参考:https://www.cnblogs.com/fnng/p/3581433.html
什么是xml
xml即可扩展标记语言,它可以用来标记数据,定义数据类型,是一种允许用户对自己的编辑语言进行定义的源语言。
测试 adc.xml
<?xml version="1.0" encoding="utf-8"?>
<catalog>
<maxid>4</maxid>
<login username="pytest" passwd='123456'>
<caption>Python</caption>
<item id="4">
<caption>测试</caption>
</item>
</login>
<item id="2">
<caption>Zope</caption>
</item>
</catalog>
Ok ,从结构上,它很像我们常见的HTML超文本标记语言。但他们被设计的目的是不同的,超文本标记语言被设计用来显示数据,其焦点是数据的外观。它被设计用来传输和存储数据,其焦点是数据的内容。
那么它有如下特征:
首先,它是有标签对组成 <aa> </aa>
标签可以有属性: <aa id='123'> </aa>
标签可以嵌入数据:<aa>abc</aa>
标签可以嵌入子标签(具有层级关系)
<aa>
<bb></bb>
</aa>
获得标签属性
那么,下面我们介绍如何用python来读取这种类型的文件
# coding=utf-8
# 导入模块
import xml.dom.minidom
# 打开xml文档
dom = xml.dom.minidom.parse('abc.xml')
#得到文档元素对象
root = dom.documentElement
# 节点名称
print(root.nodeName)
# catalog
# 节点值,只对文件节点有效
print(root.nodeValue)
# None
# 节点类型
print(root.nodeType)
# 1
print(root.ELEMENT_NODE)
# 1
如果xml文档不是文件而是str则使用以下方法获得对象文档
xml.dom.minidom.parseString(str)
无需使用documentElement这个属性
注意:测试文件abc.xml和脚本放置在同一个文件夹下,并且脚本运行目录也是在该文件夹下,否则可能找不到文件
vscode终端的路径需要到当前脚本的路径,如下图
mxl.dom.minidom模块用来处理xml文件,所以要先引入。
xml.dom.minidom.parse() 用于打开一个xml文件,并将这个文件对象赋值给dom变量。
documentElement 用于得到dom对象的文档元素,并把获得的对象给赋值给root变量。
每一个结点都有它的nodeName,nodeValue,nodeType属性。
nodeName为结点名字。
nodeValue是结点的值,只对文本结点有效。
nodeType是结点的类型。catalog是ELEMENT_NODE类型
现在有以下几种:
'ATTRIBUTE_NODE'
'CDATA_SECTION_NODE'
'COMMENT_NODE'
'DOCUMENT_FRAGMENT_NODE'
'DOCUMENT_NODE'
'DOCUMENT_TYPE_NODE'
'ELEMENT_NODE'
'ENTITY_NODE'
'ENTITY_REFERENCE_NODE'
'NOTATION_NODE'
'PROCESSING_INSTRUCTION_NODE'
'TEXT_NODE'
NodeTypes - 有名常数
http://www.w3school.com.cn/xmldom/dom_nodetype.asp
获得子标签
现在要获得catalog的子标签,对于知道元素名字的子元素,可以使用getElementsByTagName方法获取
例如获取元素名为maxid和login的子标签
#得到文档元素对象
root = dom.documentElement
# 获取的还是DOM对象,生成列表,有多少个同名子标签则有多少个列表元素
# 'maxid'只有一个元素
bb = root.getElementsByTagName('maxid')
# 把列表的第一个元素赋值给b
b = bb[0]
# 打印子元素的nodeName属性
print(b.nodeName)
# maxid
bb = root.getElementsByTagName('login')
b = bb[0]
print(b.nodeName)
# login
如何区分相同标签名字的标签
<caption>和<item>标签不止一个如何区分?
# 区分相同名字标签,使用下标
import xml.dom.minidom
#打开xml文档
dom = xml.dom.minidom.parse('abc.xml')
#得到文档元素对象
root = dom.documentElement
bb = root.getElementsByTagName('caption')
# 第三个
b= bb[2]
print(b.nodeName)
# caption
bb = root.getElementsByTagName('item')
# 第二个
b= bb[1]
print(b.nodeName)
# item
root.getElementsByTagName('caption') 获得的是标签为caption 一组标签,b[0]表示一组标签中的第一个;b[2] ,表示这一组标签中的第三个。
获得标签属性值
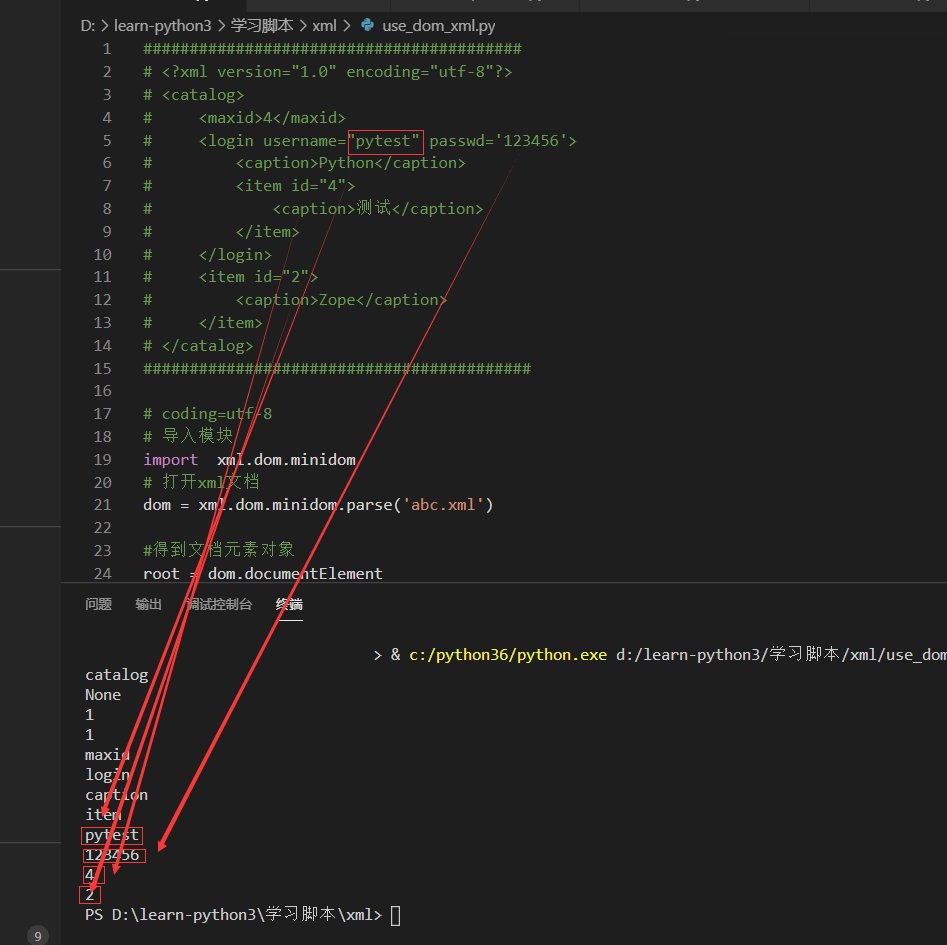
<login>和<item>标签是有属性的,如何获得他们的属性?
获取标签login的属性值username和passwd以及标签item的id值
# 获取标签属性值
import xml.dom.minidom
#打开xml文档
dom = xml.dom.minidom.parse('abc.xml')
#得到文档元素对象
root = dom.documentElement
# 查找'login'
itemlist = root.getElementsByTagName('login')
# 找到的第一个元素赋值给item
item = itemlist[0]
# 获取标签的属性值username
un=item.getAttribute("username")
print(un)
# pytest
pd=item.getAttribute("passwd")
print(pd)
# 123456
ii = root.getElementsByTagName('item')
i1 = ii[0]
i=i1.getAttribute("id")
print(i)
# 4
i2 = ii[1]
i=i2.getAttribute("id")
print(i)
# 2
对应关系如下
获取标签直接的数据
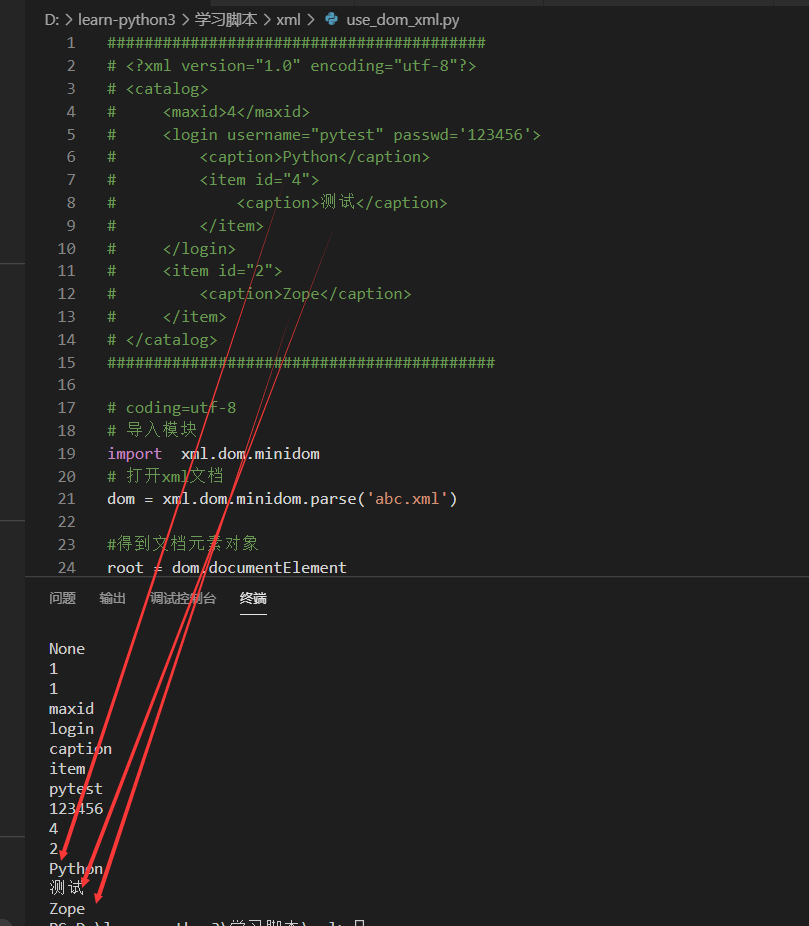
<caption> </caption>标签之间是有数据的,如何获得这些数据
获得标签之间数据有多种方法
方法一
# 获取标签之间的数据
# 获取标签属性值
import xml.dom.minidom
#打开xml文档
dom = xml.dom.minidom.parse('abc.xml')
#得到文档元素对象
root = dom.documentElement
cc = root.getElementsByTagName('caption')
c1 = cc[0]
print(c1.firstChild.data)
# Python
c2 = cc[1]
print(c2.firstChild.data)
# 测试
c3 = cc[2]
print(c3.firstChild.data)
# Zope
firstChild 属性返回被选节点的第一个子节点,.data表示获取该节点的数据。
对应关系如下
方法二
from xml.etree import ElementTree as ET
per=ET.parse('abc.xml')
p=per.findall('./login/item')
for oneper in p:
for child in oneper.getchildren():
print(child.tag,':',child.text)
p=per.findall('./item')
for oneper in p:
for child in oneper.getchildren():
print(child.tag,':',child.text)
# caption : 测试
# caption : Zope
方法二有点复杂,所引用模块也与前面的不一样,findall用于指定在哪一级标签下开始遍历。
getchildren方法按照文档顺序返回所有子标签。并输出标签名(child.tag)和标签的数据(child.text)
其实,方法二的作用不在于此,它核心功能是可以遍历某一级标签下的所有子标签。