非索引列上的统计
有时候,可能在连接或过滤条件中的列上没有索引。即使对这种非索引列,如果查询优化器知道这些列的数据分布(统计),它也很可能做出最佳的选择。
除了索引上的统计,SQL Server可以在没有索引的列上建立统计。即使不是索引列,当你开启了SQL Server自动创建统计功能,SQL Server就自动在执行WHERE、JOIN等查询列上创建统计。数据分布的信息或者特定值出现在非索引列上的可能性,都能够帮助查询优化器确定最优的处理策略。即使查询优化器不能真正使用索引来定位这些列,这也仍然对其有利。如果SQL Server确信这些信息对创建更好的计划有利(这通常发生于这些列被用于一个断言时),则自动在非索引列上创建统计。默认情况下,在非索引列上创建统计是被开启的。它可以通过属性=》选项=》数据库自动创建统计设置来配置。可以使用ALTER DATABASE命令来编程覆盖这个设置。但是,为了更好的性能,建议保持这个特性开启。
下面来一个实战,以确定这个非索引列的统计也是有用的。首先,建两张表ta1,ta2分别都有十万行数据,但是反差很大,其中ta1的column2中只有一行为1,其余行全部为2。ta2正好相反。在这两个列上都没有索引。
大致的样子如下:

执行如下SQL语句:
SELECT ta1.column2,ta2.column4 FROM ta1 JOIN ta2 ON ta1.column2 = ta2.column4 WHERE ta1.column2 = 2
来看执行计划与I/O情况:
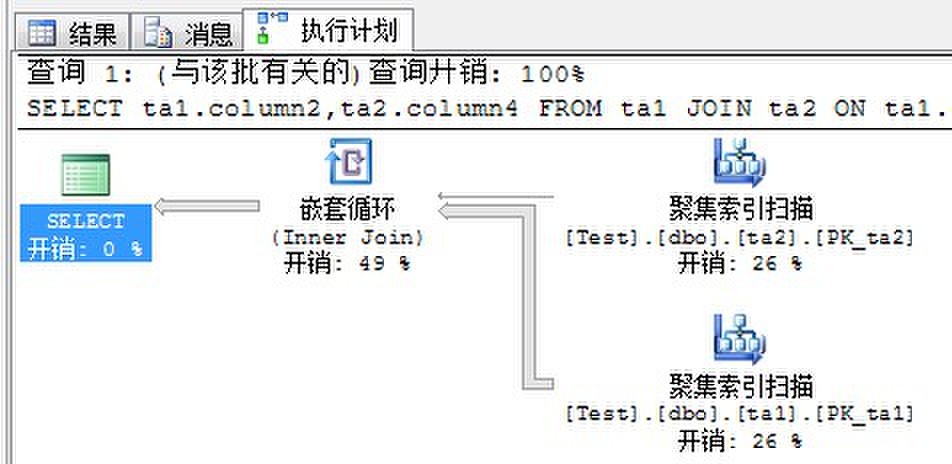
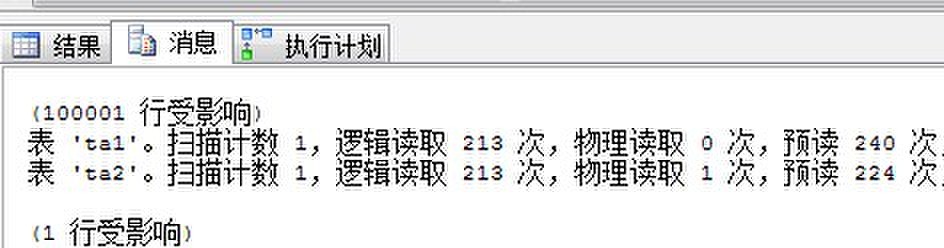
有对比才能知道哪个更好,假如SQL Server没有统计信息又会如何执行呢?
我们先执行如下操作:

--关闭自动统计功能 ALTER DATABASE Test SET AUTO_CREATE_STATISTICS OFF --查看ta1表上的统计信息 sp_helpstats 'ta1' --查看ta2表上的统计信息 sp_helpstats 'ta2' --卸载ta1表上的统计 DROP STATISTICS dbo.ta1._WA_Sys_00000002_0BC6C43E --卸载ta2表上的统计 DROP STATISTICS ta2._WA_Sys_00000002_0DAF0CB0
我们再执行相同的语句:

我们看到上面的执行计划有很多的叹号,这是尽职的SQL Server对缺少统计的提示。
鼠标单击某个有叹号的执行计划:
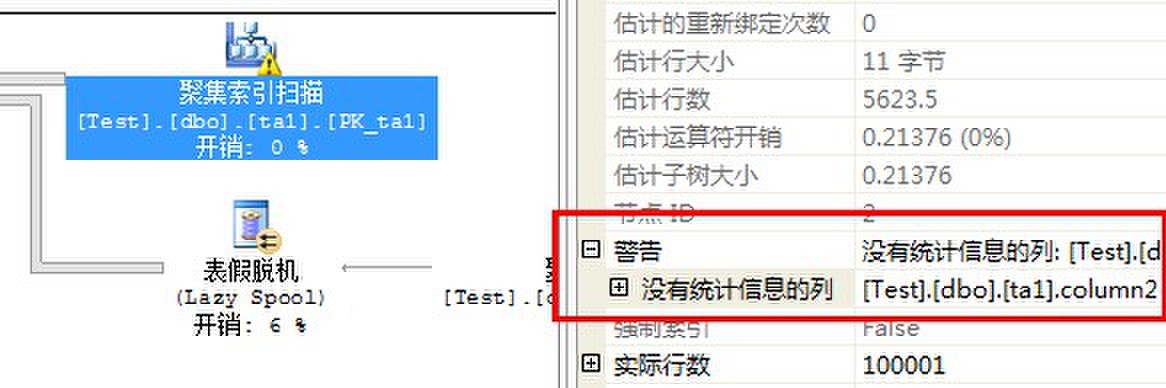
属性里也给出了提示,再来看看I/O:
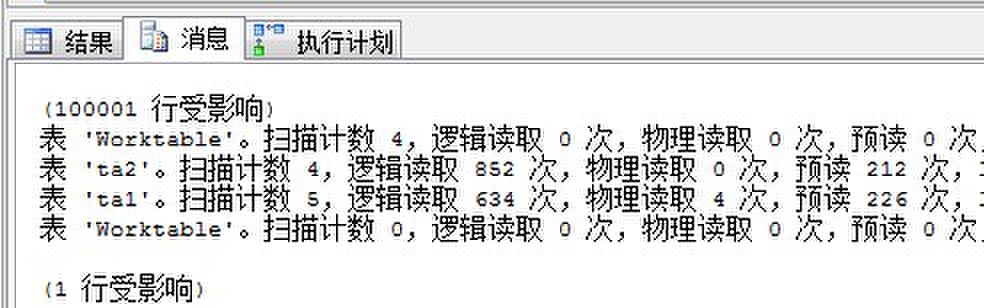
各种读都增加了。
小结:
保留SQL Server默认的统计信息,但一般情况下不用关心它。除非查询性能变得慢,可以手动更新统计信息。
