Sphinx是什么
Sphinx是一个全文检索引擎。
Why/为什么使用Sphinx
遇到的使用场景
遇到一个类似这样的需求:用户可以通过文章标题和文章搜索到一片文章的内容,而文章的标题和文章的内容分别保存在不同的库,而且是跨机房的。
可选方案
A、直接在数据库实现跨库LIKE查询
优点:简单操作 缺点:效率较低,会造成较大的网络开销
B、结合Sphinx中文分词搜索引擎
优点:效率较高,具有较高的扩展性 缺点:不负责数据存储
使用Sphinx搜索引擎对数据做索引,数据一次性加载进来,然后做了所以之后保存在内存。这样用户进行搜索的时候就只需要在Sphinx服务器上检索数据即可。而且,Sphinx没有MySQL的伴随机磁盘I/O的缺陷,性能更佳。
Sphinx的工作原理
Sphinx的整个工作流程就是Indexer程序到数据库里面提取数据,对数据进行分词,然后根据生成的分词生成单个或多个索引,并将它们传递给searchd程序。然后客户端可以通过API调用进行搜索。
Sphinx工作流程图:
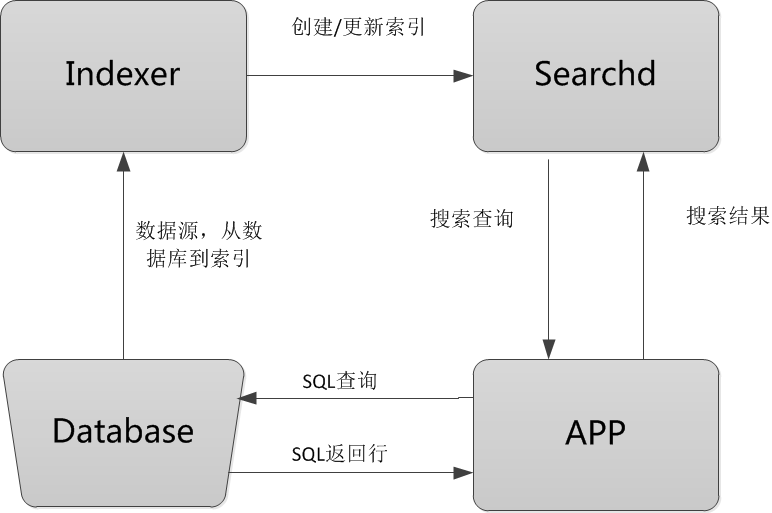
流程图解释:
- Database:数据源,是Sphinx做索引的数据来源。因为Sphinx是无关存储引擎、数据库的,所以数据源可以是MySQL、PostgreSQL、XML等数据。
- Indexer:索引程序,从数据源中获取数据,并将数据生成全文索引。可以根据需求,定期运行Indexer达到定时更新索引的需求。
- Searchd:Searchd直接与客户端程序进行对话,并使用Indexer程序构建好的索引来快速地处理搜索查询。
- APP:客户端程序。接收来自用户输入的搜索字符串,发送查询给Searchd程序并显示返回结果。
Sphinx的配置
数据源配置
source test //source后面跟着的是数据源的名字,后面做索引的时候会用到;
#sql_attr_uint = media_type_u //索引属性,整形
sql_attr_uint = role
#sql_attr_string = tokens //索引属性,字符串
索引配置
index test_index //index后面跟的是索引名称
sphinx使用配置文件从数据库读出数据之后,就将数据传递给Indexer程序,然后Indexer就会逐条读取记录,根据分词算法对每条记录建立索引,分词算法可以是一元分词/mmseg分词。
什么是增量索引
在实际应用中往往有这么一种情况,数据库数据很大,比如我们的歌曲表,如果我们每次都去更新整个表的索引,对系统得开销将非常大,显然这是不合适,这时我们会发现,每天我们需要更新的数据相比较而言较少,在这种情况下我们就需要使用“主索引+增量索引”的模式来实现实时更新的功能。
这个模式实现的基本原理是设置两个数据源和两个索引,为那些基本不更新的数据建立主索引,而对于那些新增的数据建立增量索引。主索引的更新频率我们可以设置的长一些(可以设置在每天的午夜进行更新),而增量索引的更新频率,我们可以将时间设置的很短(几分钟左右),这样在用户搜索的时候,我们可以同时查询这两个索引的数据。
php扩展下载
http://pecl.php.net/package/sphinx/1.3.3/windows
基本命令:
启动服务
searchd.exe
searchd.exe -c shpinx.conf
重建主索引 (xiaoheiban_log 这个索引定义为 index, 在shpinx.conf中)
indexer -c sphinx.conf xiaoheiban_log --rotate
建立增量索引 (xiaoheiban_log_delta 这个索引定义为 index, 在shpinx.conf中)
indexer -c sphinx.conf xiaoheiban_log_delta --rotate
增量合并(可以在启动searchd下直接合并增量)
indexer --merge xiaoheiban_log xiaoheiban_log_delta --rotate