到目前为止,我们一直在谈论的数据结构都是“线性结构”,不论是普通链表、栈还是队列,其中的每个元素(除了第一个和最后一个)都只有一个前驱(排在前面的元素)和一个后继(排在后面的元素),但是在(9)中,我们发现有的时候“线性结构”是不能满足我们的需求的,必然存在某些场景需要我们使用非线性的数据结构。而今天,我们要讨论的就是典型的非线性数据结构——树。
该从哪里开始谈起树是一个很麻烦的问题,我想了很久决定还是先给出树的“模样”,再说说树可能应用的场景,最后说说树的实现方法。
那么,树长什么“模样”呢?大概就长下面这个模样
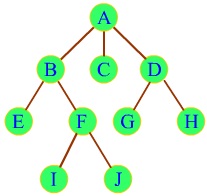
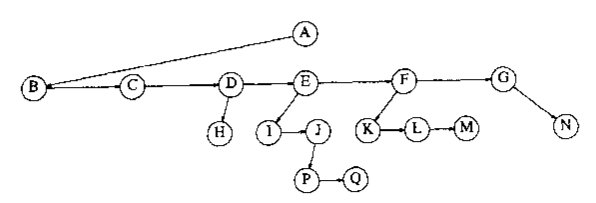
在数据结构树中,元素与元素之间的关系不再是“一前一后”,而是“一前多后”,即除去最顶上的元素(它没有前驱,就像线性表中的第一个元素,也没有前驱),每个元素都只能有一个前驱,但可以有多个后继或没有后继,比如上图中的EIJCGH元素都没有后继。
我相信不只是我一个人在学习树的时候有过这个疑惑:这种东西为什么叫“树”?
其实是这样的:你把数据结构树垂直翻转一下

你就会发现,它跟现实生活中的树有那么一点点相似:数据结构树中的每个元素就像现实树的每一个分叉点。so,大家叫这种“一前多后”的数据结构为“树”。当然,我个人认为你把它看作“树根”或者“族谱”会更像。(下图为三皇五帝族谱)

对于树的抽象概念就讲到这儿,接下来我们要说一说和树有关的一些术语,毕竟你和别人交流还是得用标准的东西来说……
对于树中的元素,我们称之为“结点”,每一个结点的前驱,我们称之为“父节点”,结点的后继,我们称之为“孩子”(是不是更觉得像族谱了?),没有父结点的那个结点我们称之为“根结点”或“根”(就是下图中的A,是不是很奇怪,怎么又叫“根”了?所以我说这种结构与其叫树不如叫树根或者族谱,可能是外国人不认族谱这种东西,而树根和根结点都叫root的话又怪怪的),而没有孩子的结点我们称之为“叶子”(如下图中的EIJCGH)。
除了上面的称呼术语外,我们还需要知道两个概念:深度和高度。
所谓深度就是从根开始逐层向下数的层数,直白的说,A深度为0,BCD深度为1,EFGH深度为2,IJ深度为3,整棵树的深度则取其中深度最大结点的深度,也就是3。
所谓高度,则是从深度最大的结点开始向上数的层数,直白的说,IJ高度为0,EFGH高度为1,BCD高度为2,A高度为3,整棵树的高度也就是3。
至于你问我为什么要从0开始数,嗯……类似于数组第一个元素的下标为0的道理,有时候从0开始数有利于编程实现,就酱。
哦,对了,还有一件事要说,就是什么是“子树”,所谓“子树”呢其实就是树中的树,比如我们抛开其它结点,单独看B和B的儿子、孙子们,你会发现它们也是一棵树,而它们这棵树从属于根为A的这棵树,所以根为B的这棵树就是根为A的树的“子树”。并且!就像线性表中可以只有一个元素一样,树也可以只有一个结点,所以叶子结点也可以是“一棵树”。不过我个人觉得过分追究这些东西很容易让人纠结于其中,所以我们对树的各种概念的介绍就到此打住吧。
接下来,我们要说说树这种数据结构可能用于什么场景。当然,如果你需要存储族谱的话,用树是肯定的╮(╯_╰)╭。但是除了族谱,我们身边还有一种常见的和计算机相关的事物是树型结构的。那就是——文件系统
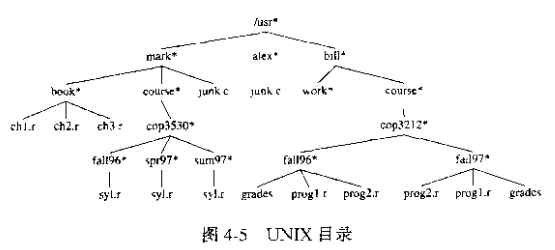
在文件系统中,一个文件夹下可以有多个文件夹或文件,而一个文件(夹)只属于一个文件夹,这是典型的树结构。
此外,我们之后还会讨论到一些特殊的树,它们又可以用于一些特殊的用途(主要是用于快速查找、搜索)。
好了,对于树的概念和可能应用就讲到这儿,接下来我们要谈谈如何实现一棵树的存储(准确的说,是在内存中的存储)。根据我们在链表中所学的知识,像这样随时可能增加、删除某个元素的数据结构,肯定是需要“链”的,也就是需要每个结点保存着“下一个结点”的地址。在线性的链表中,这一点非常容易实现,每个元素都使用结构体,令结构体中保存元素的数据和一个指向本结构体类型的指针。但是在树中,这种做法存在一个问题:结构体中该有多少个指针呢?
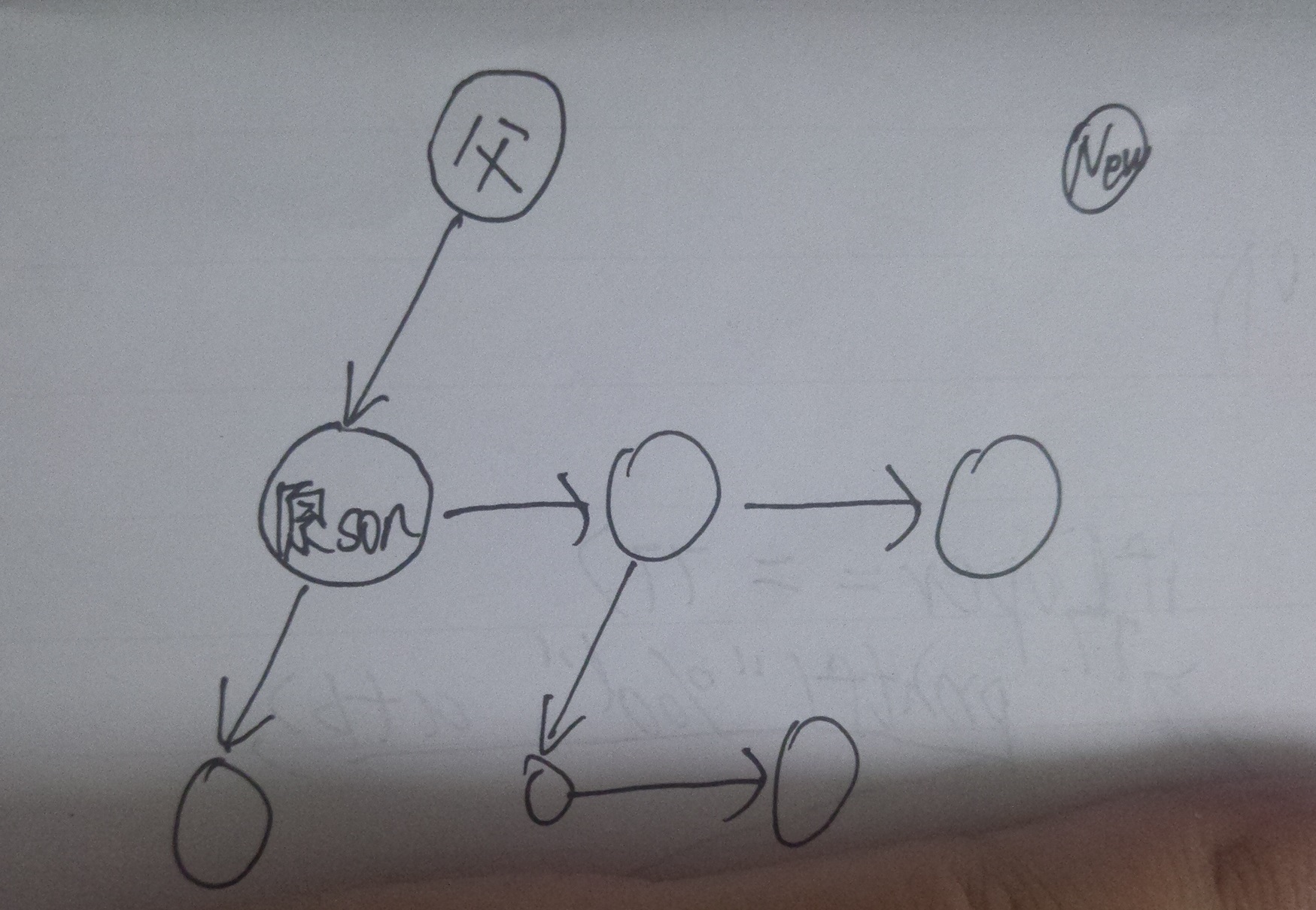
这个问题乍一看好像很难解,因为你不知道一个结点到底会有几个孩子,可能没有孩子,也可能有成百上千个孩子。但其实我们可以换个思路,稍微借鉴一下链表的思想,那就是:某个结点的孩子们可以看成是一个线性表,结点只需要知道第一个孩子在哪即可,第一个孩子知道第二个孩子在哪,第二个孩子知道第三个孩子在哪,以此类推。这样一来,一个结点就只需要两个指针,一个指向自己的第一个孩子,另一个指向自己的下一个“兄弟”。
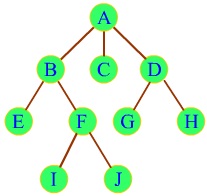
如上图,A有6个孩子BCDEFG,但它只通过son指针保存了B的地址,其它5个孩子则通过兄弟间的brother指针来获得。
至此,树中的结点应该如何定义,我们已经知道了,如下(我们假设我们制作一个简单的模拟文件管理器,详细代码会在最后给出):
typedef struct treeNode{ bool IsFile; //IsFile用于判断本结点是文件还是文件夹,如果是文件则不支持向其插入孩子 char name[NAMESIZE]; //用于存储结点(文件(夹))名 struct treeNode *son; struct treeNode *brother; }treeNode; typedef treeNode* Tree;
有了树的结点定义后,我们接下来要讨论讨论可以对树做的操作,首先当然是初始化。
初始化的思路很简单,通过malloc分配一个结点的空间并初始化,然后将该结点保存于主程序中的“根指针”
//初始化树t,使其为文件夹且名为root void Initialize(Tree *t) { *t=(Tree)malloc(sizeof(treeNode)); (*t)->IsFile=false; strcpy_s((*t)->name,NAMESIZE,"root"); (*t)->son=NULL; (*t)->brother=NULL; }
插入的思路很简单:
为新结点分配空间并初始化,然后找到要插入该结点的父结点
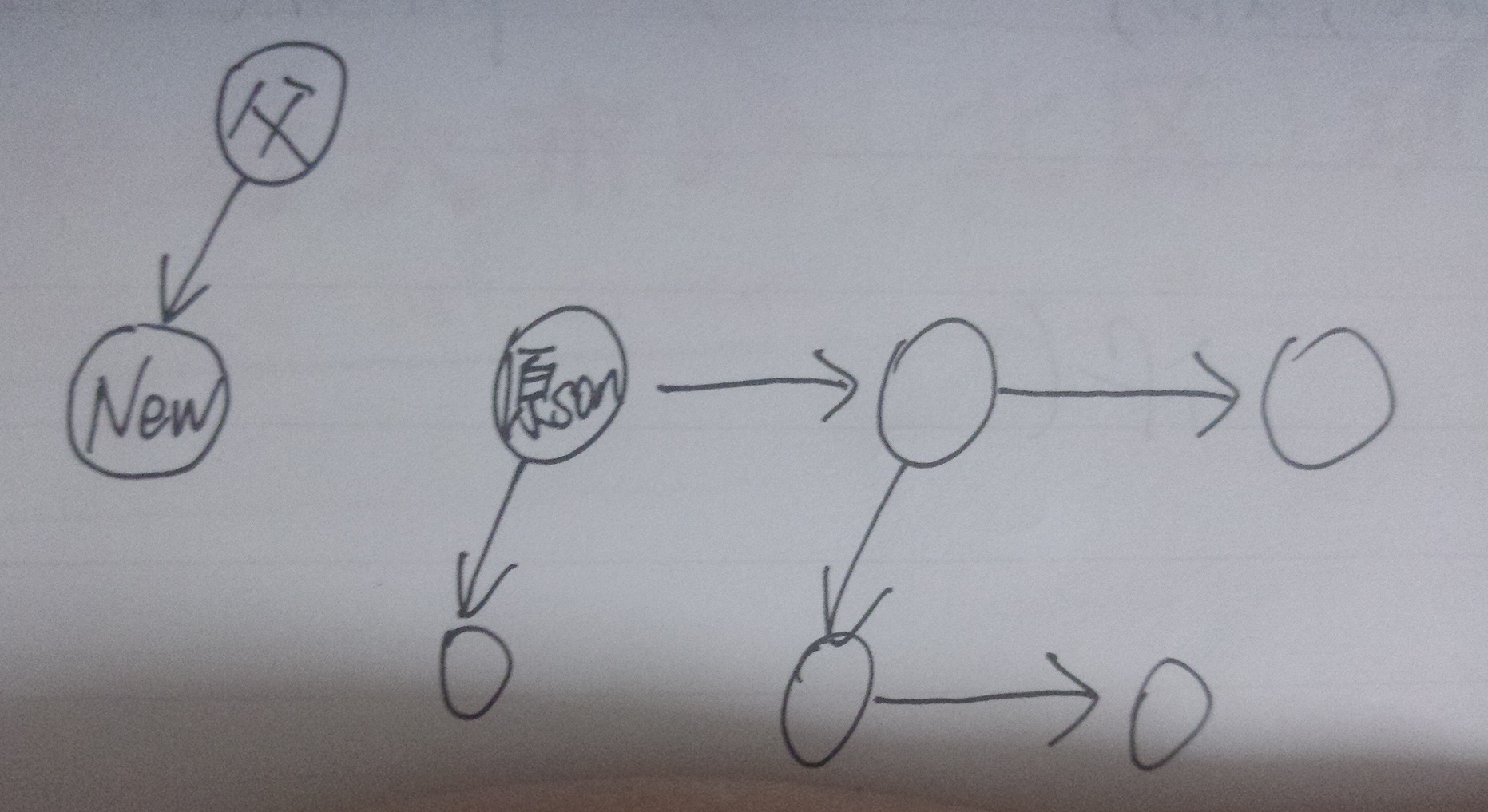
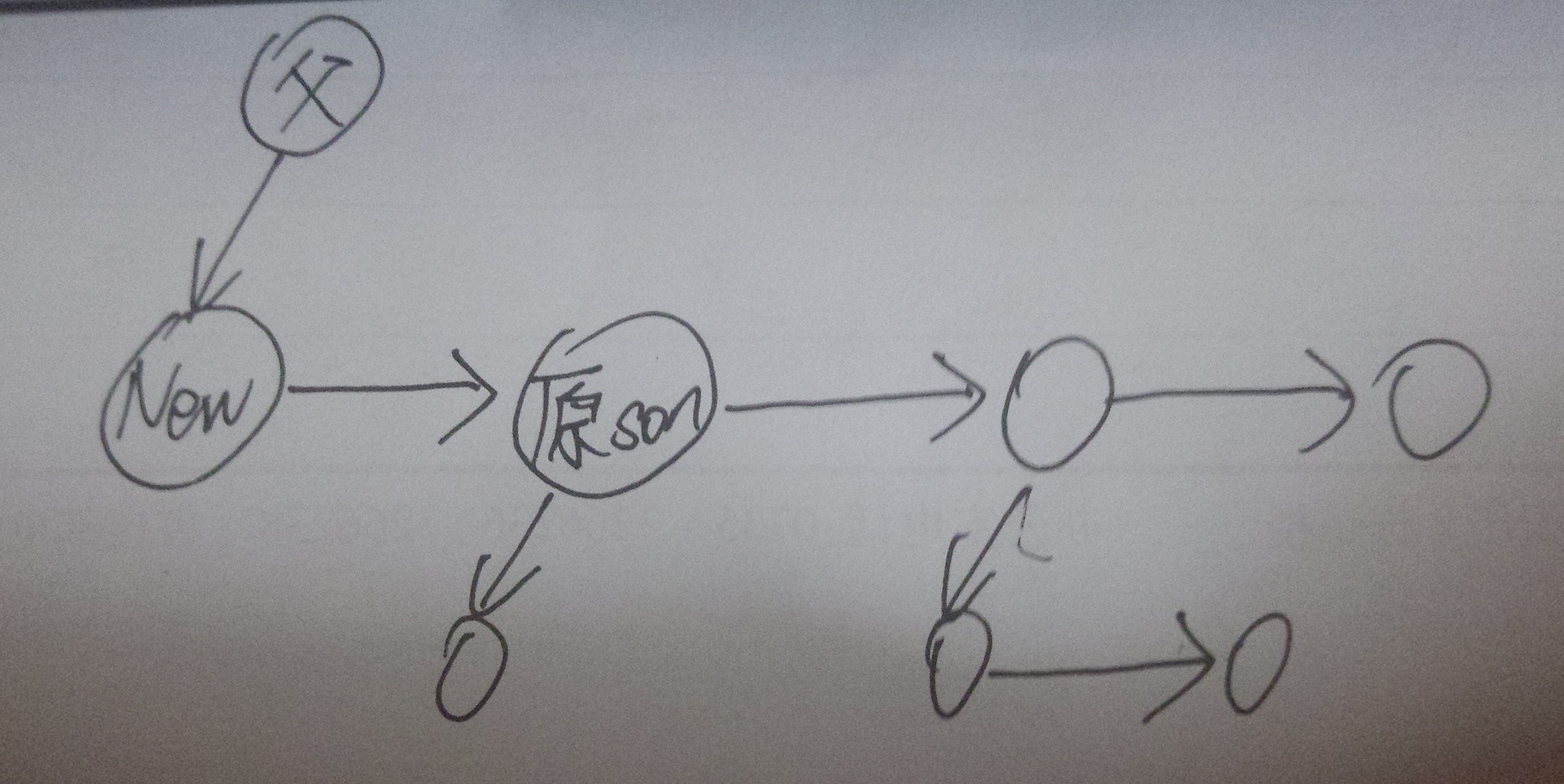
若父结点的son==NULL,则直接令父节点的son指向新分配的结点
若父结点的son!=NULL,则暂存父结点的son,令父节点的son指向新结点后,再令新结点的brother指向暂存的那个son。大致如下图。
插入的代码较长,所以不给出,因为“如何找到目标父结点”需要视情况而定,可以直接令使用者输入完整路径,也可以从根节点起,逐层令使用者选择文件夹,直至使用者到达目标文件夹为止。
具体的插入代码将会在最后给出。
知道了如何初始化树,如何向树中插入结点后,我们接着学习另一种操作了,叫做“遍历”,其意思就是“走遍整棵树中的所有结点并进行相应操作,如输出结点信息”。对于线性表来说,遍历是一个很简单的操作,我们只要从第一个元素开始一直向后操作就可以,但是对于树来说,遍历的操作变得有点“复杂”。
首先我们假设遍历时对每个结点的操作就是输出结点信息,接下来我们看看对于树,可以如何遍历。
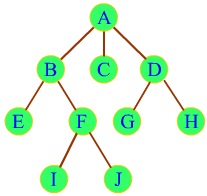
对于上图中的树,我们可以“直观地”选择“逐层遍历”,先输出同一深度的所有结点,然后再输出深度+1的所有结点,即遍历顺序为ABCDEFGHIJ。
但是逐层遍历有两个问题,第一个问题是:这种顺序对于文件系统来说,不能反映出文件(夹)间的从属关系。
假设根文件夹为root,其下有两个文件夹QingHua和Nchu,QingHua下有文件xxx.exe,Nchu下有文件XieWei.666,对于每个结点,我们根据其深度打印 的个数(越深的结点打印越多 ),然后打印其名字
那么显然的,我们希望遍历后输出的样子长这样,因为这样可以反映出文件(夹)间的从属关系

可是如果我们按照“逐层遍历”,我们输出的会是这样
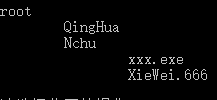
如果采用逐层遍历,那么我们就没能“反映出结点间的从属关系”。
可能你会认为,对于不需要反映结点间从属关系的情况来说,逐层遍历也没有问题。但是,逐层遍历还有一个更严重的问题,那就是:代码更不好写╮(╯_╰)╭(并不是说逐层遍历的代码无法给出,而是更不好写)
所以,我们对于树,往往采用一种叫做“先序遍历”的遍历方法。什么是“先序遍历”呢?关键词就是“先序”,所谓先序,意思就是“对于每一个结点,我们都按照先处理其本身,再处理其孩子的顺序执行”,这个“先”就是指“结点的处理先于其孩子”。
上面的话可能有一点绕口,什么叫结点的处理先于其孩子?逐层遍历时我们不也是先处理了A,再处理的BCD吗?如果你有这样的困惑,请注意上面的一小段话:“对于每一个结点”。在逐层遍历中,我们的确先处理了A再处理A的孩子,但是对于B呢?C呢?我们都没有严格的按照处理完结点就去处理其孩子。
那么,先序遍历的代码好写吗?当然好写,因为每一个结点的处理方法都是一样的,所以递归可以很好地运用在先序遍历中:
//先序输出树 //调用者将参数layer设为0,该参数即当前结点在树中的深度 void PrintPreOrder(Tree t,int layer) { //递归一定要有基准情形,这在递归简论博文中提到过 if(t==NULL) return; //按照先序遍历的要求,我们先处理当前结点 for(int i=0;i<layer;++i) //根据当前结点在树中的层决定打印多少个制表符 putchar(' '); printf("%s ",t->name); //然后我们对当前结点的孩子们再逐一进行先序遍历 Tree temp=t->son; while(temp!=NULL) { PrintPreOrder(temp,layer+1); temp=temp->brother; } }
但是先序遍历也不能适应所有需要遍历的情况,比如说当我们想要统计文件系统的总大小时。一个文件夹的大小等于其中所有文件(夹)的大小之和,而我们如果不“先去看看子文件(夹)们的大小”,又如何统计出它们总共的大小呢?
这个时候,我们就需要和先序遍历相反的遍历方法了,那就是“后序遍历”,其名字的解释与先序遍历相似,就是“对于每一个结点,我们都按照先处理其孩子,再处理其本身的顺序执行”。这样一来,我们就能在处理结点本身之前,获取到其下所有孩子们的信息。而且先序遍历的代码转换为后序遍历也比较简单,只需要将对当前结点的操作转移到对孩子们的操作之后就可以了。(下面的代码中我们假设结点存在size)
int CountSize(Tree t) { int total = 0; //如果t为NULL则返回total,即0,此处作为递归基准情形 if (t == NULL) return total; //如果t不为NULL则对其下每个孩子进行CountSize,并将返回值加到total上 Tree son = t->son; while (son != NULL) { total += CountSize(son); son = son->brother; } //此时total已经为t下所有孩子的大小之和,只需要让total加上t本身大小即可得出整个t(假设为文件夹)的大小 total += t->size; return total; }
类似的,后序遍历也可以应用于释放树的操作中
//释放树中的每一个结点 void FreeTree(Tree t) { if (t == NULL) return; Tree temp = NULL; Tree t_son = t->son; while (t_son != NULL) { temp = t_son->brother; FreeTree(t_son); t_son = temp; } free(t); }
当然,释放树也可以采用先序遍历的方法实现(可以稍微比较与后序遍历实现的差异,可以看出两者差异基本上就只是对当前结点的处理放在孩子们的前面还是后面的区别)
//释放树中的每一个结点 void FreeTree(Tree t) { if (t == NULL) return; Tree t_son = t->son; Tree temp = NULL; free(t); while (t_son != NULL) { temp = t_son->brother; FreeTree(t_son); t_son = temp; } }
删除某个结点的操作就比较简单了,至少对于我们的模拟文件系统来说是,因为删除一个结点我们默认将其下所有结点也一并删除,所以只需要像插入操作一样,找到要删除的结点,然后对该结点进行FreeTree操作即可,当然,指向被删除结点的指针(可能是父结点的son,也可能是兄弟结点的brother)也需要相应地改动,但是都不难,就不做具体介绍了。
树的简介就到这儿,接下来是给出模拟文件管理器的代码:
https://github.com/nchuXieWei/BlogUse------AnalogFileSystem
在上面的模拟文件管理器中,使用了一点本文没有讨论的技术——将树存储到文件中。
这个技术其实并不难,关键点就是如何将非线性的树存储为线性表,并且令表中的每个结点均保存有father所在的表中位置(下标)。如果想要了解这个技术如何实现,请查看XWTree.cpp中的store(),storeToArray()和Load()