1、小知识点汇总


1 # 赋值后的地址是一样的 2 li1 = [1,2,3] 3 li2 = li1 4 print(li1 is li2)# is 用于判断li1的地址是否和li2的地址一样,结果输出为True 5 print(id(li1))# id()用于输出地址 6 print(id(li2)) 7 # 2440684855944 8 # 2440684855944
在python3中,有小数据池的概念,凡是数字在-5到256之间,他们都共用一个地址,目的是为了节省空间,由于PyCharm的机制原因,不能体现出这种变化,所以我在cmd中实现。

2、编码讲解
以下是各个编码对A和中的表示。注意以下二进制的表示都是随意设置,并无根据,只是为了方便做笔记。
ASCLL码
A : 00000010 8位 一个字节
unicode
A : 00000000 00000001 00000010 00000100 32位 四个字节
中: 00000000 00000001 00000010 00000110 32位 四个字节
utf-8
A : 00100000 8位 一个字节
中: 00000001 00000010 00000110 24位 三个字节
gbk
A : 00000110 8位 一个字节
中 : 00000010 00000110 16位 两个字节
在python2和python3中:
1,各个编码之间的二进制,是不能互相识别的,会产生乱码。
2,文件的储存,传输,不能是unicode(只能是utf-8、utf-16、gbk、gb2312、ASCLL等)
在python3中:
str 在内存中是用unicode编码。Python 3最重要的新特性之一是对字符串和二进制数据流做了明确的区分。文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示。
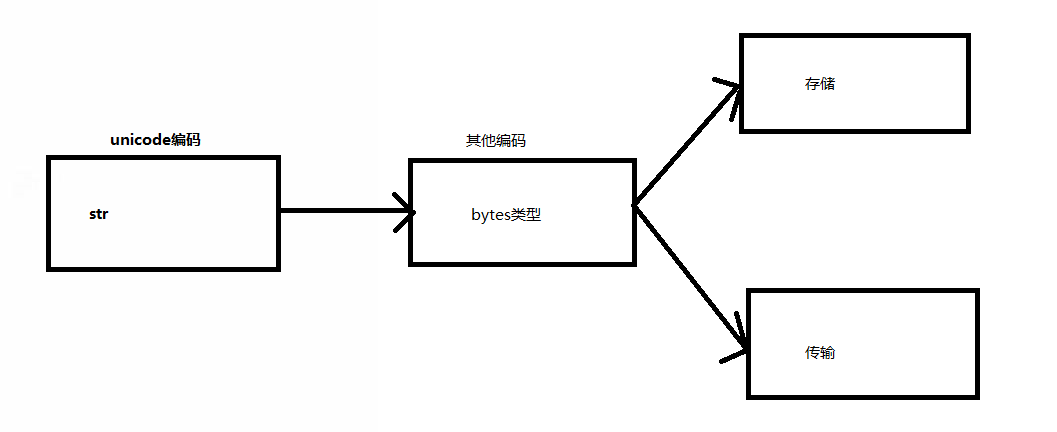
数据的存储和传输,只能由bytes类型进行。
对于英文:
str :表现形式:s = 'alex'
编码方式: 010101010 unicode
bytes :表现形式:s = b'alex'
编码方式: 000101010 utf-8、gbk。。。。
1 s = 'alex' 2 s1 = b'alex' 3 print(s,type(s)) 4 print(s1,type(s1)) 5 # result: 6 # alex <class 'str'> 7 # b'alex' <class 'bytes'>
对于中文:
str :表现形式:s = '中国'
编码方式: 010101010 unicode
bytes :表现形式:s = b'xe4xb8xadxe5x9bxbd'
1 s = '中国' 2 print(s,type(s)) 3 b = bytes(s,encoding='utf-8') 4 print(b)
可以看出这里是用utf-8编码,utf-8是三个字节,中国两个字就有六个字节,故表现形式里面就有了六个。
1 s = '中国' 2 print(s,type(s)) 3 b = bytes(s,encoding='gbk') 4 print(b)
在这里用的是gbk编码,故他的结果是四个:b'xd6xd0xb9xfa'
编码方式: 000101010 utf-8 gbk。。。。
下面是一些编码和解码的操作:
1 #str --->byte encode 编码 2 s = '你好' 3 b = s.encode('utf-8') 4 print(b) 5 #byte --->str decode 解码 6 s1 = b.decode('utf-8') 7 print(s1) 8 9 s = 'abf' 10 b = s.encode('utf-8') 11 print(b) 12 #byte --->str decode 解码 13 s1 = b.decode('gbk') 14 print(s1)