
原文传送门:请点击
现在计算机中,在内存中采用unicode编码方式。

可以看到上图中,字节型数据t并没有像想象中的一样显示0,1字符串。显示仍然是b,这是因为t是采用utf-8来编码,而utf-8与unicode编码中的字符部分的编码方式是一样的,因此在显示t的时候,在内存中采用unicode解码,而两种编码方式的字符部分一样,因此显示并没有什么区别。
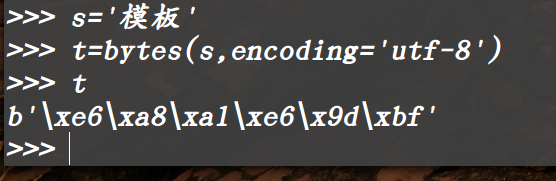
在这幅图中,可以直观的看到t是0,1数据串,这里为了便于观看,显示的是16进制,utf-8与unicode汉字部分的编码是不一样的,unicode无法进行解码,因此这里的t只能用0,1串来显示。
在python3中提供了,encode()和decode()两个函数,
encode()函数:将unicode编码转换成其他的编码方式。
decode()函数:将其他编码方式转换成unicode编码方式。
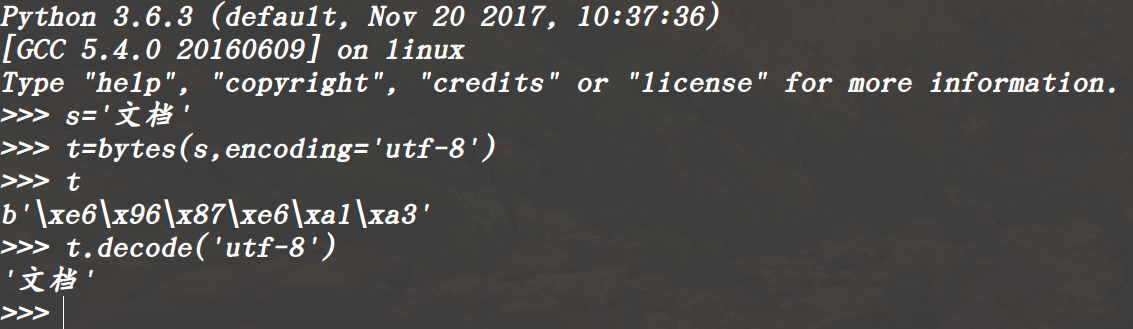
大家知道unicode的存储效率低,会浪费很多空间,因此在保存文本时,很多时候并不是用unicode编码方式,有很多其他的编码,utf-8,gbk,还有日文,韩文编码等,下面以读取一个用utf-8的文本为例:
首先将utf-8转换成unicode编码方式,然后再来译码。
简单来说,就是计算机内存中是以unicode编码为桥梁的。

如果说从从其他编码方式转换成unicode这一过程出错,就会产生乱码,例如文本使用日文编码保存的,你用gbk来解码就会产生乱码。