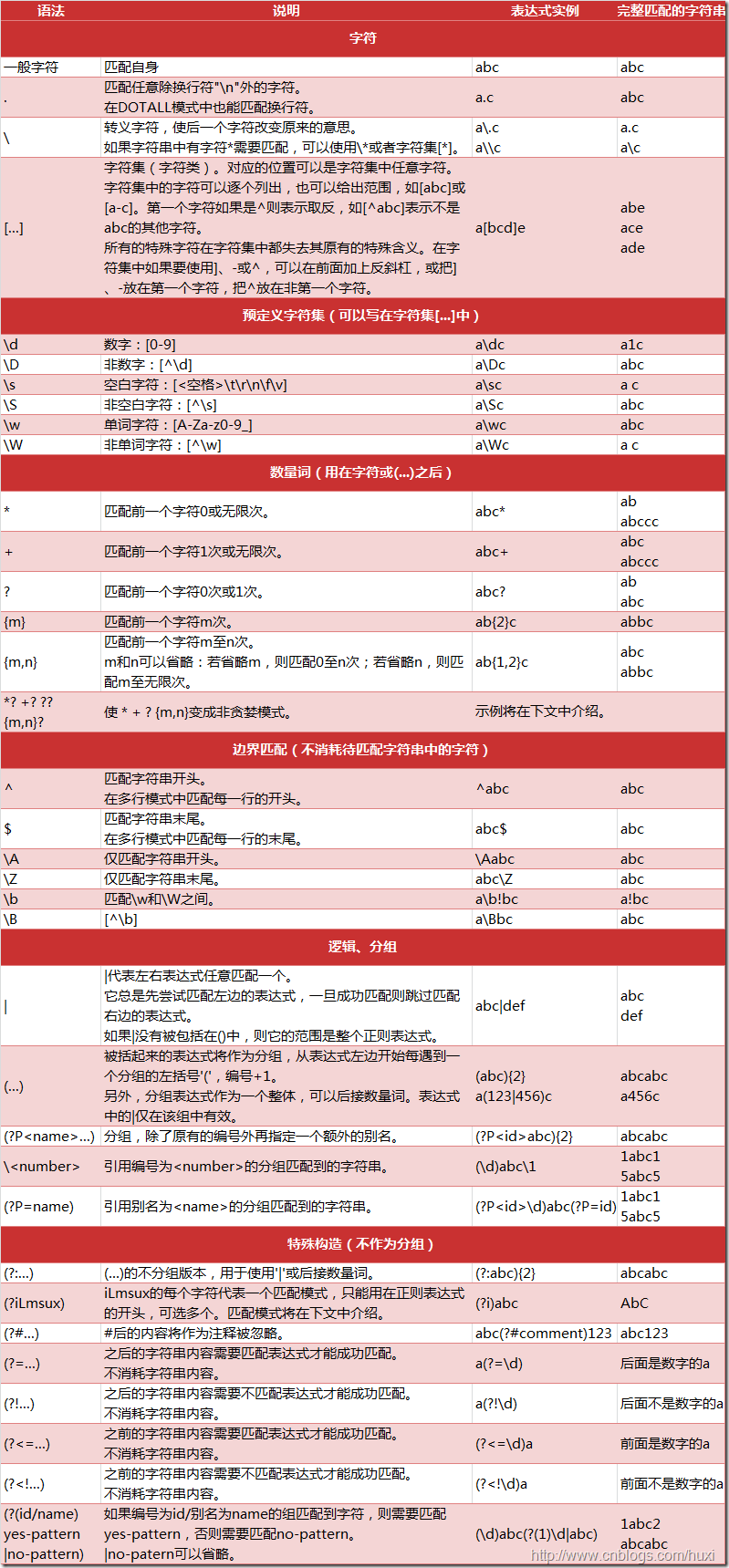
1、数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式"ab*"如果用于查找"abbbc",将找到"abbb"。而如果使用非贪婪的数量词"ab*?",将找到"a"。
2、反斜杠/转意
与大多数编程语言相同,正则表达式里使用""作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\"表示。同样,匹配一个数字的"\d"可以写成r"d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
3、匹配标志/修饰符
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志:

4、re模块
Python通过re模块提供对正则表达式的支持
re模块常用的方法/操作
1、re.compile(strPattern[, flag]) #将pattern规则编译到一个对象中
#!/usr/bin/env python # -*- coding:utf-8 -*- import re str = "333fAfjoijo444324232DWdd44433" Pattern = re.compile(r"d{3}w{3}", re.I) # 将正则表达式的模式编译到一个对象中 ret = Pattern.findall(str) # 通过该对象直接调用要使用的方法 print(ret)
2、匹配
Match对象是一次匹配的结果,包含了很多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。
属性:
- string: 匹配时使用的文本。
- re: 匹配时使用的Pattern对象。
- pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。
- lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
方法:
- group([group1, …]):
- 获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。
- groups([default]):
- 以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。
- groupdict([default]):
- 返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。
- start([group]):
- 返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。
- end([group]):
- 返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。
- span([group]):
- 返回(start(group), end(group))。
- expand(template):
- 将匹配到的分组代入template中然后返回。template中可以使用id或g<id>、g<name>引用分组,但不能使用编号0。id与g<id>是等价的;但10将被认为是第10个分组,如果你想表达1之后是字符'0',只能使用g<1>0。
#!/usr/bin/env python # -*- coding:utf-8 -*- import re str = "123ABc456" ret = re.search(r"(d+)(?P<name>w+)", str, re.I) # 将正则表达式的模式编译到一个对象中 # 以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。 print(ret.groups()) # ('123', 'ABc456') # 获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。 print(ret.group(1)) # 123 # 匹配时使用的文本。 print(ret.string) # 123ABc456 # re: 匹配时使用的Pattern对象。 print(ret.re) # re.compile('(\d+)(\w+)', re.IGNORECASE) # 返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。 print(ret.start(1)) # 0 # 返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。 print(ret.end(1)) # 3 # pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。 print(ret.pos) # 0 # endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。 print(ret.endpos) # 9 # lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。 print(ret.lastgroup) # # lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。 print(ret.lastindex) # 2 # 返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。 print(ret.groupdict()) # {'name': 'ABc456'} # 返回(start(group), end(group))。 print(ret.span(2)) # (3, 9) # 将匹配到的分组代入template中然后返回。template中可以使用id或g<id>、g<name>引用分组,但不能使用编号0。id与g<id>是等价的;但10将被认为是第10个分组,如果你想表达1之后是字符'0',只能使用g<1>0。 print(ret.expand(r"2 2"))
3、Pattern
Pattern对象是一个编译好的正则表达式,通过Pattern提供的一系列方法可以对文本进行匹配查找。
Pattern不能直接实例化,必须使用re.compile()进行构造。
Pattern提供了几个可读属性用于获取表达式的相关信息:
- pattern: 编译时用的表达式字符串。
- flags: 编译时用的匹配模式。数字形式。
- groups: 表达式中分组的数量。
- groupindex: 以表达式中有别名的组的别名为键、以该组对应的编号为值的字典,没有别名的组不包含在内。
#!/usr/bin/env python # -*- coding:utf-8 -*- import re p = re.compile(r'(w+) (w+)(?P<sign>.*)', re.DOTALL) print("p.pattern: %s" % p.pattern) print("p.flags: %s" % p.flags) print("p.groupindex: %s" % p.groupindex) print("p.groups: %s " % p.groups) 运行结果: hello
实例方法[ | re模块方法]:
re.match(pattern, string[, flags]): # 只从开头匹配,未匹配返回NONE
import re pattern = re.compile(r'w+') match = pattern.match('hello world!') print(match.group())
运行结果:
hello
re.findall(pattern, string[, flags]) # 找到所有匹配的内容,以字符串的形式放在列表中
import re pattern = re.compile(r'w+') match = pattern.findall('hello world!') print(match)
运行结果:
['hello', 'world']
re.search(pattern, string, flags=0) # 找到匹配的第一个内容
import re pattern = re.compile(r'world') match = pattern.search('hello world!') print(match.group())
运行结果:
world
re.sub(pattern, repl, string[, count]) #使用repl替换string中每一个匹配的子串后返回替换后的字符串,count用于指定最多替换次数,不指定时全部替换。
import re str = "123abc" pattern = re.compile(r'(d+)(w+)') ret = pattern.sub(r"21",str) #repl可以引用分组索引 print(ret) 运行结果: abc123 # 调换分组的位置
re.split(pattern, string[, maxsplit]) #按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。
#!/usr/bin/env python # -*- coding:utf-8 -*- import re str = "123aaabc23の2eaa23の2の2esdcdsaaffaa" pattern = re.compile(r'd') ret1 = pattern.split(str, 3) #用模式匹配到的内容来分割字符串,最多分割3次 ret2 = pattern.split(str) #用模式匹配到的内容来分割字符串 print(ret1) # 序列 print(ret2) # 运行结果: ['', '', '', 'aaabc23の2eaa23の2の2esdcdsaaffaa'] ['', '', '', 'aaabc', '', 'の', 'eaa', '', 'の', 'の', 'esdcdsaaffaa']
re.finditer(pattern, string[, flags]) #将匹配的内容返回至一个可迭代的对象中
import re str = "123aaabc23の2eaa23の2の2esdcdsaaffaa" ret = re.finditer(r'd+', str) for i in ret: print(i.group()) # 运行结果: 123 23 2 23 2 2