1、 Scala报错 Exception in thread "main" java.lang.reflect.InvocationTargetException scala.Predef$.refArrayOps([Ljava/lang/Object;)Lscala/collection/mutable/ArrayOps;
Exception in thread "main" java.lang.reflect.InvocationTargetException
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at com.intellij.rt.execution.CommandLineWrapper.main(CommandLineWrapper.java:64)
Caused by: java.lang.NoSuchMethodError: scala.Predef$.refArrayOps([Ljava/lang/Object;)Lscala/collection/mutable/ArrayOps;
at com.wxdata.phonecharge.utils.JedisSentinelPoolUtils$.<init>(JedisSentinelPoolUtils.scala:20)
at com.wxdata.phonecharge.utils.JedisSentinelPoolUtils$.<clinit>(JedisSentinelPoolUtils.scala)
at com.wxdata.phonecharge.app.ImportHfSupplierOrderBatch$.main(ImportHfSupplierOrderBatch.scala:13)
at com.wxdata.phonecharge.app.ImportHfSupplierOrderBatch.main(ImportHfSupplierOrderBatch.scala)
... 5 more
代码如下,一个简单的类,但是在启动时即报错,目测应该是环境配置的问题。
def main(args: Array[String]): Unit = {
//val sparkSession = BuildUtils.initSparkSession(true)
// 读取
val redisKey = "data_middle_platform:offset:table_import"
val colOffset: String = JedisSentinelPoolUtils.hget(redisKey, "ImportHfSupplierOrderBatch")
if(StringUtils.isNotBlank(colOffset)){
println("=============")
}
println("-------------")
问题解决:
问题是由于pom文件中配置了Scala的版本,idea中也配置了Scala的版本,二者不一致导致的。
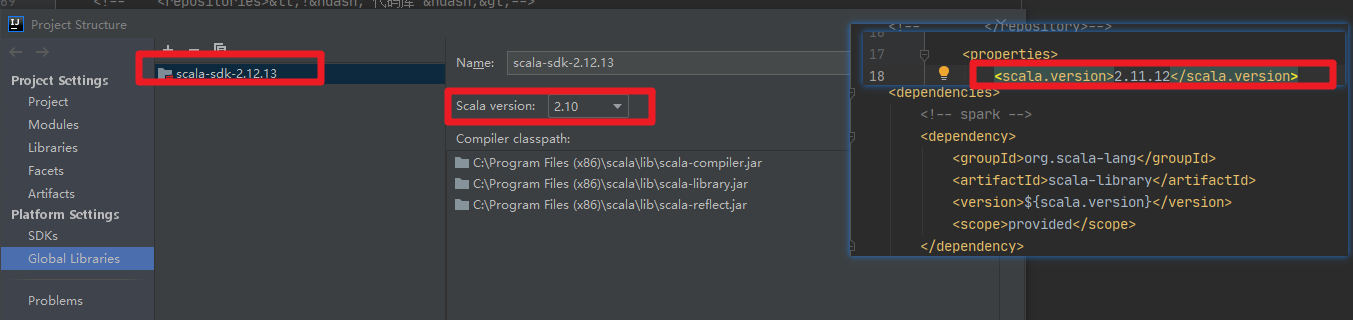
注意:这种情况下,maven会自动下载一个对应版本的scala包,要选择那一个。如选择了一个高本版的本地scala,然后将scala version选择为2.11 ,也可能会出问题,如下所示。
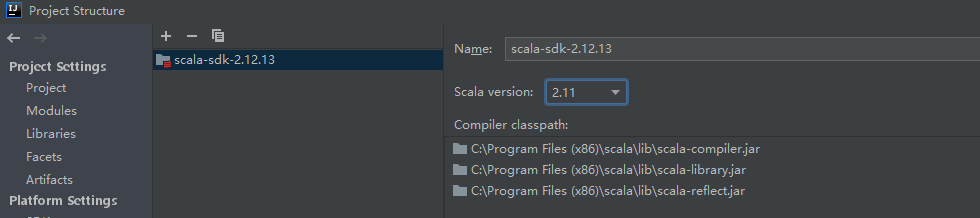
此时仍然报错,和之前错误一样。
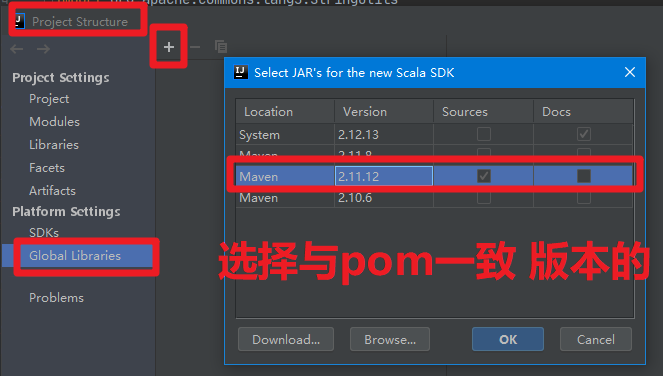
正确配置就是:
2、spark本地运行报错 java.lang.NoClassDefFoundError: org/apache/spark/sql/SparkSession
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/spark/sql/SparkSession
at java.lang.Class.getDeclaredMethods0(Native Method)
at java.lang.Class.privateGetDeclaredMethods(Class.java:2701)
at java.lang.Class.privateGetMethodRecursive(Class.java:3048)
at java.lang.Class.getMethod0(Class.java:3018)
at java.lang.Class.getMethod(Class.java:1784)
at com.intellij.rt.execution.CommandLineWrapper.main(CommandLineWrapper.java:62)
Caused by: java.lang.ClassNotFoundException: org.apache.spark.sql.SparkSession
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 6 more
原因是NoClassDefFoundError表示在运行时找不到类,
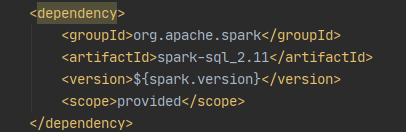
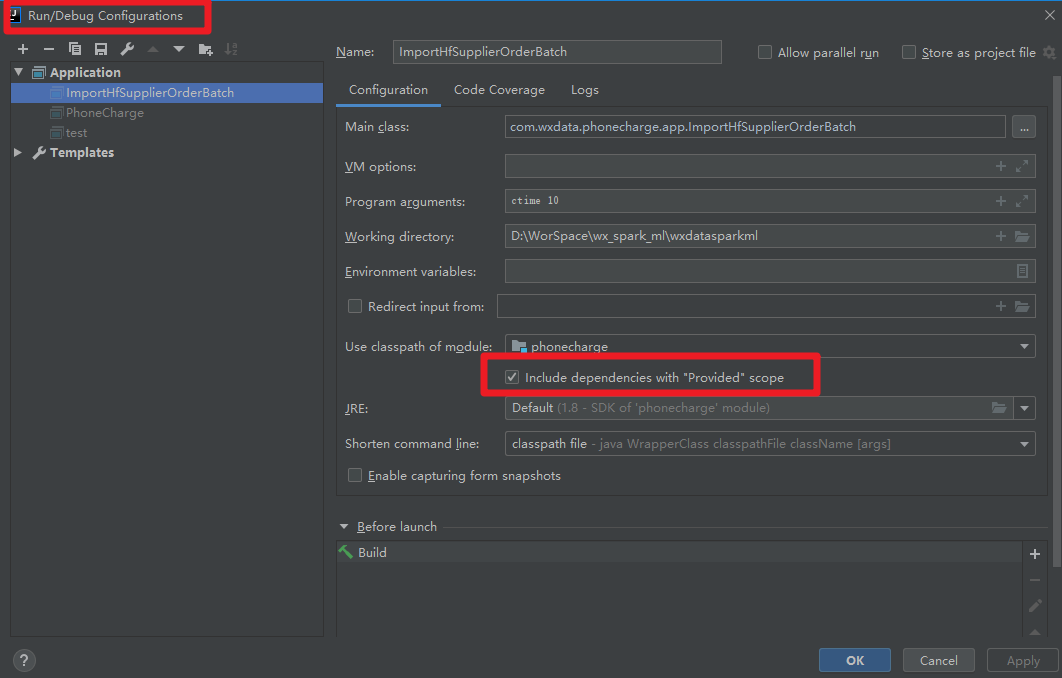
或者:编辑启动参数,将图中的√打上即可。
3、spark在读取或写入json和csv时报 java.lang.IllegalArgumentException: Illegal pattern component: XXX
测试代码为:
val frame = WXSource.readData(sparkSession, "mysql", "select e_avg_profit_rate from `data_middle_platform`.`test_phone_charge` limit 10")
frame.show()
frame.write
.option("header", "false")
.mode(SaveMode.Append)
.csv("file:///D:\WorSpace\wx_spark_ml\wxdatasparkml\phonecharge\src\main\resources\data\a.csv")
具体保存信息为:
Exception in thread "main" java.lang.reflect.InvocationTargetException
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at com.intellij.rt.execution.CommandLineWrapper.main(CommandLineWrapper.java:64)
Caused by: java.lang.IllegalArgumentException: Illegal pattern component: XXX
at org.apache.commons.lang3.time.FastDatePrinter.parsePattern(FastDatePrinter.java:282)
at org.apache.commons.lang3.time.FastDatePrinter.init(FastDatePrinter.java:149)
at org.apache.commons.lang3.time.FastDatePrinter.<init>(FastDatePrinter.java:142)
at org.apache.commons.lang3.time.FastDateFormat.<init>(FastDateFormat.java:384)
at org.apache.commons.lang3.time.FastDateFormat.<init>(FastDateFormat.java:369)
at org.apache.commons.lang3.time.FastDateFormat$1.createInstance(FastDateFormat.java:91)
at org.apache.commons.lang3.time.FastDateFormat$1.createInstance(FastDateFormat.java:88)
at org.apache.commons.lang3.time.FormatCache.getInstance(FormatCache.java:82)
at org.apache.commons.lang3.time.FastDateFormat.getInstance(FastDateFormat.java:165)
at org.apache.spark.sql.execution.datasources.csv.CSVOptions.<init>(CSVOptions.scala:139)
at org.apache.spark.sql.execution.datasources.csv.CSVOptions.<init>(CSVOptions.scala:41)
at org.apache.spark.sql.execution.datasources.csv.CSVFileFormat.prepareWrite(CSVFileFormat.scala:72)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.write(FileFormatWriter.scala:103)
at org.apache.spark.sql.execution.datasources.InsertIntoHadoopFsRelationCommand.run(InsertIntoHadoopFsRelationCommand.scala:159)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult$lzycompute(commands.scala:104)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult(commands.scala:102)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.doExecute(commands.scala:122)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:131)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:127)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:155)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:152)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:127)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:80)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:80)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:668)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:668)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:78)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:125)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:73)
at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:668)
at org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:276)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:270)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:228)
at org.apache.spark.sql.DataFrameWriter.csv(DataFrameWriter.scala:656)
at test1$.main(test1.scala:30)
at test1.main(test1.scala)
... 5 more
问题分析:
1.此问题经常出现在spark2.1.x升级到spark2.2.x的时候出现。比如通过maven构建spark环境的时候,依赖maven进行版本升级。
maven升级的时候,没有自动加载完整依赖包,jsonAPI对于timeStampFormat有特殊需求,默认为yyyy-MM-dd'T'HH:mm:ss.SSSXXX这种格式,是无法被scala-lang包识别的。
2.此问题出现在调用spark.read.json或者csv的时候出现。
问题解决
在读取/写入json/csv时添加.option("timestampFormat", "yyyy/MM/dd HH:mm:ss ZZ")
frame.write
.option("header", "false")
.option("timestampFormat", "yyyy/MM/dd HH:mm:ss ZZ")
.mode("append")
.mode(SaveMode.Append)
.csv("file:///D:\WorSpace\wx_spark_ml\wxdatasparkml\phonecharge\src\main\resources\data\a.csv")
默认生成如下图所示:
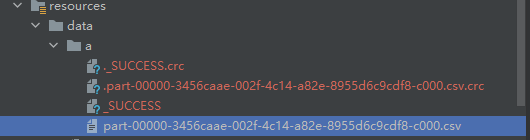
Spark使用Hadoop文件格式,需要对数据进行分区-这就是为什么写出文件名为part-文件的原因。
如果需要重命名为自己需要的名字,可以写出后再处理,也可以通过自定义outputformat的方式来实现。